腾讯开源 OpenSearch-VL:把多模态搜索智能体的训练配方摊开了

腾讯混元联合 UCLA、港中文发布 OpenSearch-VL,从数据管道到训练算法全链路开源,30B 模型基线从 47.8 拉到 61.6,直指商业闭源系统的复现难题。
5 月 6 日,腾讯混元把一份叫 OpenSearch-VL 的训练方案丢上了 arXiv,合作方是加州大学洛杉矶分校和香港中文大学。这东西不是一个模型权重那么简单,而是从数据构造、工具环境到强化学习算法的完整开源配方,目标很直接:解决多模态搜索智能体训练里最卡脖子的那块——高质量数据。
一天后的今天,相关代码和数据集开始陆续放出。对于一直盯着 GPT-4V 搜索能力、Gemini Deep Research 眼馋的开发者来说,这大概是过去半年里最值得细读的一份技术报告。
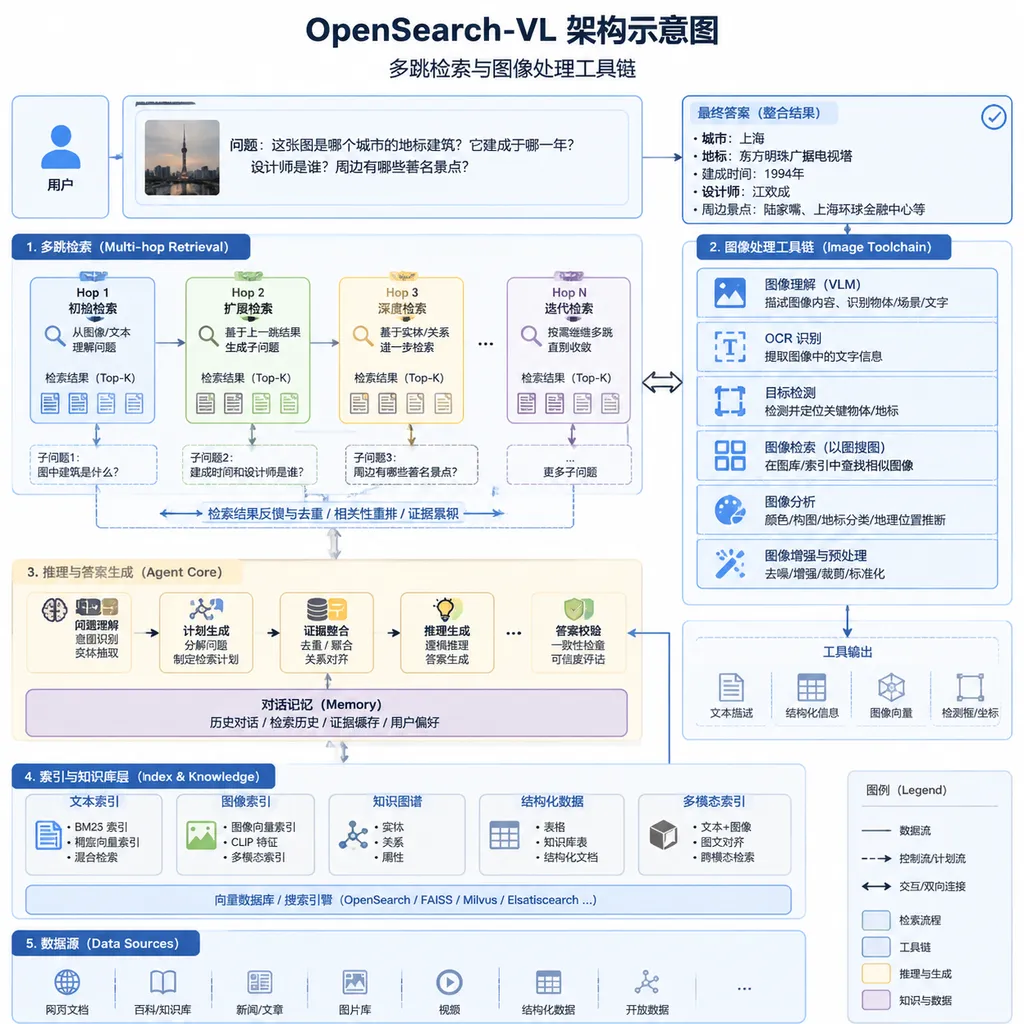
为什么是现在,为什么是这件事
先说清楚多模态搜索智能体是什么。简单讲,就是给它一张图加一句问题,它得会看图、会搜索、会调用 OCR 或者裁剪工具处理图像、还得在多个信息源之间跳来跳去验证证据,最后给出答案。这类场景在产品形态上对应的就是 Perplexity 的视觉搜索、ChatGPT 的「看图提问+联网」、Google 的 Deep Research 这一类。
问题在于,这些能打的系统全是闭源的。商业公司的数据怎么来、工具调用轨迹长什么样、强化学习的奖励怎么设计,外界基本看不到。学术界想复现?拿不到数据就是死结。想在这个方向做系统性研究?连个对标的开源基线都没有。
这是 OpenSearch-VL 这份工作的出发点——研究团队在报告里写得相当直白:目前阻碍前沿多模态搜索智能体进化的最大瓶颈,就是高质量的训练数据。他们要把商业公司藏着的那部分摊开。
核心创新:维基百科不是用来查的,是用来「造题」的
整个方案最巧妙的一环,在数据管道。
传统做法要训一个搜索智能体,通常是拿现成的视觉问答数据集,比如 OK-VQA 之类,然后让模型学着调搜索工具。但这里有个隐藏坑:很多问题其实一步检索就能搞定,智能体会学到「懒惰」的捷径——看到图直接搜图里最显眼的东西,一次命中就收工。这样训出来的模型遇到真正需要多跳推理的问题就露馅了。
