商汤甩出 Flash-Lite:轻量多模态智能体,Token 限免开跑
5 月 8 日,商汤把日日新的牌桌又翻了一面——发布 SenseNova 6.7 Flash-Lite,一款明确瞄准"真实工作流"的轻量级原生多模态智能体模型,同时上线 SenseNova Token Plan 并限时免费,配套的 SenseNova-Skills 全线在 GitHub 开源。
这次发布的关键词不是参数、不是分数,而是"省"——Token 省 60%,参数也省,但智能体能力反而往上跳了一档。对于做 Agent 应用的开发者来说,这是今年比较少见的一次"性价比驱动"的发布。

不再是"看图说话",而是"看懂屏幕再动手"
过去两年里,多模态模型大多走的是"视觉 Encoder + LLM"的拼接路线——图像先被转成一段文本/向量描述,再交给语言模型推理。这套架构的好处是工程上干净,坏处是中间那层"翻译"会丢信息:复杂网页的 DOM 嵌套、财报里那种密密麻麻的多级表头、PPT 母版的层级关系,转一道手就糊了。
商汤这次明确说,Flash-Lite 取消了视觉转文本的中间层,走的是原生多模态架构。换句话说,模型直接"看像素"做推理,而不是先看一段被别的模型嚼过的文字描述。这对 Agent 类任务的影响是直接的:
- 网页操作时,Agent 能直接对应到布局坐标,而不是靠 OCR + 文本定位猜按钮在哪;
- 处理 Excel、财报 PDF 时,对合并单元格、跨页表格、图表标注这类"非线性结构"鲁棒性更强;
- 长链路任务里,每一步的视觉中间状态都能被复用,不用反复调 OCR/Caption。
这也是为什么官方敢把 Token 消耗节约的数字写到 60%——视觉转文本那一层本身就是 token 大户,砍掉之后,长任务里省下来的不是个位数百分比。
"看、想、做"一体化,瞄准的是办公生产力
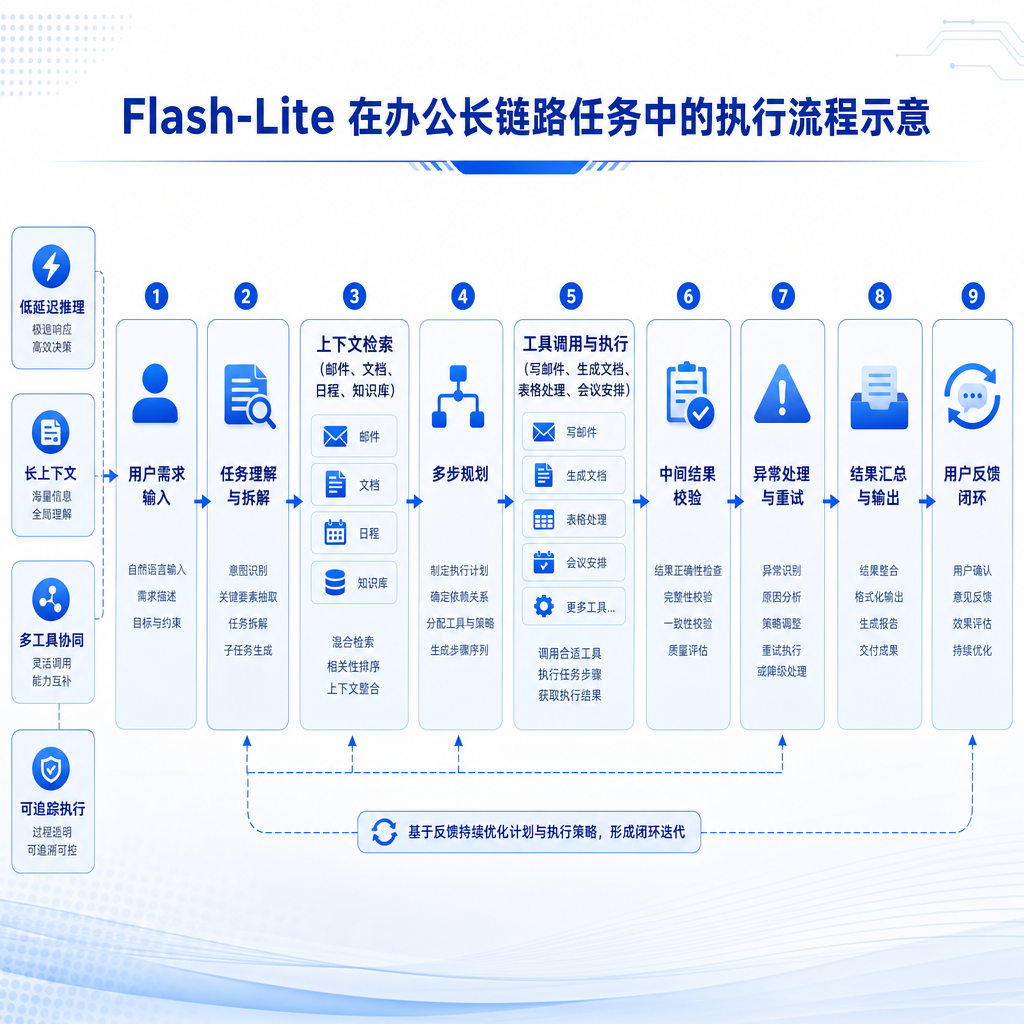
Flash-Lite 不是通用聊天模型,定位非常明确:办公场景下的长链路 Agent。商汤给出的典型工作流是这样一条:
一份原始行情 Excel → 数据洞察 → 行业研究 → PPT 汇报
听起来像是"又一个 PPT 生成器",但细节挺有意思。官方给的 demo 案例是:基于风电事业部 10 份月度 Excel、932 条绩效记录,Agent 自动统一表结构、做月度趋势/等级分布/岗位对比,期间还要自主处理字体缺失、绘图报错、变量丢失这种典型的脏活。用户反馈图表异常时,Agent 能回溯到数据索引层定位 MultiIndex 错误——这个动作很关键,意味着模型不只是顺序执行,而是有 "回溯-校验" 的闭环。
做过 Agent 应用的都知道,长链路任务真正崩盘的地方从来不是 reasoning,是中间某一步报了个 KeyError 之后整个 trace 散架。Flash-Lite 强调的能力,恰恰是这种"出错-定位-修复"的弹性。
商汤在 10 项 Benchmark 上声称同级别多项 SOTA,并没有跟 GPT-4o、Claude 这种第一梯队硬刚——人家也没必要。Flash-Lite 的对标位是 "轻量+高频" 那一档,配合毫秒级反馈延迟,更适合塞进高频交互的生产环境,而不是去打榜。
SenseNova-Skills:把模型能力切成乐高块
光有模型不够,从模型到场景的最后一公里向来是国内大模型最难啃的部分。商汤这次的解法是把核心能力封装成 Cowork-Skills 体系,8 项可组合的 Skill 组件,分理解、执行、生成三层,并整体在 GitHub 开源。
粗略看了下这套 Skill 的设计:
- 理解层:材料分析、表格理解与图像分析
