OpenAI 把语音智能体推进了生产环境:gpt-realtime 与 Realtime API 全面开放
5 月 7 日,OpenAI 一口气把 Realtime API 从公测推进到 GA,并发布了迄今最强的语音对语音模型 gpt-realtime。这次更新的关键词只有一个:生产可用。MCP 远程服务器、图像输入、SIP 电话呼叫一并塞进 API,价格相较 gpt-4o-realtime-preview 直接砍掉 20%。
对做语音智能体的开发者来说,这是去年 10 月 Realtime API 公测以来最实质的一次升级——以前是能玩,现在是能上线。
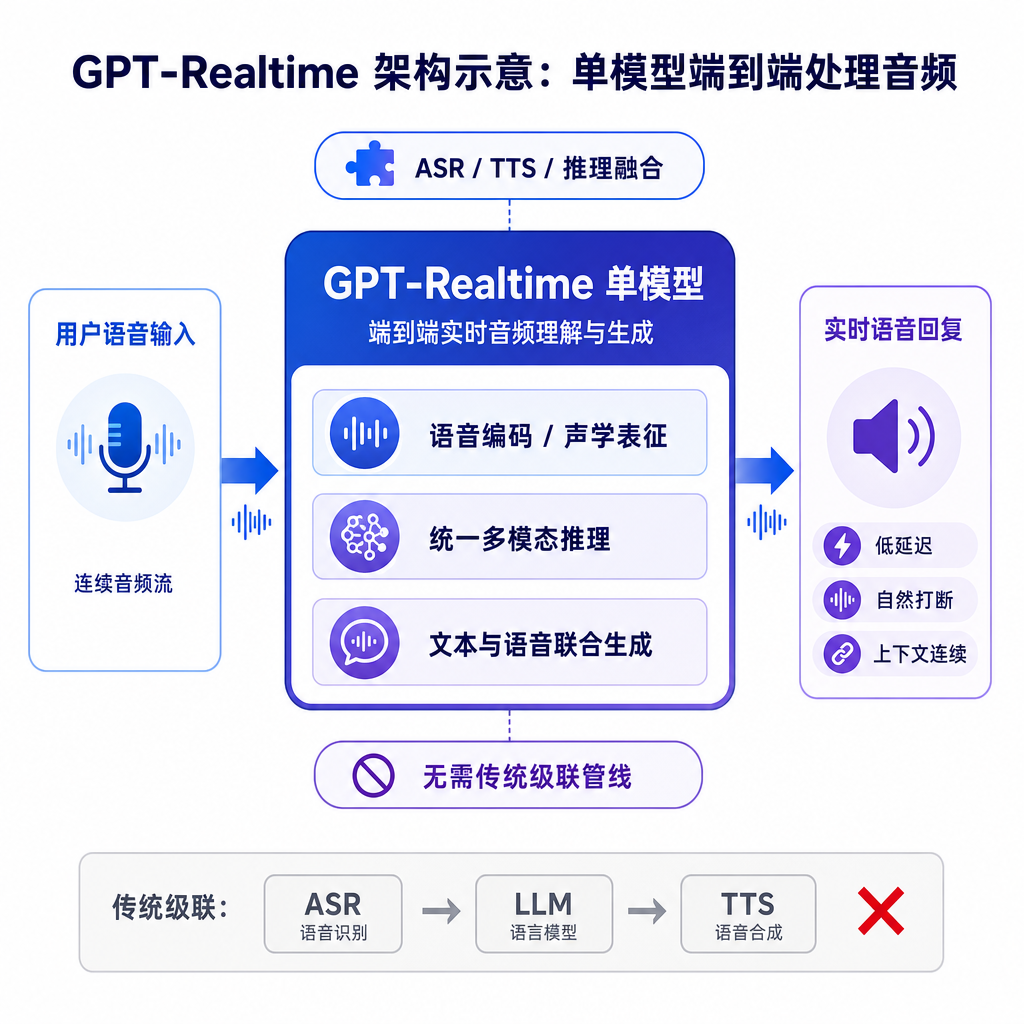
不再是 STT + LLM + TTS 的三明治
传统语音智能体的做法是把语音转文本、文本大模型、文本转语音三段串起来。问题非常直接:延迟高、情感丢失、停顿和笑声这种非语言信号全被中间环节抹平。OpenAI 这套 Realtime API 走的是另一条路——单一模型直接吃音频、直接吐音频,端到端。
好处是显而易见的:几百毫秒的延迟差距就能决定一段对话是「自然交流」还是「机器人客服」。gpt-realtime 在这条路径上把质量推到了一个新高度。按官方公布的数据:
- Big Bench Audio(推理):准确率 82.8%,对比 2024 年 12 月版本的 65.6%
- MultiChallenge 音频基准(指令遵循):30.5%,前代 20.6%
- ComplexFuncBench(函数调用):66.5%,前代 49.7%
指令遵循那一项的提升尤其值得说道。语音智能体最难搞的不是「会不会说」,而是「该说的一字不漏、不该说的一句不多」——比如客服场景里那段法务免责声明,必须逐字朗读;比如确认订单号、车架号时,字母数字不能错。OpenAI 在博客里专门强调了这一点,新模型对系统消息和开发者指令的解读更细,连「敏捷而专业」「友善而富有同情心」这种语调指示都能稳定执行。
还新增了 Cedar 和 Marin 两个声音,仅在 Realtime API 中提供。
三个真正改变工程落地的新能力
1. 远程 MCP 服务器
这是这次更新里我认为最重要的一个变化。把一个 MCP 服务器 URL 塞进会话配置,API 自动接管工具调用,不用再手写一堆 function calling 的胶水代码。
POST /v1/realtime/client_secrets
{
"session": {
"type": "realtime",
"tools": [
{
"type": "mcp",
"server_label": "stripe",
"server_url": "https://mcp.stripe.com",
"authorization": "{access_token}",
"require_approval": "never"
}
]
}
}
意味着语音智能体的能力扩展从「写代码集成」变成了「换个 URL」。要给客服机器人加退款能力?指向 Stripe 的 MCP;要让它能查物流?换一个 server_url。这种解耦对中后台开发的效率影响不小。
2. 图像输入
用户拍一张报错截图、发一张产品照片,语音智能体可以直接基于视觉内容对话。这把「多模态」从演示里搬到了真实场景——售后场景里用户描述不清问题时,让他拍张照永远比让他口述靠谱。
3. SIP 电话呼叫
直接打通传统电话系统,PBX、桌面电话都能接入。这一条几乎是给 to B 客服市场量身定做的。早期合作的 T-Mobile 已经在客服侧跑试点,Zillow 则把它接进了房源语音搜索——按 Zillow 的说法,用户跟它聊筛选条件「就跟跟朋友聊天一样」。
异步函数调用:长任务不再卡住对话
这是个细节,但工程上很关键。以前函数调用一旦耗时长,整个对话就卡住等结果。gpt-realtime 原生支持异步函数调用——模型可以一边等结果一边继续聊,不用改代码。
