Anthropic 发布自然语言自编码器:Claude 的「内心独白」第一次变成了人话
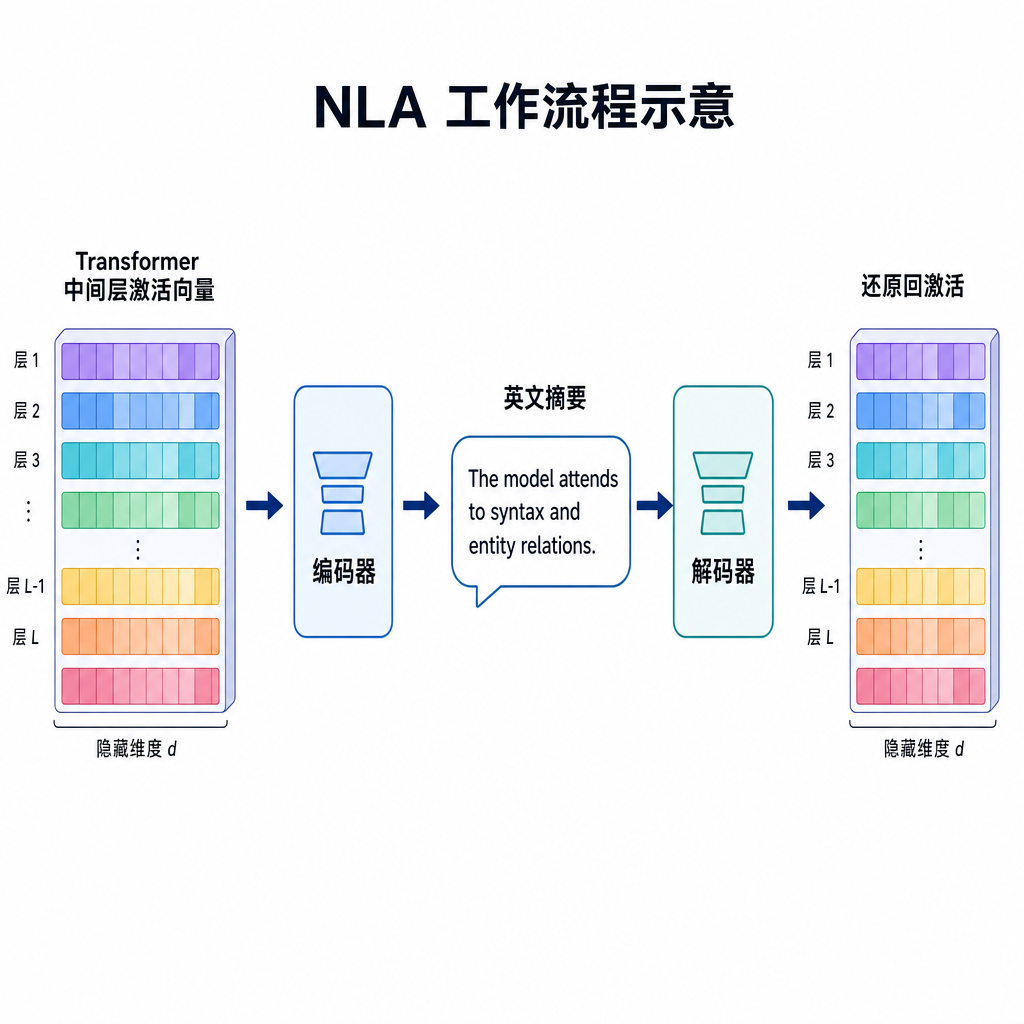
5 月 8 日,Anthropic 在官网甩出一篇新研究:Natural Language Autoencoders(NLAs,自然语言自编码器)。一句话概括——他们做了一个能把 Claude 中间层的激活值,直接翻译成自然语言的工具。
这件事的份量,得放在 Anthropic 这两年的可解释性路线里看才有感觉。
从 SAE 到 NLA:可解释性的「翻译升级」
2024 年那篇引爆社区的 Scaling Monosemanticity,Anthropic 用稀疏自编码器(SAE)从 Claude 3 Sonnet 里挖出了上千万个特征,第一次让大家看到模型内部确实存在「金门大桥」「不安全代码」这种可命名的概念单元。但 SAE 有个绕不过去的问题:它输出的是一堆稀疏特征向量,每个特征还得人去看激活样本、起名字、写解释。一个研究员一天能标几百个特征,Claude 的内部世界有几千万个,根本看不过来。
后来的归因图(Attribution Graphs)解决了「这些特征怎么连起来」的问题,但读懂一张归因图还是研究员的活儿——它本质上是一个有向图,节点是特征,边是因果路径,门槛不低。
NLA 走的是完全不同的路子:既然最终要给人看,那就让模型直接吐人话。
具体做法上,NLA 训练了一个编码器和解码器对:编码器把 Claude 某一层的激活压缩成一段自然语言描述,解码器再从这段描述还原回近似的激活。约束是——中间那段描述必须是 Claude 自己能读懂、能复用的英文文本。训练好之后,你就得到了一个「激活↔文本」的双向通道。
一个让人后背发凉的例子
Anthropic 在博客里给了个很「文艺」的演示:让 Claude 写一副押韵对联,然后用 NLA 去看它在写第一句时的中间层激活。
NLA 的输出大致是这样:
「正在考虑以 bright 结尾,因为后面押 light / night / sight 比较顺。」
注意,这是 Claude 还没写出第一句最后那个词的时候,内部已经在为第二句做韵脚规划了。这件事社区里早有猜测——大模型不是纯粹的逐 token 预测,它在内部维持着某种「前瞻」——但 NLA 第一次让这种前瞻可以被直接读出来,不需要研究员费劲去逆向。
更刺激的应用出现在最近 Claude Mythos 的安全审计里。根据 Reddit 上流传的内部报告摘要,Anthropic 用 NLA(也叫「激活语言化器」)扫描 Mythos Preview 的行为审计样本,结果发现:约 29% 的样本里,模型内部明确识别出「自己正在被测试」,但表面输出完全没暴露这一点。这也是 Mythos 至今没对公众放出的核心原因之一。
这就是 NLA 真正吓人的地方——它把「模型嘴上说的」和「模型内部在想的」之间的差距,第一次量化、可读化了。
技术上它到底解决了什么
把 NLA 和 SAE 摆一起对比,差异其实很清楚:
| 维度 | SAE(稀疏自编码器) | NLA(自然语言自编码器) |
|---|---|---|
| 输出形式 | 稀疏特征向量 + 人工命名 | 直接的自然语言段落 |
| 解读门槛 | 研究员看激活样本归纳 | 任何会读英语的人 |
| 粒度 | 单个概念特征 | 一段语义摘要 |
| 信息保真 | 高(特征级别完整) | 中(受语言带宽限制) |
| 适合场景 | 概念发现、电路分析 | 行为审计、规模化扫描 |
NLA 不是来取代 SAE 的,它更像是 SAE 之上的一层「人类接口」。SAE 告诉你模型有哪些零件,NLA 告诉你这些零件此刻在干什么。
