谷歌把数学家的"副驾驶"做出来了
5 月 7 日,谷歌 DeepMind 低调放出一篇 arXiv 论文,正式发布 AI Co-Mathematician——一个面向数学研究的 Agent 系统。和过去那些刷 MATH、刷 AIME 的"应试型"模型不同,这次谷歌的目标客户写得很清楚:职业数学家。
说白了,前几年 LLM 在数学上的进展,本质都是在做"高考题"——题目封闭、答案唯一、解法有套路。但真实的数学研究不是这样的:你面对的是一个开放命题,可能花三个月连"这个猜想该怎么形式化"都还没想清楚,更多时候是在迭代假设、试探反例、查文献、跑 SageMath 验算。AI Co-Mathematician 想啃的就是这块硬骨头。
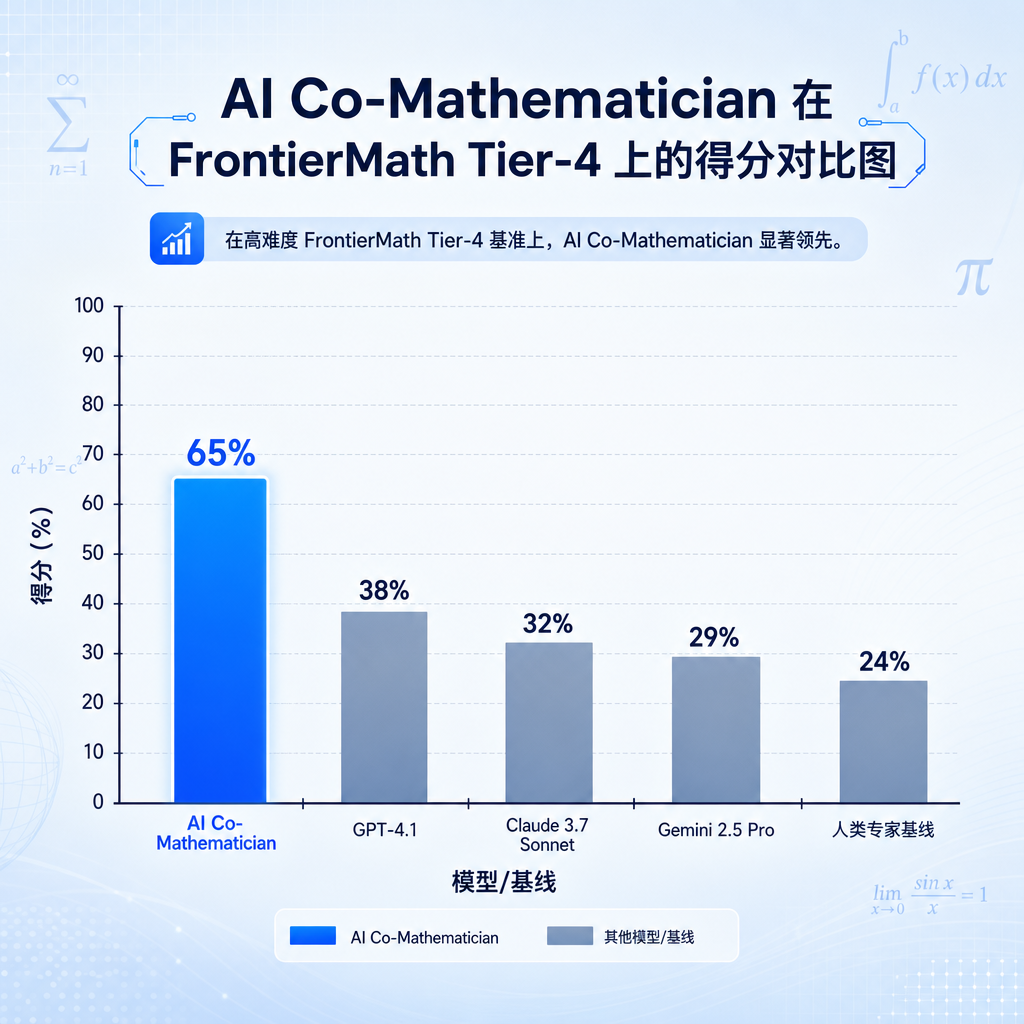
FrontierMath Tier-4:把 GPT-5.5 Pro 甩开了一档
最直接的冲击来自跑分。Epoch AI 的 FrontierMath Tier-4 是目前公认最难的数学评测集,题目由陶哲轩等一线数学家命题,难度对标研究生资格考试乃至博士课题前期工作。Tier-4 是其中最硬的一档——去年这个时候,所有前沿模型加起来在这一档上的解题率还不到 2%。
根据论文披露的数据:
- AI Co-Mathematician:Tier-4 解题率显著高于此前所有公开模型
- GPT-5.5 Pro:被甩开接近一倍的差距
- Gemini 2.5 Deep Think:作为底座之一,单独运行时分数明显低于 Agent 化后的版本
这个差距的关键,不在底层模型多强,而在它不是一次推理。AI Co-Mathematician 是一个 workbench 形态的 Agent 系统,会在内部反复 propose-verify-revise,调用证明助手、符号计算、文献检索,整个过程更像一个博士生在白板前推演,而不是一个考生在答题。
它到底是个什么形态
论文里 Google 把它定义为 "an interactive workbench",几个设计点值得开发者关注:
1. 不追求一锤定音,追求"可迭代"
传统数学 LLM 的交互是"我问你答"。AI Co-Mathematician 的交互更像 Cursor——数学家把一个未完成的想法丢进去,模型先帮你形式化、列出可能的攻击路径、指出哪几步有漏洞,然后你拿着它的反馈再去推。它不假装自己一步到位解出题,而是承认大部分时间是在"探索"。
这个产品哲学其实和陶哲轩这两年反复讲的一致:未来的数学是人机协同,AI 不会很快替代顶级数学家,但会把一个数学家的产能放大数倍。
2. 工具调用是一等公民
Agent 内置了对 Lean、SageMath、Mathematica 风格符号引擎的调用能力,以及 arXiv 检索。区别于普通 ReAct 框架的是,它的 verifier 是真在跑形式化证明,而不是让 LLM 自己 "check"——后者已经被反复证明是不可靠的。
3. 长上下文 + 状态化记忆
一个研究问题可能要持续几天到几周。论文里强调 Agent 维护了一个跨会话的"研究笔记"状态,包括已尝试路径、已排除的反例、未解决的引理。这点对真实数学工作流极其关键——数学家最怕的就是"我上周试过这条路了,但忘了为什么不行"。
和 AlphaEvolve 是什么关系
熟悉谷歌路线图的人会立刻想到去年发布的 AlphaEvolve——那个号称破解 300 年数学难题、自动发现算法的 Agent。两者定位不一样:
| AlphaEvolve | AI Co-Mathematician | |
|---|---|---|
| 目标 | 自动算法发现、组合优化 | 开放式数学研究协作 |
| 交互 | 基本无人值守 | 强调与数学家交互 |