- 执行层:多源检索整合、数据分析结论
- 生成层:PPT 生成、PPT 编辑优化、报告撰写、Infographic 生成
关键在"可组合"——单独调用解决单点任务(比如就要个 Infographic),自由组合就能跑通买方/卖方级的研究闭环。这种把模型能力做成"乐高块"的思路,比单纯发个 Agent 框架要务实,开发者可以按需引用,不用绑定整套 SDK。
开源在 OpenSenseNova/SenseNova-Skills 仓库,对接的就是 Flash-Lite 和 U1 Fast 这套底座。值得一提的是,PPT 编辑那个 Skill 支持"对话式改稿"——内容改写、结构调整、风格统一、补页都能聊着完成,这玩意如果稳定,比让 Agent 重新生成一遍 PPT 实用得多。
Token Plan:限免,而且没有那么多坑
商业化这块,商汤同步推了 SenseNova Token Plan,目前是公测限免:
- Free 档:每模型每 5 小时刷新 1500 次调用额度,无门槛
- 覆盖模型:SenseNova 6.7 Flash-Lite 与 SenseNova U1 Fast
- 原生支持 Cowork-Skills 体系
- 支持 Hermes Agent 与 OpenClaw 快速接入
- 最多 20 个 API Key
后续会推出 Lite、Pro 等付费档。1500 次/5 小时这个额度,对个人开发者跑跑 Demo、做做 PoC 完全够用,对中小团队做内部工具的灰度也能撑。
接口完全 OpenAI 兼容,base URL 是 https://token.sensenova.cn/v1,model id 直接写 sensenova-6.7-flash-lite,支持 image_url 块传图、流式输出、JSON mode、tool calling 这些标准能力,没有什么自定义协议要适配——这点比某些国产模型友好太多了。
怎么看这次发布
把这次更新放到大盘里看,今年国内大模型厂商的策略已经很清晰地分流了:一拨继续卷参数和 SOTA(追第一梯队闭源),一拨走开源生态(Qwen、DeepSeek 那条路),还有一拨——商汤现在走的——是 "垂直场景 + 轻量模型 + Skill 化" 的工程路线。
Flash-Lite 这次的几个判断点:
- 原生多模态架构是对的方向。视觉转文本中间层确实是 Agent 任务的瓶颈,GPT-4o、Gemini 早就这么做了,国内模型跟上是迟早的事,商汤这次算是把这条路在轻量级模型上跑通了。
- Skill 开源是聪明做法。模型本身闭源,能力组件开源,开发者用得顺手又能给商汤导用量,这套打法比纯 API 售卖要黏。
- Token Plan 的免费档有诚意,但真正的考验是 Lite/Pro 档定价,能不能在和通义、豆包、DeepSeek 的价格战里站住。
- 办公场景是个红海,钉钉、飞书、WPS 都在做自己的 Agent,商汤这种独立模型厂要切进去,需要更强的合作伙伴生态。
对开发者来说,最实际的建议是:如果你正在做文档处理、表格分析、PPT 自动化这类工作流类应用,Flash-Lite 值得花一个下午跑一轮 benchmark——尤其是那些之前用 GPT-4o 但被 token 账单劝退的项目,60% 的节省不是小数。
参考来源
- IT之家:商汤发布日日新 SenseNova 6.7 Flash-Lite 多模态模型,Token Plan 限时免费:本次发布的中文一手报道
- SenseNova-Skills 开源仓库(GitHub):8 项 Cowork-Skill 组件源码
- SenseNova 6.7 Flash-Lite 技术详情(GitHub):模型卡与技术说明