文心5.1发布:6%的训练成本,凭什么登顶?

百度今日发布文心大模型5.1,采用多维弹性预训练技术,将预训练成本压缩至业界同规模模型的6%,登上LMArena搜索榜国内第一、全球第四,Agent能力超越DeepSeek-V4-Pro。
文心5.1发布:6%的训练成本,凭什么登顶?
百度今天(5月9日)正式发布了文心大模型5.1。
一句话概括:参数量砍到上一代的三分之一,激活参数砍到一半,预训练成本只有业界同规模模型的6%——然后它还登上了 LMArena 搜索榜国内第一、全球第四。
这个数字足够刺眼。在各家都在卷算力、卷参数规模的今天,百度选了一条反方向的路:用更少的资源,做出更强的模型。不管你信不信它的 benchmark,"6%"这个数字本身,已经足以让整个行业重新审视预训练效率这件事。
先说清楚:6% 到底什么概念
大模型预训练是整个模型生命周期中最烧钱的环节,没有之一。动辄数千张GPU跑几个月,电费、机器折旧、人力加在一起,头部模型的单次预训练成本已经奔着数亿美元去了。
百度声称文心5.1的预训练成本只有"业界同规模模型的约6%"。换个更直观的说法:别人花100块钱训出来的东西,百度说自己只花了6块钱,而且效果还更好。
这个"6%"的底气来自一项叫**"多维弹性预训练"**的技术。
这项技术并不是5.1才有的——它在文心5.0时代就已经提出,核心思路是一次训练,生成多种规模的模型。传统做法是每个规模的模型各训一遍,大模型训一次、中模型训一次、小模型再训一次。多维弹性预训练把这个过程合并了:在一次大规模训练中,同时产出不同参数量的模型变体。
这听起来有点像模型蒸馏,但又不完全一样。蒸馏是先有一个训好的大模型当"老师",再训小模型当"学生"。多维弹性预训练更像是一个"弹性训练框架"——训练过程本身就是多尺度的,不同规模的模型共享同一套训练基础设施和数据流。
文心5.1在此基础上进一步压缩:
- 总参数量:压缩至文心5.0的约 1/3
- 激活参数量:压缩至约 1/2
- 预训练算力成本:仅为业界同规模模型的 6%
而且百度明确表示,文心5.1"充分继承了文心5.0的知识"。也就是说,这不是从零开始训练,而是在5.0的基础上做高效迭代。这也解释了为什么成本能压得这么低——它本质上是5.0投资的延续和放大。
当然,"6%"这个数字的参照系很关键。百度说的是"业界同规模模型",但没有明确对标的是哪个模型、什么参数规模。如果对标的是GPT-4级别的万亿参数模型,那6%确实惊人;如果对标的是一个中等规模的开源模型,那意义就不太一样了。这一点,还需要百度在5月13日的开发者大会上给出更透明的数据。
LMArena 排名:搜索榜全球第四,文本榜超越GPT-5.5
先科普一下 LMArena。这是目前行业公信力最高的大模型评测平台之一,采用真实用户盲测的方式:随机给用户展示两个模型的回答,用户不知道哪个是哪个模型,凭体验投票。最终按 Elo 评分排名。
相比各家自己刷的 benchmark,LMArena 的评测更接近真实使用场景。
文心5.1这次在 LMArena 上的表现分两条线:
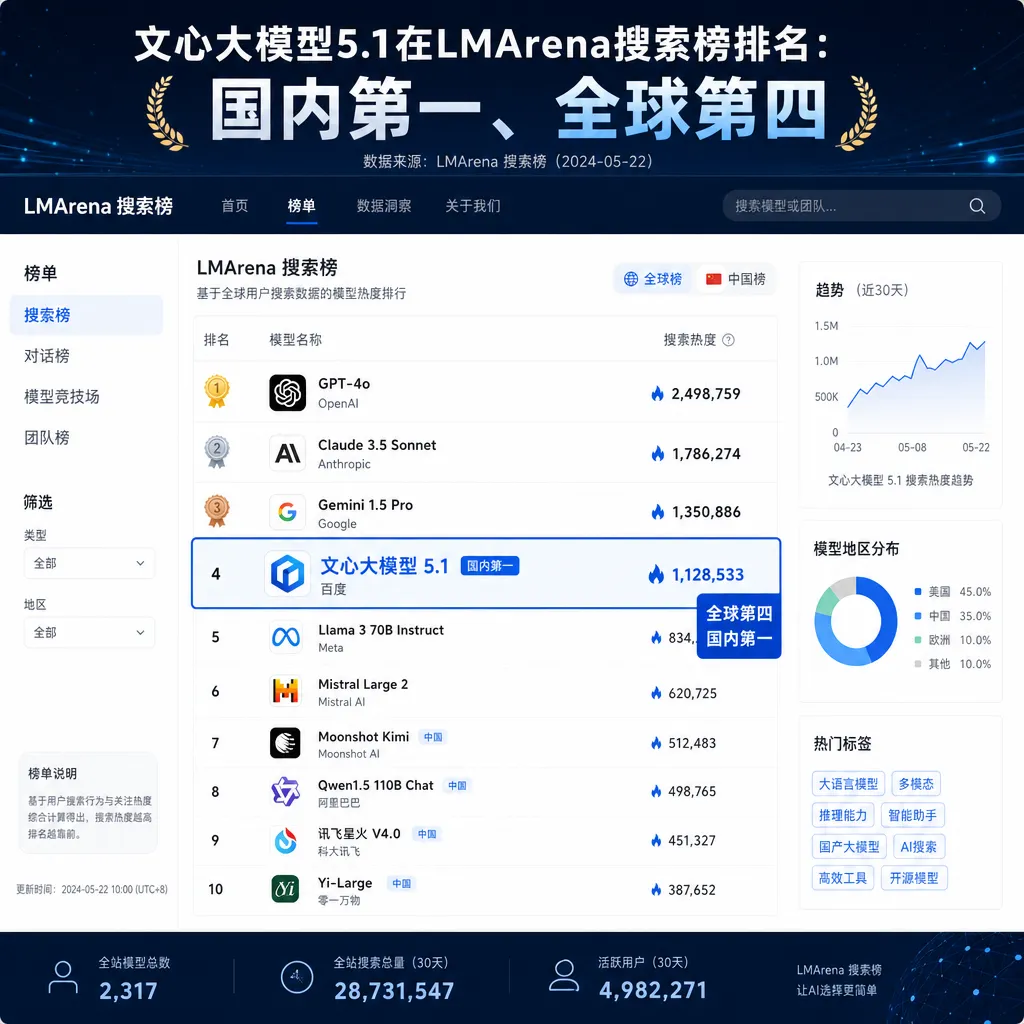
搜索榜:1223分,国内第一、全球第四
这里的"搜索能力"不是指传统的网页搜索,而是指模型对多源信息的快速检索、整合与生成能力。简单说,就是模型在回答问题时,能不能从海量信息中找到关键内容、把它们组织成一个连贯、准确、有条理的回答。
这是百度的看家本领。搜索引擎做了二十多年,积累的信息检索能力如果不能在大模型时代变现,那才是真正的浪费。文心5.1在搜索榜上拿到国内第一并不意外,但全球第四——超过了大量国际选手——还是值得注意的。而且它是榜单上唯一的国产模型。
