MoE 不只是省算力,它还藏着模型的"模块化基因"
5 月初,AllenAI 在 HuggingFace 博客上挂出了一篇名为 EMO(Pretraining Mixture of Experts for Emergent Modularity) 的工作。名字听上去又是一个 MoE 变体,但读完会发现,作者想讲的不是"我又训了一个稀疏大模型",而是一个更底层的问题:大模型在预训练过程中,到底有没有自发地长出"功能分区"?如果有,能不能用 MoE 把这件事显式化、可控化?
这个角度比单纯卷参数规模有意思得多。过去两年 MoE 的叙事几乎被 Mixtral、DeepSeek-V3、Qwen-MoE 这些工作绑死在"等效算力下做更大模型"的工程路线上,专家被当成纯粹的容量扩张工具。EMO 把视角拉回到了 2017 年那批关于"条件计算"和"模块化神经网络"的老问题——专家应该对应能力,而不只是对应 FLOPs。
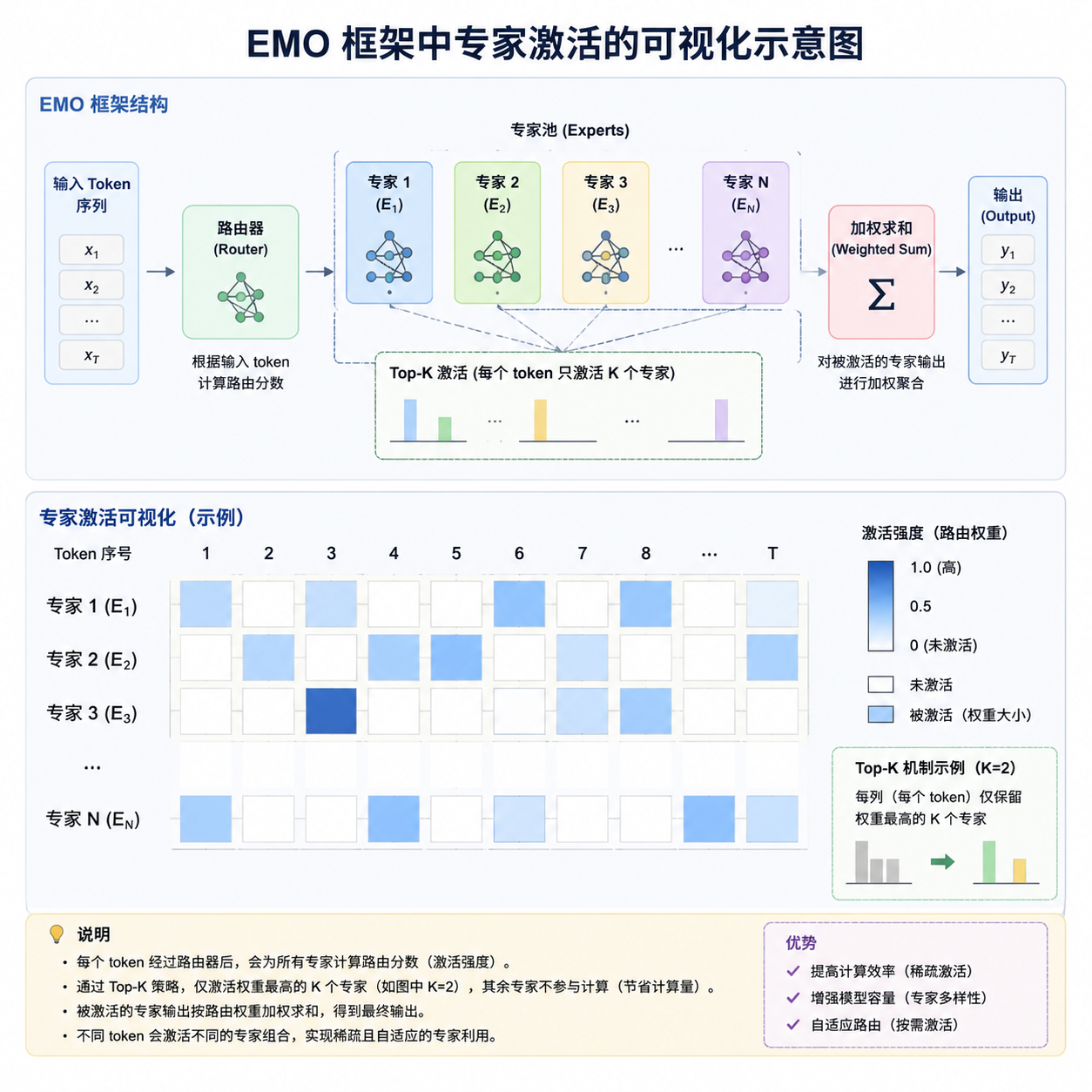
EMO 在做什么:把"涌现模块化"当成训练目标
按 AllenAI 的描述,EMO 的核心主张可以拆成三句话:
- 稠密 Transformer 在预训练后期,FFN 层的神经元已经表现出明显的功能聚类——某些神经元只对代码激活,某些只对多语言文本敏感,某些只对数学符号响应。这件事在 2022 年的 Skill Neurons、2023 年的 MoEfication 等工作里已被反复验证。
- 既然这种"模块化"是涌现的,那与其等它自己长出来再去后处理(MoEfication 的思路是把训练好的稠密模型切成 MoE),不如在预训练阶段就用 MoE 结构去引导、放大这种模块化倾向。
- 衡量模块化不能只看路由分布是否均匀(传统 MoE 的 load balancing 关心的事),还要看同一个专家是否稳定地对应同一类语义/任务。EMO 因此引入了一组新的评估指标,专门看专家的"功能特异性"。
这套思路里,传统 MoE 训练中那个让人头大的 auxiliary loss(鼓励专家负载均衡的辅助损失)反而成了反派——它强行把 token 平均分给所有专家,会破坏自然形成的功能聚类。EMO 的处理方式是放松均衡约束,转而用一种基于互信息的目标,鼓励专家之间在表征上分化、在功能上互补。
技术细节:路由、损失和专家粒度
从博客披露的细节看,EMO 的几个关键设计值得拆开说。
1. 细粒度专家 + 共享专家
EMO 沿用了 DeepSeekMoE 那一脉的设计——把每个专家切得更小、数量更多,再额外保留一两个"共享专家"处理通用知识。粗粒度专家(比如 Mixtral 的 8 个)很容易退化成"每个专家都什么都会一点",模块化无从谈起;细粒度(几十到上百个)才有空间让不同专家走向不同的功能特化。
共享专家的存在则是一个工程妥协:语言模型里总有一部分计算是跨任务通用的(语法、常见词的嵌入处理),把这部分单独剥离出来,能让稀疏专家更专注于"差异化"的能力。
