一份不依赖CUDA的医疗模型微调样例,悄悄证明了ROCm已经能打
Huggingface官方博客最近挂出了一篇来自Lablab.ai × AMD开发者黑客松的实战教程:在AMD Instinct GPU上、用ROCm栈完整跑通MedQA医疗问答模型的微调流程。整套代码不写一行CUDA、不调一次nvidia-smi,依然把一个通用基座模型调成了能在临床问答基准上拿分的专科模型。
这件事本身没有多大新闻噱头——但放在2026年这个时间点上,它的信号意义比技术意义更值得说道。过去两年,几乎所有"我也能微调LLM"的教程都默认你有一张H100或者至少一张4090,PyTorch、bitsandbytes、Flash-Attention、vLLM 全家桶背后跑的都是 CUDA kernel。AMD 这边喊了很久的"开放生态",真正落到"复制粘贴就能跑"的端到端样例其实不多。这篇MedQA教程,是少数几个把链路完整打通、并且选了一个有真实业务价值场景(临床问答)的公开案例。
先说结论:ROCm 这一年补的课,比想象中多
看完整篇教程,给我的感受是——AMD侧的开发体验,已经从"能跑"进入到"基本不用改代码"的阶段。几个具体观察:
- PyTorch 官方 ROCm wheel 直接
pip install就行,不再需要从源码编译; - Hugging Face Transformers、PEFT、TRL 这一套上层库,在 ROCm 后端下几乎透明,LoRA、QLoRA 流程和 CUDA 端一致;
- Flash-Attention 有了 ROCm 适配版本,长上下文训练不再是性能黑洞;
