大模型推理,到了该「开多线程」的时候
过去一年,整个行业都在卷推理时计算(test-time compute)。从 OpenAI 的 o1、o3 到 DeepSeek-R1,再到各家的 thinking 模式,主流路径只有两条:要么把思维链(CoT)拉得更长,让模型一条道走到黑;要么用 self-consistency 这种「多路采样投票」的方式,让 N 个独立线程各跑各的,最后选个出现次数最多的答案。
两条路都不优雅。前者受限于上下文窗口和延迟,错了得回溯一大段;后者纯粹是「人海战术」,线程之间互不通气,重复劳动严重。UC Berkeley 和 UCSF 的团队最近把这件事拆开重做了一遍——他们的论文《Learning Adaptive Parallel Reasoning with Language Models》(arXiv:2504.15466)提出了 Adaptive Parallel Reasoning(APR),配合 BAIR 博客最新发布的系统侧分析,思路开始清晰:让模型自己学会什么时候该开线程、开几个、怎么 join。
这件事对做 Agent 和复杂推理产品的开发者来说,比单纯的「又一个新基准 SOTA」要更有意义。
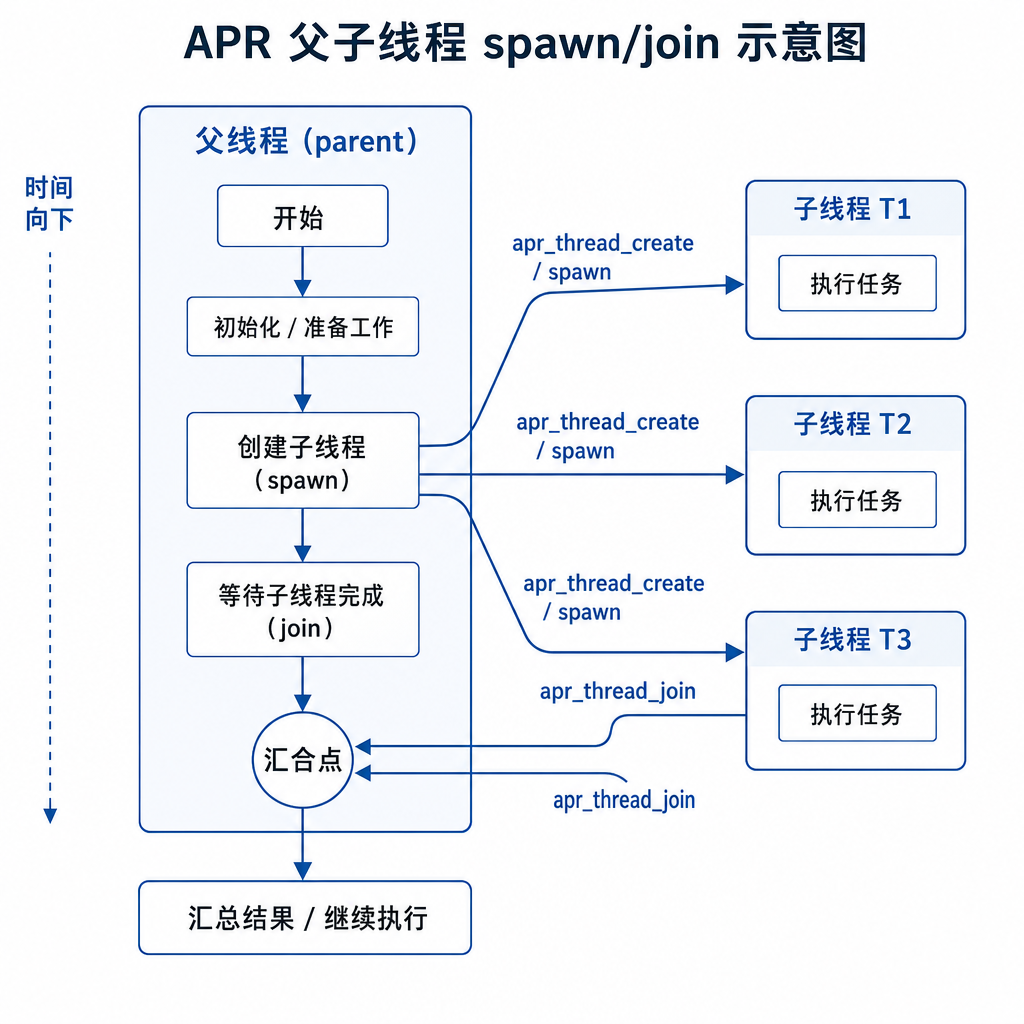
APR 在做什么:把 map-reduce 写进解码过程
APR 的核心抽象其实很程序员友好——它把推理过程视作一次 map-reduce:
- spawn():父线程在解码途中,可以随时把当前问题分叉成若干子任务,每个子任务作为一个独立的子线程并发执行;
- join():所有子线程跑完后,把结果汇总回父线程的上下文,父线程基于这些结果继续解码或再次 spawn。
这跟 self-consistency 的根本区别在于:子线程的结果不是用来投票的,而是作为父线程的「调研材料」回流到主推理流。父线程拥有协调权,可以决定要不要再开一轮、要不要换个角度。
用项目经理来类比比较直观:CoT 是一个人埋头干到底;self-consistency 是十个人各干各的,最后看谁举手的多;APR 则是一个 PM 在干活过程中,临时拉几个同事去并行调研子问题,拿到反馈后再决定下一步。
