商汤这次没卖会员,直接发券。
5月8日,商汤日日新(SenseNova)上线了一项叫做 Token Plan 的订阅服务,并同步开启限时免费公测——开发者注册即用,每个模型每5小时刷新1500次调用配额,无门槛、不收费。覆盖的三款模型分别是新一代轻量化多模态智能体模型 SenseNova 6.7 Flash-Lite、原生理解生成统一多模态模型 SenseNova U1 Fast,以及通过商汤 API 转售的 DeepSeek V4 Flash。
在小米 MiMo 刚撒完一轮 token、智谱 GLM-4.7 价格被打到 GPT-5.5 的七分之一的当口,商汤这一手不算意外,但配置组合得有点意思。
一份给开发者的免费午餐,但菜单值得细看
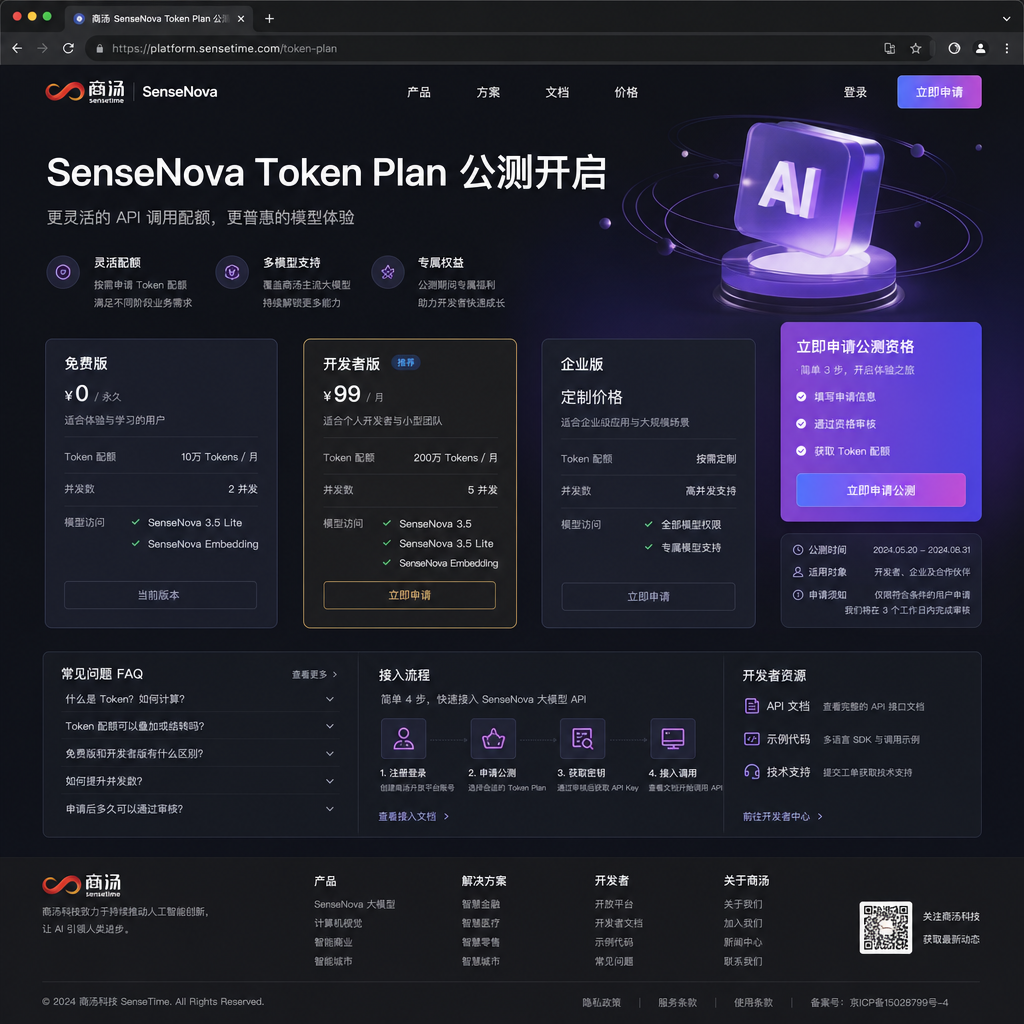
先把账算清楚。Token Plan 公测版(Free 档)的核心条款是这样的:
- SenseNova 6.7 Flash-Lite:每5小时 1500 次调用
- SenseNova U1 Fast:每5小时 1500 次调用
- DeepSeek V4 Flash:每5小时 150 次调用(注意是 150,不是 1500)
- 最多可创建 20 个 API Key
- 完全兼容 OpenAI API 格式,Base URL 为
https://api.sensenova.cn/v1
这里有一个微妙的差距:DeepSeek V4 Flash 的额度只有商汤自研模型的十分之一。原因不难猜——DeepSeek V4 Flash 是 DeepSeek 5月最新发布 V4 系列的轻量版,商汤是以渠道商身份转售调用,每一刀都要给上游结账。给到 150 次,更像是"尝鲜票"而不是"自助餐"。
但这张尝鲜票的含金量不低。有开发者实测 DeepSeek V4 Flash 在商汤通道下的吐字速度达到 140 token/s,对于需要思考模式 + 256K 上下文的场景,这是目前国内能拿到的免费选项里相当靠前的一档。
三款模型的角色分工
商汤这次没有把所有筹码压在一个旗舰模型上,而是把三款定位错开的模型打包成"工作流套件",这是 Token Plan 在产品策略上和小米、智谱免费 token 的最大区别。
SenseNova 6.7 Flash-Lite:办公流的轻量底座
这是 6.7 系列的"瘦身版",主打多模态智能体,上下文 256K(最大输入 252K,最大输出 64K)。商汤给它配的关键词是 Cowork-Skills、Hermes Agent、OpenClaw——翻译成人话,就是绑死在自家 Agent 框架上,目标是接管"读文档-填表-写报告"这类长链路办公任务。
商汤官方给出的数据是,相较于纯文本智能体模型,基于多模态底座完成长链路任务可以省下 60% 的 token 消耗。这个数字得加引号——是按"平均估算"算的,实际任务波动不小。但思路是对的:复杂任务里,纯文本反复往返调用的 token 开销,确实可能比一次多模态调用更贵。
SenseNova U1 Fast:信息图生成专用
U1 Fast 是 SenseNova U1 的加速版,专供信息图(Infographics)生成场景。它有一个细节需要注意:走的是独立的 POST /v1/images/generations 接口,不是 Chat Completions,也不支持图像输入。
换句话说,它不是 GPT-4o 那种"边聊边画"的全能型选手,而是一个垂直工具——你给文字描述,它给你一张图文并茂的信息图。商汤把"理解-生成统一架构"卖点压在这上面,瞄准的是 PPT、运营海报、数据图这种规整的 B 端场景。
DeepSeek V4 Flash:长上下文 + 思考模式
这个不用多介绍。DeepSeek V4 系列 5 月初刚发,Flash 版砍掉了一部分参数换速度,支持思考/非思考双模式、256K 上下文、64K 输出,内置 JSON Output 和 Tool Calls。商汤把它塞进 Token Plan,更像是给套餐"撑场面"——开发者不会只为了商汤模型来注册,但会为了 DeepSeek V4 Flash 来。