对开发者来说,搜索能力强意味着什么?意味着在 RAG(检索增强生成)场景下,这个模型可能天然就有优势。你不需要花那么多精力在检索链路的优化上,模型本身就能更好地理解和整合检索结果。
文本榜:5.1 Preview 1476分,国内第一
在更早的4月30日,文心5.1 Preview版本已经在 LMArena 文本榜上拿到了1476分,排名国内第一。超越的对手包括 DeepSeek-V4-Pro 和 GPT-5.5——这两个都是目前各自阵营中的旗舰级模型。
超越 GPT-5.5 这一点需要谨慎看待。LMArena 的 Elo 评分基于用户投票,不同类型的问题、不同的用户群体都会影响结果。在某些特定能力维度上,GPT-5.5 可能仍然领先。但至少在综合文本体验上,文心5.1已经具备了与顶级闭源模型正面竞争的实力。
具体能力拆解:Agent 是最大亮点
百度官方给出了几个能力维度的对比,我挑几个关键的聊:
Agent 能力:超越 DeepSeek-V4-Pro
这是百度这次宣传的重点。Agent 能力指的是模型自主完成复杂任务的能力——包括工具调用、多步推理、任务规划、异常处理等。
如果说普通的问答是"你问我答",Agent 场景就是"你给我一个目标,我自己想办法完成"。比如:
- "帮我查一下最近三个月的销售数据,生成趋势图,然后写一份分析报告发到邮箱"
- "监控这个 API 的响应时间,如果超过阈值就自动扩容并通知运维"
这类任务需要模型具备规划、执行、反馈、调整的完整闭环能力。DeepSeek-V4-Pro 在这方面已经相当强了,文心5.1能超越它,说明百度在 Agent 方向上确实下了功夫。
对开发者来说,这意味着如果你在构建 AI Agent 应用——不管是企业内部的自动化助手还是面向用户的智能体——文心5.1值得纳入你的候选列表。
创意写作:与 Gemini 3.1 Pro 相当
写作能力一直是中文模型的传统优势领域。百度称文心5.1的创意写作能力与 Google 的 Gemini 3.1 Pro 相当。考虑到 Gemini 3.1 Pro 本身在写作方面就属于第一梯队,这个评价不低。
不过"相当"这个词本身也很微妙——它意味着没有明显领先。在中文写作场景下,一个中国公司的模型跟 Google 的模型打平手,并不算特别亮眼的成绩。
推理能力:接近业界领先闭源模型
注意用词是"接近"而非"超越"或"持平"。推理能力(尤其是数学和代码推理)一直是国产模型的相对短板,百度用"接近"来描述说明有进步但也承认差距。
这种诚实反而比盲目宣称"全面领先"要让人觉得靠谱。
技术路线的深层逻辑:效率优先
如果跳出文心5.1这个具体产品,看百度最近一年的技术路线,会发现一个非常清晰的主线:不比参数比效率。
去年各家都在卷万亿参数,百度也在卷,但它同时布局了多维弹性预训练。到了5.1这一代,这套技术开始兑现回报——用更少的参数、更低的成本,达到甚至超越更大模型的效果。
这个思路其实和 DeepSeek 的 MoE(混合专家)架构有异曲同工之处:都是在追求单位算力的最大产出。不同的是,DeepSeek 的 MoE 更多是在模型架构层面做文章(稀疏激活),而百度的多维弹性预训练更多是在训练方法论层面做文章。
哪种路线更有前途?目前看不出定论。但有一点可以确定:纯粹靠堆算力的时代正在过去。当训练成本成为所有玩家都不得不考虑的约束条件时,训练效率就是核心竞争力。
这一点对中国的大模型公司尤其重要。在高端芯片供给受限的背景下,"用更少的算力做更多的事"不是可选项,而是生存需要。
对开发者意味着什么
文心5.1已经在百度千帆模型广场和文心一言官网上线,企业用户和开发者可以直接体验。