关键是,「什么时候该 spawn、开几个子线程」不是预先写死的规则,而是模型通过端到端强化学习自己学出来的。这是它和 Tree-of-Thoughts、ReAct 之类外部编排框架的最大差别——APR 把控制流烧进了模型权重里。
数据:在相同延迟下,准确率高出近 18 个点
团队在 Countdown 任务(用 4 个数字凑出目标值,类似 24 点的扩展版)上做了对照实验,几个数字值得看:
- 同等上下文窗口(4k):APR 准确率 83.4%,传统串行 CoT 60.0%;
- 同等总 token 预算(20k):APR 80.1%,串行 66.6%;
- 同等延迟(约 5000ms):APR 75.2%,串行 57.3%。
第三组数据是最有工程价值的——在生产环境,用户不在乎你烧了多少 token,只在乎要等多久。APR 通过把计算横向铺开到并发线程上,实质是用「带宽换延迟」,这和 GPU 推理引擎本身的并发能力天然契合。
还有一个有意思的观察:经过 RL 优化后,模型自发地选择「加宽度而非加深度」。子线程平均数从 6.1 涨到 8.2(+34%),单线程长度只从 1471 涨到 1796 token(+22%)。换句话说,模型自己悟出来:与其在一条思路上钻得更深,不如多开几条短的。这跟人类专家解难题时「先发散、再收敛」的直觉是一致的。
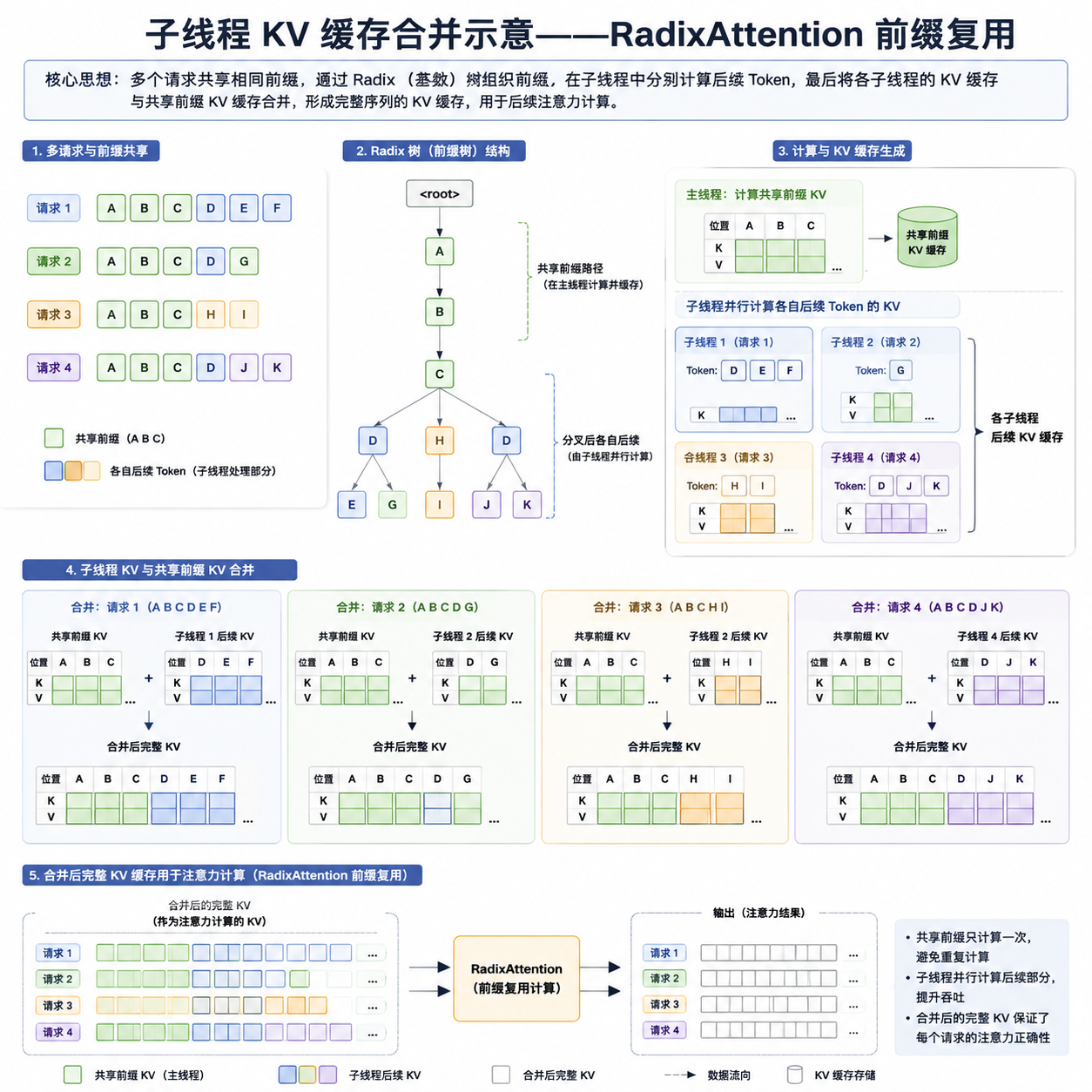
系统侧的硬骨头:KV 缓存怎么合并
APR 的算法部分其实不算复杂,难的是推理引擎怎么配合。BAIR 博客这次把系统层的坑讲得很明白,开发者如果自己想复现,绕不开这一段。
问题出在 join 阶段。每个子线程是作为独立请求送进推理引擎的,它们:
- 共享同一个前缀(父线程 spawn 时给的子任务列表);
- 从相同的 position id 开始解码;
- 互相之间没有 attention。
等子线程跑完要 join 回父线程时,麻烦来了:直接把这些 KV cache 拼起来,会出现 position id 重叠、非因果的 attention 模式——而这些模式是基模型在训练时从未见过的,硬塞进去结果会很难看。
社区目前分两派解法:
派别一:改推理引擎(Multiverse 路线)