OpenSearch-VL 的解法是反着来:主动构造那些必须多跳才能解的题。
具体操作上,团队利用维基百科的超链接图谱,做多跳实体路径采样。举个例子,从一张埃菲尔铁塔的照片出发,顺着维基百科的链接走到设计师 Gustave Eiffel,再跳到他参与设计的自由女神像内部结构,再到某个具体的铆接工艺。这样一条路径下来,就形成了一个需要至少三跳搜索才能答对的问题。
光有路径还不够。团队接着做了两件事来堵住捷径:
- 中间实体模糊重写:路径上的实体不直接点名,而是用描述性语言包装。「埃菲尔设计师」可能被改写成「那位因为一座塔而闻名、但也参与了某座美国象征性雕像设计的法国工程师」。
- 锚点实体锚定至源图像:起点实体只通过图像呈现,不在文本里直接暴露名字。智能体必须先看图识别,才能启动后续的搜索链。
这两招下来,单步检索的捷径基本被堵死。数据管道最终产出 SearchVL-SFT-36k 这个数据集,平均每条轨迹包含 6.3 次工具调用——这个数字本身就说明问题,比市面上大部分视觉问答基准的工具使用深度高出一个量级。
工具环境:让智能体先学会「看清楚」再去搜
另一个值得说的设计,是工具环境。
大部分现有的搜索智能体,工具箱里就俩东西:文本搜索和图像搜索。OpenSearch-VL 把范围大幅扩展,加入了 OCR、图像裁剪、锐化、超分辨率、透视校正等一系列视觉处理工具。
这背后的思路挺符合直觉:真实场景里用户丢过来的图往往是糊的、斜的、角落里藏着关键文字的。如果智能体不能先把图像处理干净就一头扎进搜索,基本是白费力气。
为了强化这种「边思考边处理图像」的行为,团队还做了一个细节:随机选 10% 的训练数据,故意做模糊、下采样之类的降质处理,然后配对相应的增强工具。这等于在告诉模型——遇到烂图别急着搜,先修一修。
这种「主动感知 + 知识获取」融合的工具设计,在开源方案里算是第一次被系统性地提出来。对比下来,很多学术项目里的所谓多模态智能体,工具调用其实还停留在「图像搜索 API 的壳子」阶段。
训练方法:SFT 打底 + RL 调优
训练流程是两段式的经典组合,但里面的工程细节值得看。
第一阶段是监督微调,用的就是前面说的 SearchVL-SFT-36k。这一步主要是让模型学会基本的工具调用格式、多轮推理的节奏。