从实际使用角度,开发者需要关注几个问题:
1. 推理成本
参数量压缩到原来的1/3,激活参数减半——这直接意味着推理成本大幅下降。对于需要大规模调用 API 的场景,这可能是比性能提升更有吸引力的点。模型能力再强,如果每次调用的成本让你的商业模式跑不通,那也没用。
百度官方博客也明确提到,文心5.1"相对文心5.0显著降低了推理成本"。具体降了多少,还需要等正式的定价方案出来。
2. 搜索增强场景
如果你的应用涉及大量的信息检索和整合(比如企业知识库问答、新闻摘要、竞品分析),文心5.1的搜索能力可能会给你带来惊喜。LMArena 搜索榜全球第四不是白拿的。
3. Agent 开发
如果你正在做 AI Agent,文心5.1在这方面超越 DeepSeek-V4-Pro 的表现值得重视。建议做一轮横向评测,特别是在工具调用的准确性和多步任务的完成率这两个维度上。
4. 模型选型建议
现在市面上的选择太多了。GPT-5.5、Claude 4 Sonnet、Gemini 3.1 Pro、DeepSeek-V4-Pro、文心5.1……每个都说自己某某方面最强。
我的建议是:别看 benchmark,看你的真实场景。拿你自己的 prompt、你自己的数据,在几个模型之间做 A/B 测试。LMArena 的排名是参考,不是答案。
如果你不想一个个去对接不同厂商的 API,也可以考虑通过 OpenAI Hub 这样的聚合平台来做横向对比——一个 Key 就能调 GPT、Claude、Gemini、DeepSeek 等主流模型,省去逐个注册的麻烦。
一些值得追问的问题
百度这次发布的信息虽然不少,但还有几个关键问题没有回答:
1. "6%的预训练成本"的基线是什么?
6%听起来很震撼,但如果不知道是跟谁比、在什么参数规模下比,这个数字的含金量就打了折扣。是跟 Llama 3 比?跟 GPT-4 比?还是跟某个假想的"业界标准"比?
2. 模型的具体参数规模是多少?
百度只说了"总参数压缩至5.0的1/3",但5.0的参数量也没有公开过。这就形成了一个"未知数的1/3还是未知数"的尴尬局面。
3. 是否会开源?
在 DeepSeek 和 Qwen 都在积极开源的大环境下,百度的文心系列一直保持闭源。这次5.1会不会改变策略?从目前的信息看,暂时没有开源的迹象。
4. 多模态能力如何?
这次的发布主要聚焦文本能力,多模态(图像理解、视频生成等)方面的信息几乎没有。考虑到文心5.0曾在 LMArena 视觉理解榜上有过不错的表现,5.1在这方面的进展值得关注。
这些问题,可能要等到5月13-14日的 Create 2026 百度AI开发者大会 才能得到解答。届时李彦宏将亲自出场演讲,预计会披露更多技术细节和商业化落地规划。
写在最后
文心5.1不是一个"从天而降"的产品——它是百度在多维弹性预训练这条技术路线上持续投入的阶段性成果。从5.0提出方法论,到5.1 Preview验证效果,再到今天的正式发布,这条路线走了大半年,终于拿出了一个相对完整的答卷。
6%的预训练成本、1/3的参数量、LMArena多榜登顶——这些数字组合在一起,讲的是同一个故事:大模型竞赛正在从"谁更大"转向"谁更高效"。
这对整个行业是好事。当大家开始比拼效率而非单纯堆资源时,意味着大模型的普及门槛在降低。今天只有大厂玩得起的训练规模,明天可能中小公司也能负担得起。
至于文心5.1到底有没有它说的那么好,上手试了才知道。模型已经上线,百度千帆的 API 就在那里,是骡子是马,拉出来遛遛。
参考来源
- 百度发布文心大模型5.1:搜索能力位居国内首位,预训练成本仅为业界6% — IT之家原始报道,包含完整的官方信息和 LMArena 排名数据
