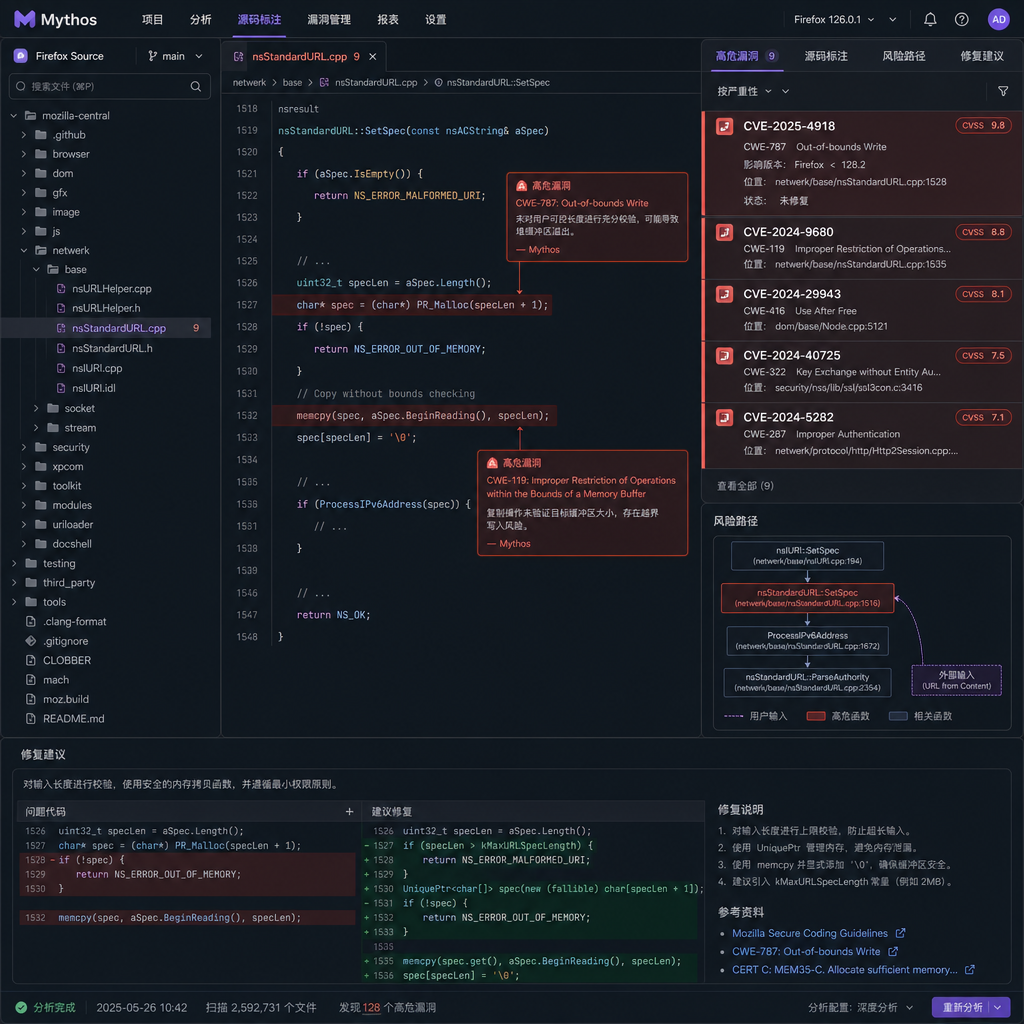
Anthropic Mythos 上线:Firefox 一次修了 271 个漏洞,AI 安全审计正在改写规则
5 月 7 日,TechCrunch 披露了一条让安全圈集体侧目的消息:Mozilla 在最新发布的 Firefox 150 中,一口气合并了 271 个安全漏洞修复,而这些漏洞绝大部分不是社区报上来的,也不是内部 fuzzing 跑出来的——它们是 Anthropic 一款名为 Mythos 的新模型在源码审计中找出来的。
作为对比,三个月前的 Firefox 148 版本,Mozilla 用的是 Claude Opus 4.6,跑同样的审计流程,结果是 22 个。一个版本周期,数字翻了 12 倍。这不是常规迭代该有的曲线。
Mythos 是什么:一个被「专门训练去读坏代码」的 Claude
Anthropic 这次没走通用模型升级的路线。Mythos 目前还挂着 Preview 标签,没有公开 API,仅向少数安全合作伙伴开放早期访问,Mozilla 是首批。从公开信息和 Mozilla 安全团队的描述来看,Mythos 的定位非常明确——面向代码安全审计的专用模型,而不是又一个全能选手。
它和 Claude 主线模型的差异,大致可以拆成三层:
- 超长上下文 + 跨文件推理。浏览器内核这种代码库,单看一个函数永远找不到漏洞,真正的 use-after-free、TOCTOU、整数溢出,往往跨越渲染、IPC、JS 引擎三个模块。Mythos 显然在长链路调用追踪上做了专门优化。
- 漏洞模式的先验知识。CVE 数据库、Mozilla 自己历年的 bugzilla、Chromium 的安全公告,这些数据对通用模型只是语料,对 Mythos 是任务样本。它知道什么样的指针生命周期「看起来不对」。
- 低误报权衡。Mozilla 团队透露,Mythos 报上来的问题,复现率和可利用性评估通过率远高于以往用通用 LLM 跑出来的结果。这是审计模型最关键的指标——不是找得多,是找得准。
换句话说,它不是 Claude 4.x 加了个 system prompt,而是 Anthropic 第一次把「安全审计」当成一个独立的产品方向来做。
271 这个数字到底意味着什么