第二阶段上强化学习。奖励函数的设计相对朴素——答案正确性 + 工具使用效率,但团队在 rollout 的稳定性上下了功夫。多模态长轨迹的 RL 训练非常吃资源,一次 rollout 动辄几十次工具调用、上万 token,训练崩溃在这个领域是家常便饭。
最终交出的代表性模型叫 OpenSearch-VL-30B-A3B,基于混元 MoE 架构,激活参数 3B。这个尺寸在消费级硬件上跑推理是可行的,但全量训练仍然需要比较像样的集群。
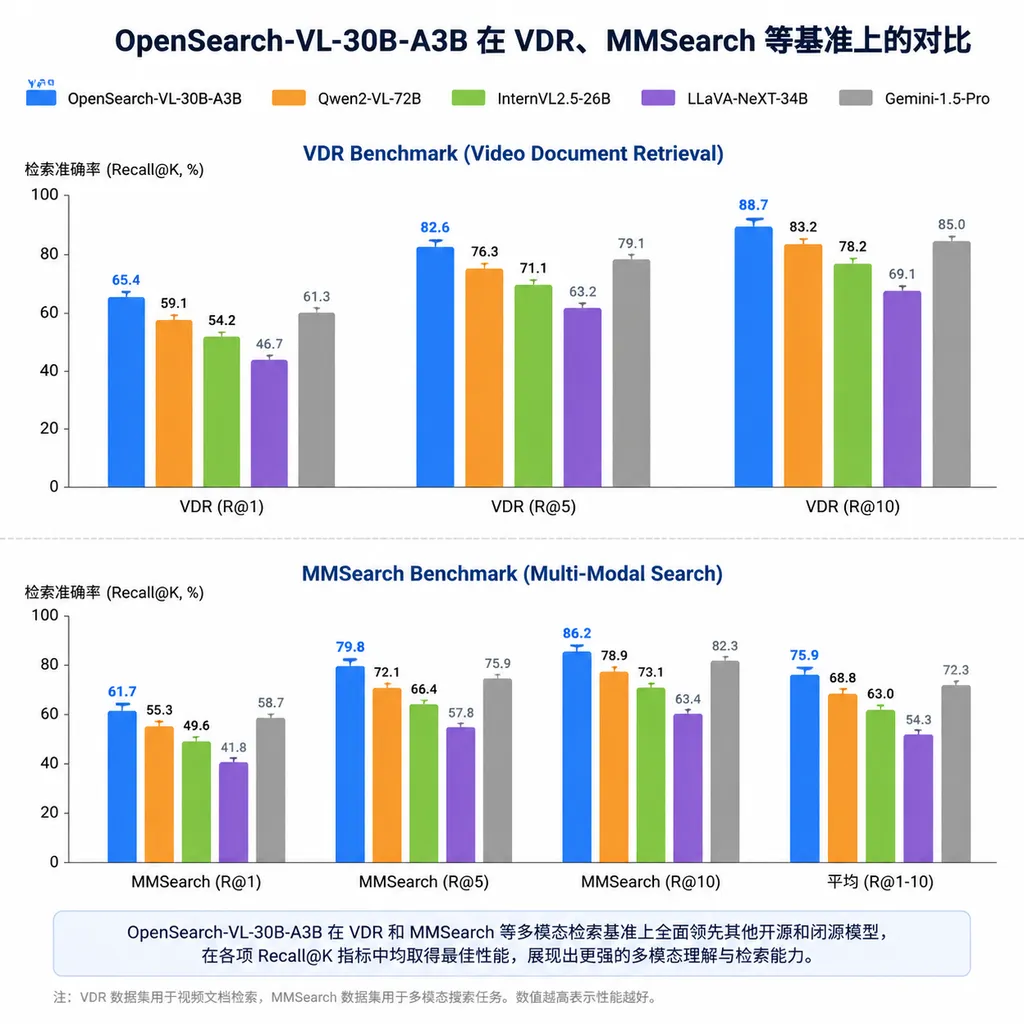
成绩单:基线 47.8,跑到 61.6
数字最能说明问题。
在 VDR、MMSearch 等多个多模态搜索基准上,OpenSearch-VL-30B-A3B 把基线平均得分从 47.8 推到了 61.6,提升接近 14 个点。在开源模型的横向对比里,这个增幅相当可观。
消融实验的部分其实比主结果更有信息量:
- 移除源锚点锚定:平均得分下降 8.2 点
- 移除模糊重写:平均得分下降约 9.5 点
- 移除分阶段过滤:平均得分下降 11.5 点
三个核心组件的贡献都在 8 到 12 个点的量级,说明整个数据管道不是靠某个单点取巧,而是多个设计互相咬合。这种结构性的增益,比单纯堆参数堆数据得来的分数要更可信。
这事儿放在行业里看
把 OpenSearch-VL 放到最近半年的行业脉络里,位置挺微妙。
一方面,Agent 方向的开源进展在加速。从年初 DeepSeek 把 R1 的 RL 训练细节公开,到 Qwen 系列在工具调用上的持续投入,再到现在混元把多模态搜索的完整配方摊开,中国团队在「让高级能力可复现」这件事上越来越主动。商业公司不愿意说的部分,学术合作在逐步补齐。
另一方面,多模态搜索这个赛道商业价值很明确。企业内的知识库检索、电商的拍照搜索、科研的文献+图表联合检索,都是能直接变现的场景。一个开源的、可商用的基线配方出来,接下来大概率会看到一批垂直领域的微调版本冒出来。
从技术上我个人的判断是:OpenSearch-VL 的真正贡献不在那个 30B 模型本身——模型权重这种东西迭代很快,半年后可能就过时了。值钱的是那套数据构造方法论。维基百科超链接图谱做多跳采样 + 模糊重写抑制捷径,这个组合拳很可能成为后续多跳推理类智能体训练的标准范式,不止搜索场景。