2. 互信息驱动的辅助目标
这是 EMO 跟传统 MoE 最本质的差别。Switch Transformer、GShard 用的 load balancing loss 本质是熵正则——希望路由分布尽量平均。EMO 把目标改成:
- 同一个专家在不同 token 上的激活模式应该有较高的内部一致性(专家内聚)
- 不同专家之间的激活模式应该尽量正交(专家解耦)
这个目标更接近经典的聚类损失,而不是负载均衡。代价是工程上更难训稳定——容易出现"赢家通吃"的退化解,需要配合温度调度和 router 初始化的技巧。
3. 模块化的可量化评估
EMO 提出用一组探针任务(代码、数学、多语言、常识推理等)去测每个专家的激活分布,得出一个"专家-能力"对应矩阵。如果矩阵越接近置换矩阵(每个专家对应一个能力簇),就认为模块化程度越高。
这套评估其实补上了 MoE 研究长期以来的一个空白:大家都说 MoE 有专家分工,但很少有人系统地证明分工真的存在、且对应人类可理解的能力维度。
为什么这件事值得关注
站在 2026 年这个时间点回看,MoE 已经是主流大模型的默认选项。DeepSeek-V3、Qwen3-MoE、Llama 4 Maverick 全是稀疏架构,参数规模动辄几千亿、激活几十亿。但工程上的成熟掩盖了一个尴尬的现实:我们对"专家在学什么"几乎一无所知。路由可视化大多停留在"专家 3 喜欢标点符号"这种层面,离真正的可解释性、可控制性还很远。
EMO 的价值不在于刷了某个 benchmark,而在于它把"模块化"重新放回了 MoE 的研究中心。这件事至少有三层潜在价值:
- 可解释性:如果专家真的对应清晰的能力,那么我们终于有了一个比 attention 可视化更可靠的"模型内部地图"。
- 可编辑性:模块化意味着可以做"能力级别的手术"——禁用某个专家来削弱模型的某种能力(比如关闭"代码专家"做安全测试),或者针对性微调某几个专家来增强特定能力,而不必动全模型。
- 持续学习:模块化结构天然适合增量训练,新增能力可以体现为新增专家,而不是覆盖旧权重,这对一直没解决好的灾难性遗忘问题是个潜在突破口。
一些保留态度
当然,话不能说太满。EMO 目前披露的实验规模并不大,主要在百亿级别参数上做对比,跟 DeepSeek-V3 那种 6710 亿总参的实战级 MoE 不在一个量级。互信息正则在小模型上 work,到了千亿级别还能不能稳住,要打个问号。
另一个隐忧是模块化和性能可能存在 trade-off。强行让专家功能分化,可能会牺牲一部分稠密模型才有的"特征复用"——很多能力本来就是交叉的(数学推理用到语言能力,代码生成用到逻辑),强切反而损害效果。AllenAI 的博客里坦承在某些综合任务上 EMO 略逊于同等规模的标准 MoE,这一点没有藏着掖着,算是科研态度上的加分项。