Multiverse(Yang et al., 2025)的做法是直接动 SGLang 这类推理引擎的内存管理。它借助 RadixAttention 的前缀树(radix tree)机制,让所有子线程共享前缀的 KV cache,不再为每个子线程重复 prefill。子线程结束后,引擎在拼接阶段复用这些独立线程的 KV,配合 position id 的重映射和 attention mask 的修正,让合并后的序列对基模型来说看起来是「合法的」。
好处是性能极致——前缀只算一次,KV 不重算;代价是你得改引擎,对 vLLM/SGLang 不熟的团队门槛不低。
派别二:绕过引擎(应用层方案)
另一派思路是不动引擎,把 join 过程放在应用层做:子线程结果转成文本塞回父线程上下文,重新 prefill 一遍。胜在通用,任何兼容 OpenAI 格式的 endpoint 都能跑;代价是 KV 全部重算,token 消耗和延迟都更高。
对大多数业务团队,第二种路线起步更现实——先用 APR 的训练范式拿到模型,部署时哪怕牺牲点效率也能马上吃到准确率红利。等场景稳定了,再考虑要不要下沉到引擎层做 Multiverse 式优化。
跟最近几篇相关工作的对照
把 APR 放到 2025-2026 年这一轮推理范式的演进里看,会更清楚它的位置:
- ALPHAONE(α1):偏向于在测试时调节单条推理链的进度——是「调速器」,本质还是串行;
- Multiverse:解决系统层并行推理的工程问题,和 APR 算配套关系而非替代;
- ACE(Agentic Context Engineering,斯坦福/SambaNova/UCB):走的是另一条路——不微调模型,靠「生成-反思-整合」三角色把上下文做成不断演化的作战手册。和 APR 的关系是正交的:APR 改的是模型的推理控制流,ACE 改的是上下文的组织方式,理论上完全可以叠加。
- 南科大 SPPO:把推理训练建模为序列级 contextual bandit,用单次采样替代 GRPO 的多次采样降本。它优化的是 RL 训练效率,APR 优化的是推理时计算的分配方式,两者解决不同环节的问题。
如果说 2024 年的关键词是「让模型想得更久」,那么 2025-2026 这一波的关键词正在变成「让模型想得更聪明地分配自己想的方式」——这是更接近通用智能的方向。
对开发者意味着什么
几个我认为可以马上动手的点:
Agent 框架可以重新设计调度逻辑。现在大多数 Agent 框架(LangGraph、AutoGen 等)的并发是开发者手写的——「这一步去开 3 个 worker」是 hardcode 的。APR 给出的可能性是:让模型自己在合适的位置吐出 spawn token,框架只负责执行。这会大幅简化 multi-agent 编排代码。
复杂任务的延迟优化有新抓手。代码生成、长文档分析、数学/科研推理这类任务,原来想压延迟只能换更小的模型或上推测解码。现在可以从「推理图结构」层面做优化——并行的归并行,串行的归串行。
训练侧的 RL 信号需要重新设计。APR 用的是端到端 RL,奖励函数不仅看最终答案对错,还得引导模型学会合理的 spawn 策略。从论文披露的细节看,初始还需要用符号求解器生成的轨迹做监督预训练,未来 R1-Zero 式的纯 RL 路线值得关注。
开源生态可以参与。代码和数据已经开源(github.com/Parallel-Reasoning/APR),目前主要在 Countdown 任务上验证,扩展到代码、数学竞赛、长文 QA 是显而易见的下一步。如果你手上有合适的 RL 训练 pipeline,这是一个性价比很高的复现方向。
一点判断
我个人的看法:APR 的价值不在 Countdown 那几个百分点的提升,而在于它把「推理控制流」这件事第一次正式地交还给了模型本身。过去我们总是在模型外面套一层编排框架——CoT 是一种编排,ToT 是一种编排,Agent 也是一种编排。APR 在说:这些控制流应该是模型权重的一部分,由 RL 学出来,而不是由开发者拍脑袋写出来。
这一步如果走通,长期看,今天那些手写的 Agent 调度代码、self-consistency 的采样数、ToT 的搜索深度,可能都会变成历史包袱。模型自己知道该怎么思考,是比模型知道得更多更重要的事。
当然,从 paper 到生产还有距离。Countdown 是结构化任务,奖励信号清晰;换到开放域问题,奖励怎么设计、子线程之间要不要支持更复杂的通信协议(不只是 fork-join,还有消息传递、订阅)、KV 合并的工程开销能不能再降——每一项都够再写几篇论文。
但方向是对的。值得盯着。
参考来源
- linux.do:自适应并行推理:高效推理扩展的下一个范例 —— BAIR 博客原文的中文转载,含系统层 KV 缓存合并的完整讨论
- GitHub:Parallel-Reasoning/APR —— 论文官方代码、数据与训练脚本仓库