蚂蚁百灵甩出万亿参数 Ring-2.6-1T:推理强度从此能拨档
5 月 9 日,蚂蚁集团旗下百灵(inclusionAI)团队正式放出万亿参数旗舰思考模型 Ring-2.6-1T。这是百灵在 Ring 系列上的一次大跳跃——不仅参数规模迈进万亿俱乐部,还在工程上做了一件挺务实的事:把"思考多深"这件事做成了一个可拨的档位。
模型今天同步上线 OpenRouter,限时一周免费体验,官方还预告"近期开源"。对国内开发者来说,这是继 Qwen3、DeepSeek-V3.2、GLM-4.6 之后又一个能掰着手腕跟头部闭源模型比划的开源候选。
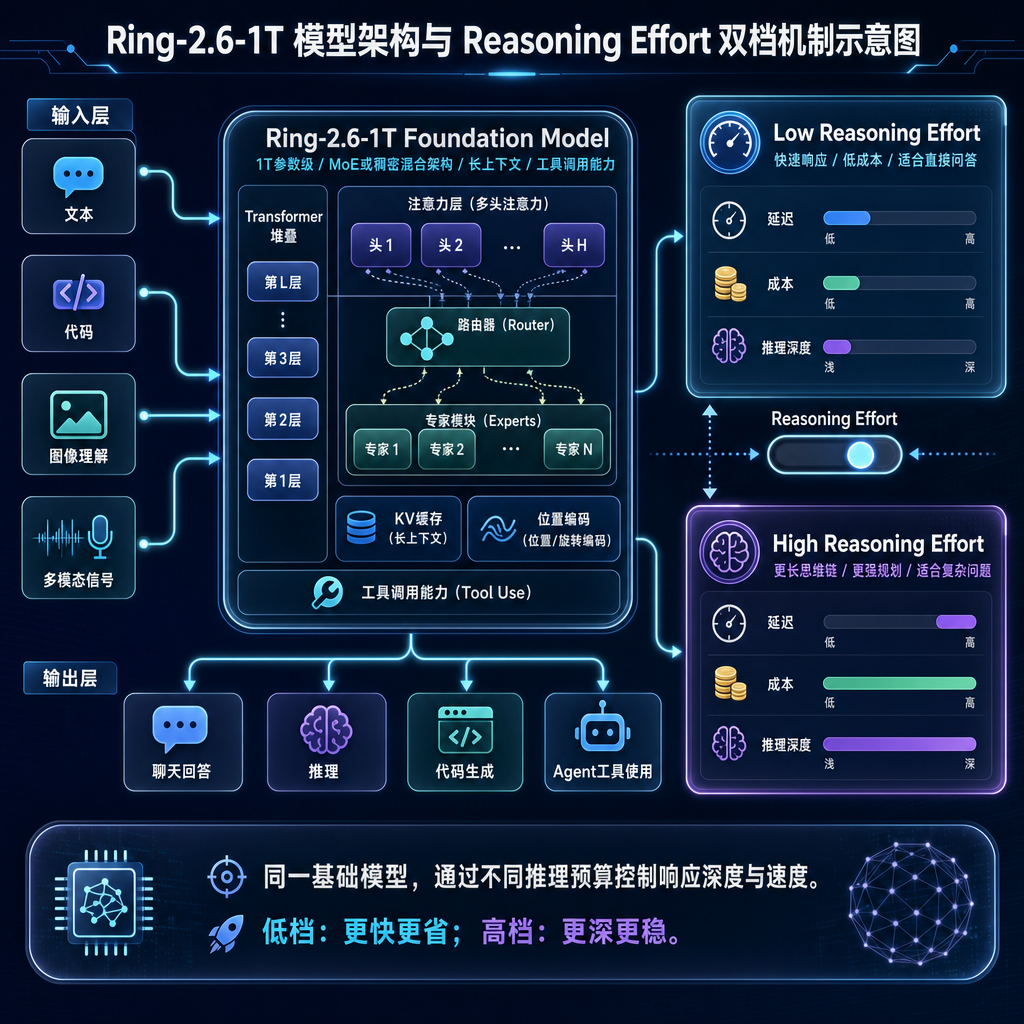
不是又一个万亿模型,重点在"可调"
过去一年,"思考模型"(reasoning model)这条线已经跑出了清晰的范式:让模型在输出最终答案前先生成一段长 CoT,用算力换准确率。OpenAI 的 o 系列、Gemini 3 的 Deep Think、DeepSeek-R1 都是这套打法。
问题也很明显——思考长度不可控。给模型一个 "1+1=?",它能给你想出三千个 token 的分支证明;上一个 Agent 工作流,每一步工具调用都过一遍长链推理,Token 成本和延迟都顶不住。OpenAI 后来在 API 里加了 reasoning_effort 参数(low/medium/high),算是给这事开了个头。
Ring-2.6-1T 直接把这个理念做成了核心卖点,提供两档:
- high:面向高频 Agent 工作流,Token 开销更低、多步执行更快,适合多轮交互、工具协作、任务拆解,定位是"生产级默认调用"。
- xhigh:面向数学、科研、复杂逻辑分析、多路径探索这类高难任务,给模型更充分的思考空间。
这种分档不是简单的 max_tokens 截断,而是模型在训练阶段就被明确教过两种"思考节奏"。换句话说,high 档不是 xhigh 档的"阉割版",而是专门优化过的"短思考稳态"——这一点在 Agent 场景里非常关键,因为 Agent 链路里最怕的就是某一步突然飘出几千 token 的内心戏,把整条链路的预算和延迟打穿。
跑分:high 档敢和别人 xhigh 档掰手腕
官方放出的评测数据有点意思,分两档对比着看:
high 档(Agent 与工程场景)
- PinchBench:87.60,官方称超过 GPT-5.4 xHigh 与 Gemini-3.1-Pro high
- ClawEval:63.82
- Tau2-Bench Telecom:95.32
Tau2-Bench Telecom 这个分挺值得说一句。这个 benchmark 模拟的是电信客服场景下的多轮工具调用,是目前业内公认比较接近真实生产 Agent 场景的评测。95.32 已经是头部水平,意味着在多步工具协调、状态保持上 Ring-2.6-1T 不是只会刷数学题。
xhigh 档(高难推理)
- ARC-AGI-V2:77.78
- AIME 26:95.83
- GPQA Diamond:88.27
AIME 26 接近 96 分基本是把高中数学奥赛题做穿了,GPQA Diamond 88+ 也已经站到第一梯队。ARC-AGI-V2 的 77.78 更值得关注——这个测的是抽象模式归纳,是 LLM 历来比较吃力的能力维度。