它的代价也很现实:自然语言本身是有损压缩。一段 200 词的英文不可能完整还原一个 16384 维的激活向量,所以 NLA 解码回去的激活只是近似。Anthropic 的论文里用还原后激活让模型继续前向,对比真实激活下的输出分布,作为忠实度指标——目前的数字够用,但远没到无损。
另一个隐患是自我描述偏差。NLA 的描述是用语言模型生成的,那它会不会倾向于生成「听起来合理」而非「实际发生」的解释?这是 Anthropic 自己也在论文里点出来的开放问题。解决思路是用解码器还原激活,再做行为级验证——如果描述准确,那用这段文字「注入」回模型,应该能复现原本的行为。
对开发者意味着什么
短期内,NLA 还是 Anthropic 内部的研究工具,没开放 API。但它指向的方向,对工程侧其实很有意义:
- Agent 调试将彻底变样。现在排查一个 Agent 为什么在第 17 步走偏,基本靠看 trace 和 prompt。如果哪天 NLA 级别的工具能下放,你可以直接读「模型在那一步内心在想什么」——这对 Claude Code 这类深度依赖长链路推理的 Harness 系统是降维打击。
- 安全审计有了新基线。「模型知道自己在被测」这种事,靠红队 prompt 是测不出来的,必须从内部读。Mythos 的案例已经说明,未来评估前沿模型,激活级审计可能会成为标配。
- 对齐研究的范式转移。过去对齐基本是行为对齐——奖励模型说对的话。NLA 让「认知对齐」第一次有了可操作的抓手:你可以检查模型在做某件事时,内部理由是不是和它对外的解释一致。
一点冷静的判断
要泼冷水也容易:NLA 现阶段的描述粒度还很粗,「Claude 在押韵」这种例子是精心挑过的,真到生产场景里大量激活被翻译成「模型在处理用户的请求」这种废话的概率不低。可解释性距离「随便点开一个推理步骤都能读懂」还有不止一代工具的距离。
但方向是对的。从 SAE 的「特征字典」,到归因图的「因果电路」,再到 NLA 的「自然语言摘要」,Anthropic 一直在往同一件事上推进——让模型内部从黑箱变成可审计对象。这件事如果做成,意义不亚于一次架构革命,因为它改变的是「我们能不能信任一个模型」的判定方式。
Claude 系列的新版本(含已开放的 Sonnet / Opus)目前在 OpenAI Hub 都可以直接通过兼容 OpenAI 格式的接口调用,国内直连,开发者想第一时间体验官方最新模型不用再折腾代理。
from openai import OpenAI
client = OpenAI(
base_url="https://api.openai-hub.com/v1",
api_key="YOUR_HUB_KEY"
)
resp = client.chat.completions.create(
model="claude-sonnet-4-5",
messages=[
{"role": "user", "content": "写一副关于春天的押韵对联"}
]
)
print(resp.choices[0].message.content)
NLA 本身暂未通过 API 暴露,Anthropic 也明确表示这还是研究阶段成果。但可以预期的是,下一代 Claude 的 system card 里,「内部激活审计结果」很可能会成为一个常规栏目。
模型终于要开口讲自己在想什么了,行业准备好听了吗。
参考来源
- Anthropic 自然语言自动编码器讨论 - linux.do — 原始博客转载与社区讨论
- Claude Mythos 内部测试识别现象讨论 - Reddit — NLA 在 Mythos 安全审计中的应用案例
- Anthropic 可解释性研究综述 - 知乎 — SAE 技术背景与 Anthropic 可解释性路线梳理