还有个现实问题:业界目前对 MoE 的优化都是围绕"均衡负载 + 高吞吐推理"这条路线建的,从 vLLM 到 SGLang 到 TensorRT-LLM,所有 expert parallelism 的实现都默认负载分布大致均匀。EMO 这种刻意打破均衡的训练,会让推理侧的专家分布变得倾斜,对部署不太友好。这是个工程问题,但不是小问题。
跟同期工作的关系
EMO 不是孤立出现的。把它放回 2025-2026 年这一年的 MoE 研究脉络里看会更清楚:
- DeepSeek 系列:把细粒度专家和共享专家工程化到极致,重点是训练稳定性和推理效率。
- Qwen3-MoE:在路由策略上引入了更多上下文感知,但仍然是性能导向。
- Anthropic 的可解释性研究:从 SAE(稀疏自编码器)路线切入,从外部探测稠密模型的特征,跟 EMO 的"内生模块化"是两条路径。
- EMO:把可解释性目标内化到预训练阶段,是这两条路径之间的桥梁。
粗暴一点说:DeepSeek 关心 MoE 怎么训得更快,Anthropic 关心模型在想什么,EMO 想同时回答这两个问题。
给开发者的几点提示
如果你在做 MoE 相关的工程或研究,EMO 这套思路有几个可以借鉴的点:
- 即便不照搬互信息损失,也可以在训练后期适度放松 load balancing 的权重,观察专家是否会自发分化。
- 评估 MoE 时别只看 perplexity 和 benchmark,加一组探针任务去看专家的功能分布,能发现很多隐藏问题。
- 细粒度专家 + 共享专家的组合在工程上已经被验证过,没用上的话可以试试,对小规模 MoE 提升明显。
- 如果做模型编辑、安全对齐、能力剥离这类任务,模块化更强的 MoE 是更好的实验对象,比稠密模型可操作性高一个数量级。
EMO 模型权重和训练代码都已经在 HuggingFace 上开放,规模适合单机或小集群复现,是个不错的研究起点。
写在最后
MoE 走到今天,工程上已经走得很远,但理论和可解释性的进展明显落后。EMO 不是那种会上头条的工作——它不刷榜,不秀参数规模,甚至在某些指标上还略输——但它把一个被忽视的问题重新摆上了桌面:我们到底想从 MoE 里得到什么?仅仅是更便宜的算力,还是更结构化的智能?
这个问题没有标准答案,但能问出来,本身就有价值。
参考来源
- EMO: Pretraining mixture of experts for emergent modularity (HuggingFace Blog) — AllenAI 在 HuggingFace 发布的 EMO 框架原始博客,含技术细节与实验结果
- 混合专家模型 (MoE) 详解 (HuggingFace) — MoE 基础架构、路由机制与训练技巧的系统性中文综述
- 一文读懂:混合专家模型 MoE (知乎) — MoE 核心组件与代表性工作的中文解读
- 深度解读大语言模型中的混合专家架构 (知乎) — 从历史脉络梳理 MoE 思想演进的长文