当然,跑分这事永远要打个折看。但如果 high 档真能在 Agent 类评测上稳住、xhigh 档真能在数学/科研题上贴近 SOTA,那 Ring-2.6-1T 的"双档"就不只是 marketing 话术,而是两种真实可用的工作模式。
为什么"双档"这件事比参数更重要
聊一点判断。万亿参数本身在 2026 年已经不算稀奇,Kimi K2、DeepSeek V3 系列、Qwen3-Max 都在这个量级附近徘徊(虽然激活参数各不相同)。真正稀缺的是让一个模型在不同任务节奏下都好用。
现在做 Agent 应用的开发者基本都遇到过同一个尴尬:
- 用强推理模型,每一步都过 CoT,跑一个 ReAct 循环动辄几十秒、几万 token
- 切换到普通 chat 模型,遇到需要规划的步骤又掉链子
- 折中方案是双模型路由——简单步骤走 fast,复杂步骤走 thinking——但工程复杂度立刻起飞
Ring-2.6-1T 的 high/xhigh 是把这个路由器做进了模型内部。开发者不用维护两套模型 endpoint,也不用自己写复杂度判别器,调用时切个参数就行。这个产品决策很"做过 Agent"——它不是在跟 GPT-5 比 GPQA,而是在跟你的生产环境账单较劲。
怎么用:OpenRouter 限免一周
现在能用上 Ring-2.6-1T 有两个路径:
- OpenRouter:模型 ID
inclusionai/ring-2.6-1t:free,限时一周免费 - 等开源:官方明确说近期会在 inclusionAI 的 GitHub/HuggingFace 开源
调用上,Reasoning Effort 通过标准 reasoning_effort 参数指定,传 high 或 xhigh。建议先用 high 跑一遍你的 Agent 主链路,遇到 hard case 再升档到 xhigh,对照看下 token 消耗和成功率的曲线——这是最能感受到"双档"价值的姿势。
OpenAI Hub 这边也在跟进上架进度,开源版本放出后会第一时间接入,届时可以用统一的 OpenAI 兼容格式直接切换。
几个还没回答的问题
几点需要在后续实际使用中观察:
- 激活参数与推理成本:万亿总参,Ring 系列此前是 MoE 架构,激活参数没在通稿里强调。这直接决定了开源后社区能不能负担得起本地部署。
- 上下文长度:通稿没提具体的 context window,Agent 场景下 256K 是当下的合理门槛。
- 工具调用格式:是否原生支持 function calling、parallel tool use,是 Agent 落地的关键细节。
- xhigh 是否真的稳定:长 CoT 模型最怕的是"想得多但绕回错误答案",这点要靠社区在开源后跑大量 benchmark 才能验证。
小结
Ring-2.6-1T 不是一次惊天动地的发布,但它代表了国内大模型团队的一种成熟——开始关心开发者真实生产环境里的痛点,而不是只盯着 leaderboard。Reasoning Effort 双档机制是把"思考"这件事工程化的合理一步,配合即将到来的开源,会给 Agent 开发者多一个有竞争力的选项。
限免就一周,建议这周就把它接进自己的 Agent 测试框架里跑一遍,体感会比看跑分直接得多。
参考来源
- IT之家:蚂蚁集团百灵发布万亿级旗舰思考模型 Ring-2.6-1T — 首发报道,含 Reasoning Effort 机制与 OpenRouter 体验地址
- IT之家移动版同稿 — 同上内容移动端版本