有一个点值得泼点冷水:SearchVL-SFT-36k 的规模按今天的标准不算大,36k 条轨迹 × 平均 6.3 次工具调用,总 token 量可能就是几亿的级别。对于训一个前沿模型来说偏紧。不过团队的重点显然是方法论的演示而非规模的堆叠,后续社区跟进扩数据是完全可行的。
开发者可以怎么用
对于想在这套方案上做事情的开发者,几个方向比较实际:
- 直接拿 SearchVL-SFT-36k 跑微调:如果你手上已经有一个多模态基座(比如 Qwen2.5-VL 或者 InternVL),加上这批数据做 SFT,搜索能力应该能有可观提升。
- 复用数据管道造垂直领域数据:维基百科的多跳采样逻辑,换成你自己的知识图谱或者产品文档链接结构,完全可以复刻出行业版本的训练数据。
- 工具环境接入自己的 Agent 框架:OCR、超分、透视校正这套工具组合本身可以单独拎出来,接到现有的 LangChain、LlamaIndex 项目里,给视觉输入加一层预处理能力。
顺带一提,腾讯混元系列模型在 OpenAI Hub 上是支持直接调用的,兼容 OpenAI 格式,想先用闭源版本做原型验证再考虑自训的团队可以少折腾一步环境。
写在最后
OpenSearch-VL 不是那种让人眼前一亮的新产品,它的意义更像是把一块一直盖着布的地方掀开给大家看。商业公司做了两年的工程活儿,一份开源报告把方法论部分基本讲透了。
接下来的半年,这个方向应该会很热闹。复现、扩展、领域迁移,每条路都有人走。对于还在犹豫要不要进入多模态 Agent 赛道的团队来说,至少现在的起点比半年前要高得多了。
参考来源
- 腾讯开源 OpenSearch-VL,突破多模态搜索 AI 智能体训练瓶颈 - IT之家:IT之家 5 月 7 日关于 OpenSearch-VL 发布的首发报道,包含技术细节与基准成绩
- 约500篇大语言模型(LLM)论文调研整理 - 知乎专栏:LLM 领域论文综述,涵盖搜索智能体与 RL 训练相关方向
- GitHub Trending 抓取项目:追踪 AI 及多模态模型相关开源项目动态的参考仓库