做过浏览器安全的人会知道,271 是一个相当夸张的数字。Firefox 一个稳定版的安全公告通常在二三十条量级,里面包含社区报告、内部审计、模糊测试、第三方研究员四个来源。一次性新增 271 个由单一 AI 渠道贡献的修复,相当于把过去一年外部研究员的产出压缩进了一个版本周期。
更关键的是漏洞质量。Mozilla 在博客里写得比较克制,但 TechCrunch 引述的内部说法是「a wealth of high-severity bugs」——大量高危。低危的代码味道、风格问题不是没有,但被排除在 271 之外。这个口径下,Mythos 已经接近一个中等水平人类安全研究员一年的产出了,而它跑完整个 Firefox 代码库可能只用了几天。

值得一提的是,Reddit 上 r/firefox 的讨论里有用户提了一个很实际的担忧:Mythos 没有向公众开放,意味着这批漏洞是 Mozilla 内部团队拿着内部权限跑的,不存在 OpenSSL 早年遭遇的「社区低质量 AI 报告轰炸」问题。Anthropic 显然吸取了 GitHub 上一波 AI 自动化漏洞悬赏滥用的教训,先 B 端定向合作,再考虑普及。
为什么是 Anthropic,为什么是现在
2025 年下半年开始,「代码 + 安全」是各家大模型公司明里暗里押注的方向。OpenAI 在 GPT 系列里强化了 secure code review 能力,Google 的 Big Sleep 项目去年也公开过用 Gemini 在 SQLite 中找到 0day 的案例。但把它做成一个有独立品牌的产品,Anthropic 是第一家。
这背后的逻辑不难推:
- 通用模型卷不动了。文本、推理、Agent 这些维度上,头部模型差距在收敛。垂直能力反而是下一个能拉开身位的地方,而安全审计是少数能直接换算成「企业付费意愿」的硬场景。
- 代码审计是 AI 比人强的少数任务之一。它需要的是耐心、覆盖度、模式识别,而不是创造力。人类研究员一天看不了几千行代码,模型可以。
- 责任边界清晰。漏洞找到了就是找到了,复现得了就是真的,不存在「幻觉」难判定的问题——这是 Anthropic 一向看重的可评估性。
Mozilla 这边的算盘也很清楚。Firefox 市场份额一直在掉,但安全口碑是它对抗 Chromium 系最后的护城河之一。能用 AI 把高危漏洞密度压下来,比加任何新功能都划算。