| 输出 | 可运行代码 / 构造性解 | 证明草图、反例、形式化片段 |
| 底座 | Gemini + 进化搜索 | Gemini 2.5 Deep Think + Agent 框架 |
AlphaEvolve 是"让 AI 自己跑",Co-Mathematician 是"让 AI 陪你跑"。后者更接近大部分数学家真实的工作场景——纯粹自动化的科研在大多数领域还遥远,而协作式工具是马上能落地的生产力。
几个值得讨论的问题
第一,跑分能不能信? FrontierMath 的题目是封闭的,Epoch 自己也强调防数据污染。但 Tier-4 总共题目数量有限,方差天然大。论文里 Google 给了多次运行的均值和方差,相对透明,但要等第三方复测才能下定论。
第二,对开发者意味着什么? 短期内这玩意不会直接开放 API——它更像是 DeepMind 内部和合作数学家用的工具。但它定义的范式——长程 Agent + 真实工具调用 + 状态化研究记忆——对所有做"研究型 Agent"的团队都是模板。无论你做的是法律、生物还是代码 review,套路是相通的。
第三,Gemini 2.5 Deep Think 单独有多强? 这是更值得关注的信号。Co-Mathematician 的底座是 Deep Think 系列,论文中 ablation 显示,去掉 Agent 框架、只用底座推理时,Tier-4 分数也已经超过 GPT-5.5 Pro 标配版。这说明 Gemini 在纯推理能力上已经追上甚至反超 OpenAI 当前旗舰。
# 如果你想试试 Gemini 2.5 Deep Think 的推理能力
# OpenAI Hub 已支持,兼容 OpenAI 格式
from openai import OpenAI
client = OpenAI(
base_url=\"https://api.openai-hub.com/v1\",
api_key=\"your-key\"
)
resp = client.chat.completions.create(
model=\"gemini-2.5-deep-think\",
messages=[
{\"role\": \"user\", \"content\": \"证明:对任意素数 p>3,p^2-1 必能被 24 整除。\"}
],
)
print(resp.choices[0].message.content)
Co-Mathematician 本身作为完整 Agent 系统暂未开放接口,目前能直接用上的是它的底座模型。
一个更大的趋势
把这次发布放在过去半年的时间线里看,方向已经很清楚:
- OpenAI 押注 GPT-5.5 Pro 的"通用 reasoning"
- Anthropic 在 Claude 上死磕 agentic coding
- Google 选择垂直科研 Agent——AlphaFold、AlphaEvolve、Co-Mathematician 是一条线
DeepMind 这条路线的优势在于:科研场景的 verifier 容易构造(数学有 Lean、生物有湿实验、算法有 benchmark),强化学习信号干净,比通用 Agent 那种"让 LLM 评 LLM"靠谱得多。这也是为什么他们能在 FrontierMath 这种硬指标上持续拉开差距。
陶哲轩去年说过一句话,大意是:等 AI 能独立提出一个有意义的数学猜想,那才是真正的转折点。Co-Mathematician 还没到那一步——它仍然需要人类给出问题方向。但从"答题"到"协作探索",这一步谷歌已经迈出去了。
参考来源
- linux.do 社区讨论:AI Co-Mathematician 在 FrontierMath Tier-4 碾压 GPT-5.5 Pro - 国内开发者社区的第一手讨论与跑分截图