这个改动在做交易类、查询类语音应用时几乎是刚需。客户问「我那笔退款到账了吗」,后端要查三个系统,过去这几秒里 AI 只能尴尬沉默;现在它可以一边查一边说「我在帮您查,请稍等,顺便确认一下您是用哪张卡支付的」。
价格与上下文控制
定价上,gpt-realtime 比前代降了 20%:
- 音频输入:32 美元 / 百万 token(缓存输入 0.40 美元)
- 音频输出:64 美元 / 百万 token
更值得关注的是新增的细粒度上下文控制——开发者可以设置 token 上限,一次性截断多个对话回合。长会话场景(比如售后电话动辄十几分钟)的成本会显著下降。这一条 OpenAI 没大张旗鼓地宣传,但跑过实际账单的人都会明白它的分量。
API 调用示例
OpenAI Hub 已同步支持 gpt-realtime,国内可直连,兼容 OpenAI 格式,一个 Key 调通。基础会话创建:
curl -X POST https://api.openai-hub.com/v1/realtime/client_secrets \
-H "Authorization: Bearer $OPENAI_HUB_KEY" \
-H "Content-Type: application/json" \
-d '{
"session": {
"type": "realtime",
"model": "gpt-realtime",
"voice": "cedar",
"instructions": "你是一名礼貌、专业的客服坐席,回答简短,遇到金额必须复述确认。"
}
}'
WebSocket 接入与官方一致:
const ws = new WebSocket(
'wss://api.openai-hub.com/v1/realtime?model=gpt-realtime',
{ headers: { Authorization: `Bearer ${process.env.OPENAI_HUB_KEY}` } }
);
ws.on('open', () => {
ws.send(JSON.stringify({
type: 'session.update',
session: {
modalities: ['audio', 'text'],
voice: 'marin',
input_audio_format: 'pcm16',
output_audio_format: 'pcm16',
turn_detection: { type: 'server_vad' }
}
}));
});
怎么看这次更新
把这次的 Realtime API GA 放在更长的时间线上看,OpenAI 的语音路线已经走完了三步:
- 2024 年 10 月:Realtime API 公测,证明「语音对语音」这条技术路径可行;
- 2025 年 3 月:发布 GPT-4o-transcribe / mini-transcribe / mini-tts,把传统的串联方案也补齐,照顾不愿一步到位的开发者;
- 2026 年 5 月:GA + gpt-realtime + MCP/图像/SIP,正式瞄准生产环境。
语音赛道从来不是「谁的 Demo 更惊艳」,而是「谁能让企业把客服外包给 AI」。这一点上,Google 的 Gemini Live、ElevenLabs 的 Conversational AI 都在卷,但 OpenAI 这次靠 MCP 生态 + SIP 电话 + 端到端模型质量,把门槛拉到了一个相当高的位置。
对开发者来说,最实际的判断是:如果你之前因为延迟、自然度或工程复杂度搁置了语音项目,现在值得重新评估一次。尤其是客服、教育陪练、创作者陪伴类产品——这是 OpenAI 在博客里点名的三个方向,也是商业化最清晰的三个场景。
参考来源
- InfoQ:OpenAI 推出 gpt-realtime — 中文详细解读,包含 benchmark 与企业试点