对开发者和安全行业的实际影响
短期看,Mythos 不会立刻改变普通开发者的工作流——它没开放,你也调不到。但它释放的信号是明确的:
- CI 里集成 AI 安全审计会成为标配。哪怕用不上 Mythos,Claude、GPT、Gemini 的现有能力跑增量代码已经能覆盖一大半常见问题。习惯还没养成的团队,今年内会被推着往前走。
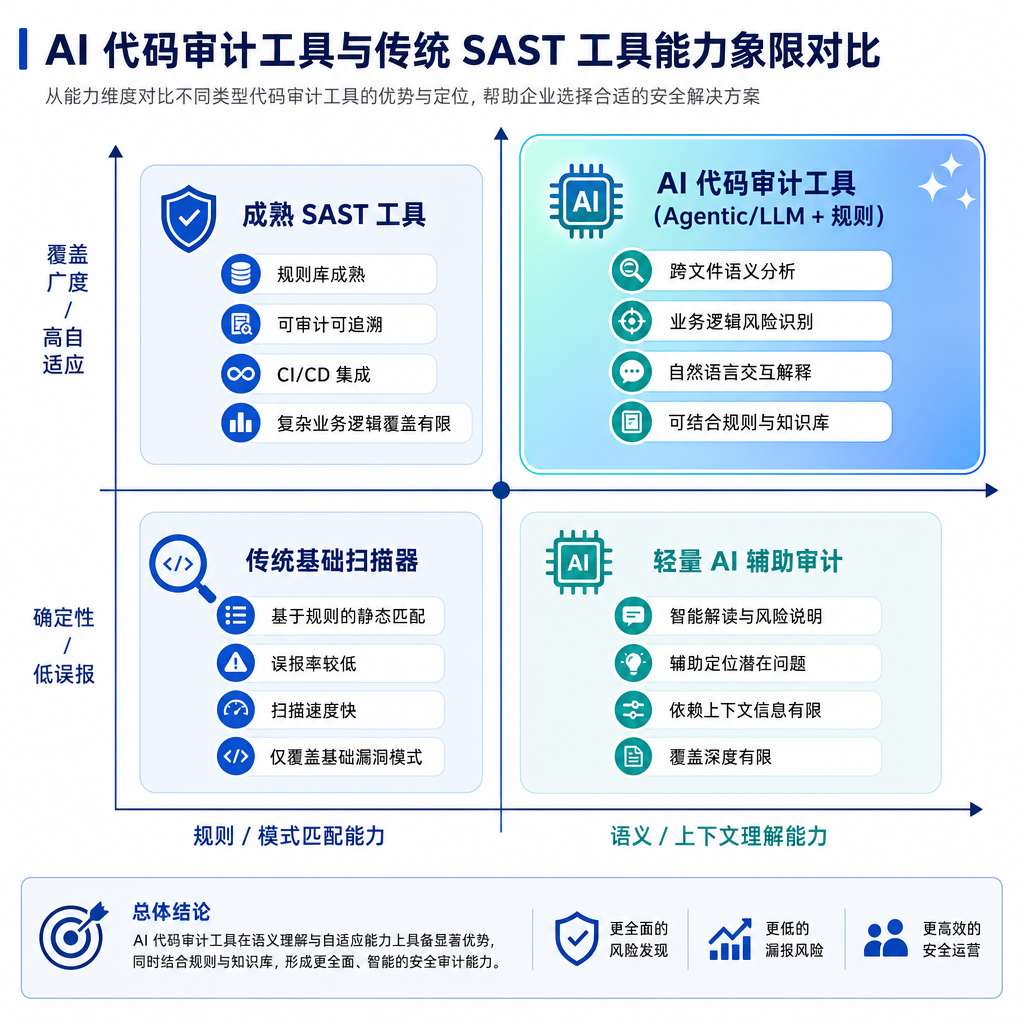
- 传统 SAST 工具的位置会被挤压。Coverity、Fortify 这些规则引擎驱动的工具,在跨文件、跨语义的漏洞上一直是软肋,而这恰恰是 LLM 的强项。
- 赏金猎人的生态会被重构。当一个模型一周能产出 271 个高危,人类研究员的价值会向「Mythos 找不到的那部分」收敛——也就是逻辑漏洞、协议层问题、需要业务上下文的攻击链。低垂果实正在被批量收割。
还没解决的问题
Mythos 不是银弹,几个明显的待解项:
- 闭源审计。Mozilla 是开源项目,Anthropic 可以光明正大地跑全代码库。换成闭源商业代码,模型权重和代码隔离怎么做、审计日志怎么留,是企业客户真正会问的问题。
- 二进制和反编译场景。目前披露的能力都集中在源码审计,固件、驱动、被混淆过的代码还是另一个赛道。
- 滥用风险。Anthropic 现在卡得很紧,但这种能力一旦扩散,攻击方拿到同等工具去扫开源依赖找 0day,是迟早的事。这场军备竞赛,防守方需要永远跑在前面半步。
写在最后
2026 年到现在,模型层面真正让人记住的发布不算多,Mythos 算一个。它没刷榜、没炫推理,就靠一个浏览器版本里 271 个修复,把「专用模型」这条路的可行性证明给了所有人看。Anthropic 暂未公布 Mythos 的开放时间表和定价,OpenAI Hub 也会在其正式开放 API 后第一时间跟进接入,方便国内开发者通过统一 Key 调用。
下一个被 AI 重写的安全战场会是哪个?Linux 内核、Kubernetes、还是 OpenSSL?答案大概率不会让我们等太久。
参考来源
- Reddit r/firefox 社区讨论:Mozilla 使用 Mythos 修复 Firefox 漏洞 — 开发者社区对 Mythos 未公开访问、漏洞披露流程的一手讨论