一夜之间,PinchBench 换了主人
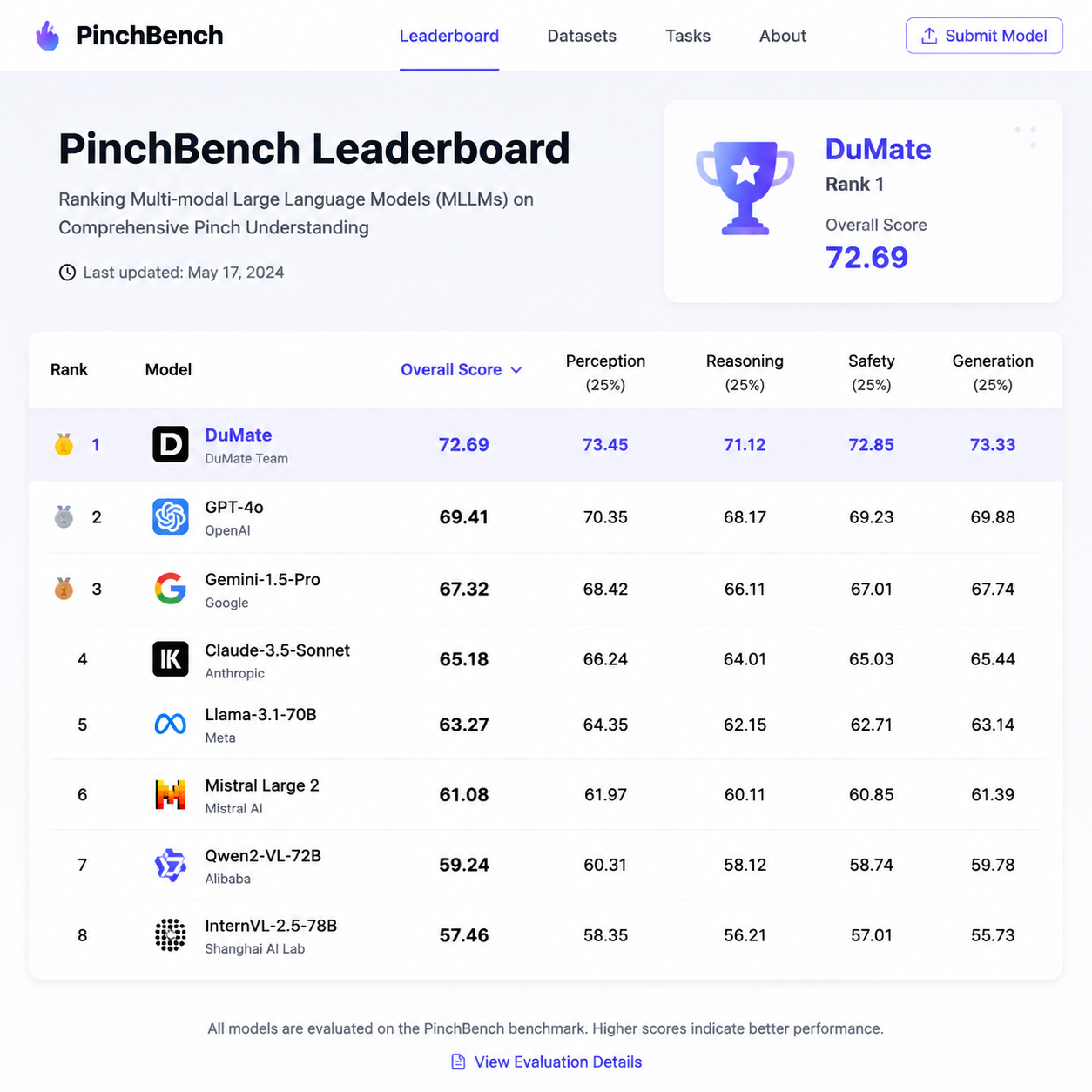
5 月 8 日凌晨,PinchBench 榜单悄悄刷新了一次。榜首位置上,原本几乎被 Claude Opus、GPT-5.5 系列轮流占据的格局被打破——百度的智能体产品 DuMate(百度搭子) 拿下第一,且前五位里有三席挂着百度的名字。同期发布的 DeepResearch 深度研究榜单上,DuMate 同样排在第一。
这是国产智能体第一次在 PinchBench 这种被海外厂商视作"自留地"的评测里坐上头把交椅。对一直被吐槽"刷榜不刷实战"的国产 Agent 阵营来说,这次的信号意义比分数本身还重要。
PinchBench 是什么,为什么这次登顶值得说
先把背景交代清楚。PinchBench 不是传统那种考模型做题的 benchmark,它考的是智能体在真实任务链路里的完成度——拆任务、调工具、跨应用操作、处理异常、长链路推理,全套打分。简单讲:MMLU 看的是模型记住多少,PinchBench 看的是 Agent 能不能把活干完。
这套榜单过去半年的常客是谁?Claude Opus 4.6/4.7、GPT-5.4/5.5、Gemini 3.1 这些一线选手。前几个月车端模型 Sage 在子项里冲到 94% 任务完成率已经算"破圈"了,但综合榜的总冠军一直没易主。
DuMate 这次拿下的不是单点项目,是综合榜 + DeepResearch 双榜第一,含金量直接翻倍。尤其 DeepResearch 这个分项,考的是模型多轮检索、信息交叉验证、长报告生成,最吃底层模型的推理深度和工具编排能力——这两块恰好是国产模型过去最被诟病的短板。
DuMate 是怎么干上去的
DuMate 这个产品对开发者圈来说不算陌生,定位是"AI 搭子",底座是百度文心系列,外面套了一层比较激进的 Agent 编排框架。这次能跑赢一线,几个点值得拆开看:
1. 多 Agent 编排是真功夫
从前五占三席这个细节就能看出来,百度送上去的不是一个版本,而是针对不同任务类型分化出的多个 Agent 配置。这套打法和 Anthropic 在 Code with Claude 大会上推的"多智能体编排+目标结果+自主推演"思路是同一条路——单体智能再强,遇到长链路任务不如把活拆开让多个 Agent 协作。
百度这次明显是把编排层做厚了,而不是单纯堆模型参数。
2. DeepResearch 拿第一,说明检索-推理闭环打通了
做过 Research Agent 的开发者都知道,难点不在于调搜索 API,而在于:
- 怎么判断当前信息够不够,要不要再搜一轮
- 多个来源冲突时信谁
- 长上下文里怎么不"失忆"
- 最后产出报告时引用怎么对得上
DuMate 在这个分项第一,意味着这套闭环至少在评测场景里跑通了。这块能力直接决定它能不能从 toC 的"搭子"延伸到 toB 的研究助理、行研、尽调这些更值钱的场景。
3. 中文场景的天然优势被放大
PinchBench 虽然是综合评测,但任务集本身覆盖中英文。海外模型在中文长尾任务、本地化工具调用(地图、外卖、日程这种)上有天花板,DuMate 这边是主场——这部分加分肯定贡献了不少分数。
国产 Agent 阵营的格局变化
把视角拉远一点。最近半个月模型圈的密度其实很高:
- 字节开源 Mamoda2.5,250 亿参数每次只激活 3 亿,多模态全任务 SOTA
- 蚂蚁百灵开源 Ling-2.6-1T,万亿参数,AIME26、SWE-bench Verified 上拿开源 SOTA
- DeepSeek 抛出"基于视觉原语的思考"框架,空间推理能跟 GPT-5.4 掰手腕
- 阿里通义开源 Qwen-Scope 可解释性工具套件
这些发布拼起来,传递的信号很清楚:国产模型已经不满足于在开源榜单刷分,开始往"应用层 Agent 实战榜"上打。DuMate 这次登顶,可以看作是这一波势能的一个标志性事件——评测维度从"模型能力"转向"产品级智能体能力",国产阵营第一次在后者拿下综合冠军。
但有几个问题得冷静看
好话说完,得泼点水。
第一,PinchBench 不是绝对真理。 任何 benchmark 都有过拟合风险,何况是任务集相对收敛的 Agent 评测。DuMate 一夜之间从榜外冲到第一,工程团队针对榜单做过专项优化几乎是必然的——这不丢人,海外厂商也都这么干,但读榜单时心里要有数。
第二,榜单第一 ≠ 用户体验第一。 Claude Opus 之所以在开发者群体里口碑硬,不是因为分高,而是 Claude Code 这种工具在真实工程里跑得稳。DuMate 要把榜单上的领先转化成开发者粘性,还得看 API 开放度、价格、生态适配这些。
第三,海外竞品没停。 OpenAI 这边 GPT-5.5 Instant 刚换代,Anthropic 在 Code with Claude 上把 Claude Code 调用限额翻倍、API 速率限制大幅放宽,xAI 也推了 Grok 4.3。一个月后 PinchBench 榜单长什么样,谁也说不准。
对开发者来说意味着什么
如果你正在做 Agent 类应用,这次榜单变动至少有三个落地启发:
- 国产底座可以严肃考虑了。过去做 Agent 项目,很多团队默认"复杂任务上 Claude,简单任务上国产",现在这个分层逻辑得重新评估,至少在中文长链路任务上,DuMate 背后的文心系列已经具备一线竞争力。
- 多 Agent 编排是真趋势。前五占三席说明百度把同一个底座拆成了多个特化 Agent 配置——这套"一个模型,多个分身"的打法值得借鉴,比单纯换更大的模型性价比高。
- DeepResearch 类场景是下一个红海。行研、尽调、合规、医疗文献综述这些场景,模型能力门槛终于跨过去了,产品化窗口正在打开。
OpenAI Hub(openai-hub.com)这边一个 Key 已经能直连主流模型,文心、Claude、GPT、Gemini、DeepSeek 都在列,做 A/B 测试的时候不用为了切模型去对接好几套 SDK,这种横评场景下省事不少。
写在最后
DuMate 登顶 PinchBench 这件事,单拎出来是一个产品的高光时刻;放在过去半年的国产模型节奏里看,是"国产 AI 从模型层卷到 Agent 层"这个长期叙事的一个节点。
好戏还在后面。下一次榜单刷新可能就是几周之后,Claude 和 GPT 那边肯定憋着劲要打回来。但有一点已经变了:以前国产模型在这种榜单里是"挑战者",现在是"卫冕者"——攻守易势,本身就是结果。
参考来源
- PinchBench 排行榜解读 - 知乎:PinchBench 榜单背景与全球模型 Token 消耗数据分析