接入成本:基本等于零
Token Plan 全套兼容 OpenAI 格式,已经在用 OpenAI SDK 的项目,改两行就能切过来:
- Base URL 改为
https://api.sensenova.cn/v1 - Model ID 填
sensenova-6.7-flash-lite/sensenova-u1-fast/deepseek-v4-flash - API Key 走商汤后台领取,最多 20 个
现有的 Agent 工具链——包括商汤自家开源的 OpenClaw,以及社区里基于 OpenAI SDK 的各种 Agent 框架——都能直接迁。这是 2025 年以来国产模型的标准操作了,谁还想搞私有协议谁就出局,没人陪你玩。
这波免费,本质是在抢 Agent 入口
看 Token Plan 的设计,商汤的算盘其实写在脸上:免费 token 是钩子,Hermes Agent 和 Cowork-Skills 才是要钓的鱼。
Free 档里反复强调"原生支持 Cowork-Skills 体系,办公场景特化支持""支持 Hermes Agent 与 OpenClaw 快速接入"——开发者用免费额度跑出来的工作流,迁移成本就建立在这套 Skills 体系上。等真要上量,自然会续 Lite 或 Pro 档。这是一套很标准的 PLG 玩法,比当年靠 BD 卖 API 的路子聪明得多。
问题在于,这条路上人已经很多了。智谱有 ChatGLM Agent,阿里有百炼,字节有扣子,DeepSeek 自己也在做 Agent。商汤的优势是多模态——尤其是文档、表格、信息图这块,6.7 Flash-Lite 和 U1 Fast 的组合确实有差异化。但要让开发者真正把 Hermes Agent 当成默认选择,光靠免费 token 不够,得靠生态里跑出几个像样的 Killer App。
横向对比:免费 token 的"军备竞赛"
把最近这一波数一下:
- 小米 MiMo:上亿 token 一次性发放
- 智谱 GLM-4.7:API 价格降到 GPT-5.5 的 1/7
- 商汤 Token Plan:每5小时刷新,长期可用
商汤的玩法和前两家不太一样。一次性 token 用完就完,价格战是消耗战,而**"5小时刷新 1500 次"是一种节奏型的免费**——你没法囤,但只要你持续用,它就持续给。这种设计反而更适合让开发者把它接进真实的工作流里跑日常任务,而不是薅一把就走。
对国内开发者来说,现在 API 选择已经多到挑花眼。OpenAI Hub 这类聚合平台的价值也越来越实在——一个 Key 调通 GPT、Claude、Gemini、DeepSeek 全家桶,国内直连不折腾,新模型上线通常也会跟进支持。商汤 Token Plan 这种限时免费的窗口,配合聚合平台做主备切换,对成本敏感的项目算是一个不错的搭配。
结语
SenseNova Token Plan 这次发布,技术上没什么炸点——6.7 Flash-Lite 和 U1 Fast 都是已知模型的衍生版本。真正值得关注的是商汤的策略转向:从卖 API 转向卖工作流,从打榜单转向抢 Agent 入口。
在头部模型已经被 GPT、Claude、Gemini 锁死的格局下,国产厂商集体转向"垂直场景 + 免费引流 + Agent 生态"的路线,几乎是必然选择。商汤这一步走得不算激进,但思路清楚。
至于这波免费能持续多久——按商汤的说法是"限时公测",没给明确截止日期。想试的开发者建议早点动手,毕竟免费午餐这种东西,过了这村就难说了。
参考来源
- 商汤发布日日新 SenseNova 6.7 Flash-Lite 多模态模型 - IT之家:发布会详细信息与 Token Plan 配额说明
- OpenSenseNova/SenseNova-Skills - GitHub:商汤 Cowork-Skills 体系开源仓库