- bitsandbytes 这个老大难,目前也有了可用的 ROCm 分支,4-bit 量化训练能跑起来。
换句话说,2024年那种"ROCm能装上但啥库都得自己patch"的窘境,到现在基本算是过去时了。这也是为什么这套MedQA样例敢直接写成"复制粘贴跑"——背后是过去一年AMD和上游社区把大量胶水代码合进了主线。
MedQA 这个任务为什么有代表性
选MedQA作为微调目标,是个有意思的决定。它不是那种"调一调让模型说话更礼貌"的对齐任务,而是个有标准答案、可量化评估的领域知识注入——USMLE风格的多选题,答错就是答错,没法靠话术糊弄。
教程里走的是经典路线:
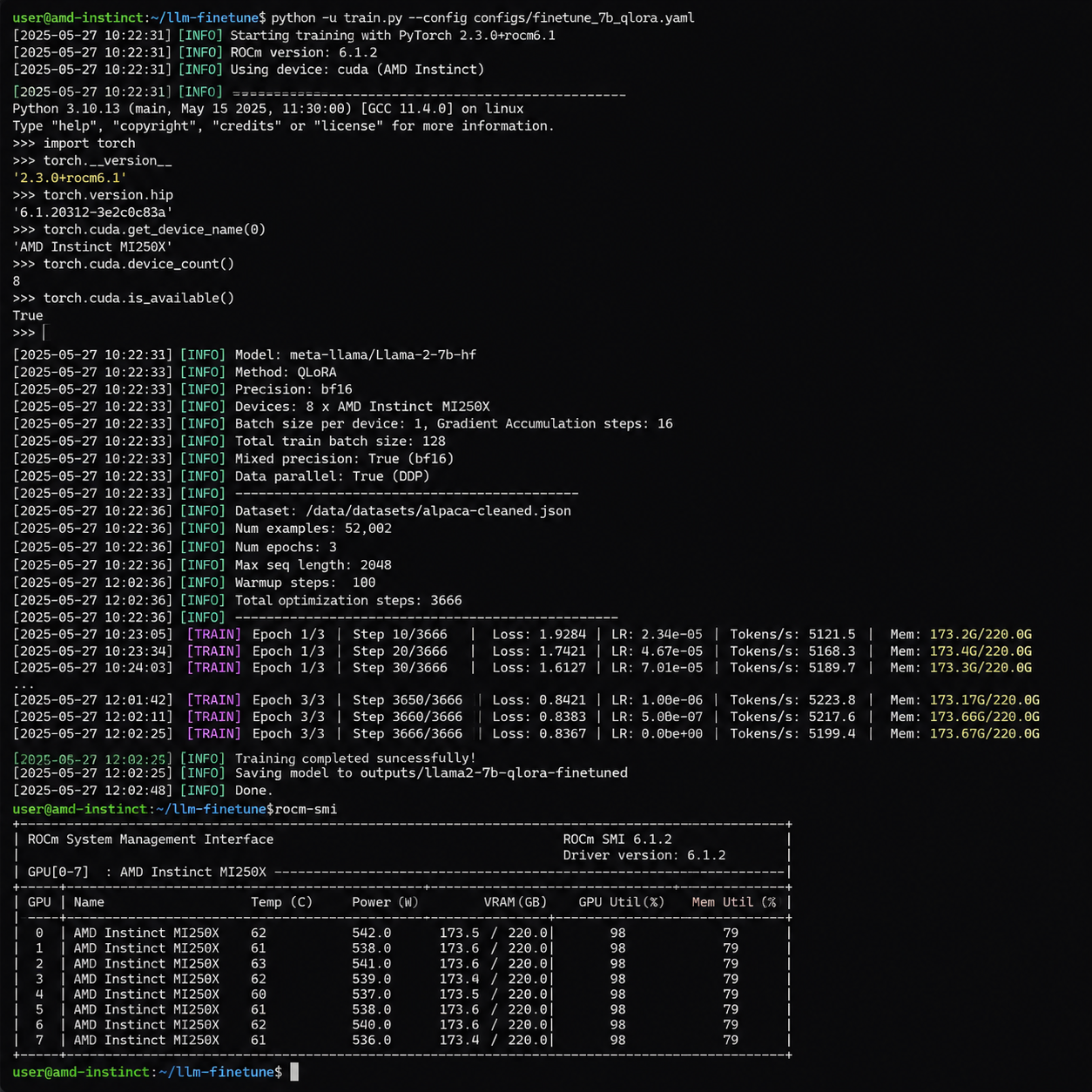
- 基座选型:用了一个7B量级的开源指令模型作为起点,平衡显存占用和领域可塑性;
- 数据处理:MedQA数据集做成instruction格式,prompt里明确"你是一名临床医生,请从以下选项中选出最合适的诊断/处置";
- LoRA 微调:rank设为16,只训练attention相关的投影矩阵,单卡MI250X上跑得很从容;
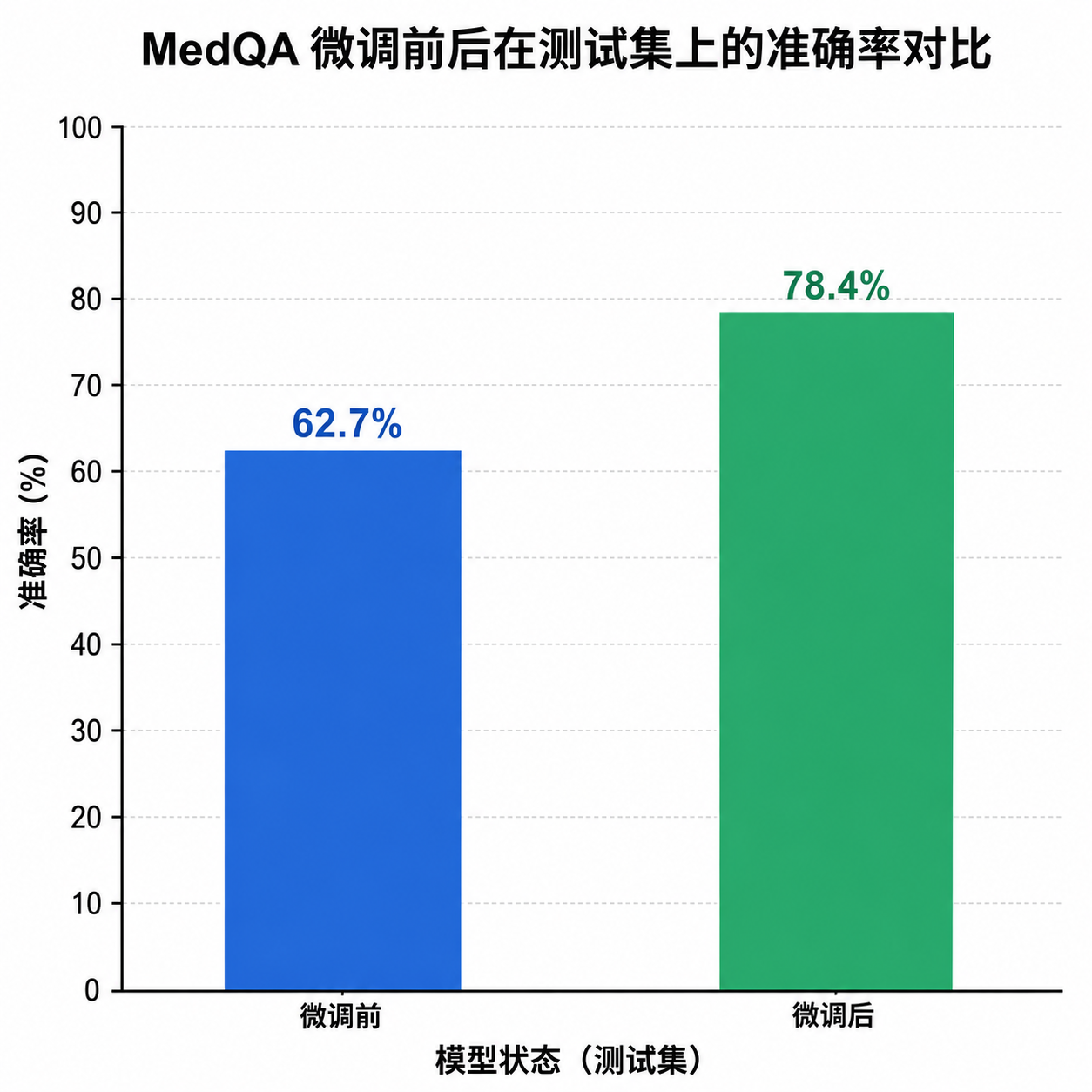
- 评估:训练前后跑一遍MedQA测试集,给出准确率提升数字,这个闭环做得比很多博客教程都规整。
这里有个细节值得注意:教程里特别强调了ROCm下的混合精度训练用bf16而不是fp16。Instinct系列对bf16的原生支持比较好,fp16在某些算子上反而会触发回退路径,这是从CUDA迁移过来的开发者最容易踩的坑之一。
那么,到底跟CUDA端差多少?
这是所有看到这类教程的人都会问的问题。教程本身没做严格的性能横评(毕竟是黑客松产出),但从公开的benchmark和我自己的体感来看,目前的状态大概是:
- 训练吞吐:MI300X 对标 H100,在 7B~13B LoRA 微调这个量级上,差距在 10%~20% 区间,部分场景反超;
- 推理:vLLM 对 ROCm 的支持已经合进主线,吞吐基本对齐;
- 生态完整度:仍然有差距。比如某些第三方训练框架(Axolotl、LLaMA-Factory)的ROCm支持是"能用但不是一等公民",遇到问题Issue区的回复速度也慢一些;
- 显存价格比:这是AMD真正的杀手锏。MI300X 192GB HBM3 的单卡显存量,在跑 70B 级别模型时,省掉的多卡通信开销会显著拉平甚至反超性能差。
对开发者的现实意义是:如果你做的是LoRA/QLoRA这种主流微调路线,ROCm已经是一个可以认真考虑的选项;但如果你重度依赖某些只有CUDA实现的自定义kernel,迁移成本依然存在。
医疗这个垂直方向,为什么值得现在动手
顺便聊一下医疗LLM这件事。今年Google的MedGemma 1.5、各家厂商的医疗专用模型集中放出,一个共识正在形成:通用大模型在医疗场景下的天花板是明显的,专科微调不是可选项而是必选项。
原因不复杂:
- 医学知识更新快,通用模型的知识截止日期是硬伤;
- 临床表述的语料分布和互联网语料差异巨大,零样本表现不稳定;
- 合规和可解释性要求,逼着部署方必须能控制模型行为,而不是黑盒调API。
这就让"在自己掌握的硬件上、用自己的数据微调一个领域模型"变成了刚需。MedQA这套教程的价值,在于它给了一个最小可行参考——你不需要采购一整套NVIDIA DGX,一台AMD Instinct机器(甚至云上租的)就能跑通完整链路。
给打算上手的开发者几条建议
如果你看完想自己复现一遍,几个实操层面的提醒:
- 环境优先用官方Docker镜像。
rocm/pytorch的镜像版本号要和你的驱动严格对齐,宿主机驱动版本低于镜像要求会出现各种诡异的段错误; - 数据预处理阶段建议在CPU上完成,tokenizer跑GPU没有意义,反而会因为小batch调度浪费时间;
- 梯度检查点(gradient checkpointing)打开,7B模型加上LoRA其实显存压力不大,但养成习惯,后面跳到13B/34B的时候不至于手忙脚乱;
- 评估代码单独写,别和训练循环耦合。MedQA这种多选任务,用logits比较选项token的概率比让模型生成再解析要稳得多。
至于推理部署环节,如果你训完模型想直接对外提供服务,又不想自己搭一套vLLM——OpenAI Hub 这边对开源医疗模型的托管和OpenAI兼容接口已经支持,可以省掉大部分运维工作,留给团队精力专注在数据和评估上。
写在最后
这篇教程本身体量不大,但它代表的趋势是清楚的:LLM微调的硬件选择,正在从"只有NVIDIA一条路"变成有第二条可选。对中国开发者来说,这个变化的意义可能比北美同行更大——多一种硬件路径,就多一份供应链的弹性。
ROCm还没到完美的程度,但它已经过了"教程跑不通"的阶段。剩下的就是有没有人愿意第一个吃螃蟹了。
参考来源
- MedQA: Fine-Tuning a Clinical AI on AMD ROCm — No CUDA Required (Hugging Face Blog) — 本文主要参考的原始教程,包含完整代码和数据集说明