一个 Skill,把整个 GitHub 塞给 Agent
写代码时让 AI 调一个稍微冷门点的库,结果它一本正经地给你编出几个不存在的 API——这事儿大概每个用过 Cursor 或 Claude Code 的开发者都遇到过。手动贴文档管用,但贴一次烦一次,而且贴了文档还不够,问到底层实现还得再贴源码。
这两天 linux.do 上有个叫 NitroRCr 的开发者把这事儿解决了。他花三天写了个工具叫 gread,打包成 Skill 和 MCP 两种形态,目标很直接:让 Agent 能像本地文件系统一样,按需访问 GitHub 上所有开源仓库的源码和文档。项目已经完整开源在 NitroRCr/gread。
它解决的不是"搜索",是"按需读"
市面上让 AI 读文档的方案不少——Context7、DeepWiki、各种 RAG 文档站。但这些方案大多是把文档预先切片向量化,AI 拿到的是"片段",不是"全貌"。问简单问题够用,问"这个库的事件循环是怎么调度的"就抓瞎。
gread 的思路更接近"给 AI 一把瑞士军刀",让它自己决定怎么读:
- 搜索仓库:先定位到要看哪个项目
- 列出目录树:让 AI 先看整体结构,再决定钻哪个文件
- 代码搜索:在仓库内按关键词、按符号搜
- 读取代码:精确读某个文件、某段代码
这套工具组合下来,AI 的行为模式就跟一个刚入职的工程师阅读陌生代码库差不多——先 tree 一下,再 grep 关键词,最后 cat 文件。这种"探索式阅读"对 Agent 来说远比塞一堆向量片段更自然,也更省 token。
文档自动关联,这点挺聪明
开源项目有个常见结构:代码在主仓库,文档单独放在 xxx-docs 或 website 仓库,甚至挂在独立站点上。AI 读主仓库的时候经常找不到文档,反过来读文档仓库又看不到实现。
gread 在服务端索引仓库时会自动识别对应的文档库,访问主仓库时一并暴露给 AI。换句话说,问 React 的某个 Hook 怎么用,AI 既能看到 react 的源码,也能看到 react.dev 仓库里的官方文档——这俩在 GitHub 上是分开的。这种"主仓库+文档仓库"的合并视图,是同类工具里少见的设计。
安装:两条命令的事
对 Claude Code、OpenCode、Codex、Cursor、Copilot 这类支持 Skill 协议的 coding agent,一行搞定:
npx skills add https://github.com/NitroRCr/gread --skill gread
对支持 MCP 的客户端(Claude Desktop、Cherry Studio、各种 AI 对话应用),用 streamable HTTP 协议接入:
{
"mcpServers": {
"gread": {
"type": "streamableHttp",
"url": "https://api.gread.dev/mcp"
}
}
}
服务端是 api.gread.dev,作者自己托管,免费用。如果你对自托管有需求,仓库代码完整开源,自己拉起一份不难。
跟 Context7、DeepWiki 比,差在哪、强在哪
这是开发者最关心的问题。简单梳理一下:
- Context7:主打"最新版本文档",按版本号给 AI 喂文档片段。优势是文档质量高、覆盖主流库;劣势是只覆盖有官方文档的库,冷门库基本搜不到,而且只给文档不给源码。
- DeepWiki:Devin 团队做的,把 GitHub 仓库做成可问答的 wiki。优势是有预生成的项目摘要;劣势是"问答"形态决定了它是把答案揉好喂给你,AI Agent 拿不到原始的代码上下文。
- gread:覆盖所有 GitHub 公开仓库,给的是工具而不是答案,由 Agent 自己决定读什么。代价是首次访问冷门仓库可能要等服务端索引一下。
选型上,做工程类问答、读底层实现,gread 这种"工具型"方案更对路;只是想让 AI 写代码别用过时 API,Context7 也够用。两者其实可以并存。
顺手说说 Agent Skill 这个生态
2026 年开年这几个月,Skill 这个概念明显起来了。Anthropic 官方的 anthropics/skills 仓库、Vercel 的 vercel-labs/agent-skills、社区的 skills-hub、技能严选——基本上 npx skills add 已经成了开发者装 Agent 能力的标准动作,类似前端的 npm install。
Skill 和 MCP 的关系也逐渐清晰:MCP 是协议层,定义工具怎么暴露给模型;Skill 是分发层,把一组提示词、脚本、MCP 配置打包成可以一键安装的能力包。gread 同时提供两种形态,是个挺聪明的策略——coding agent 走 Skill,对话类应用走 MCP,覆盖面拉满。
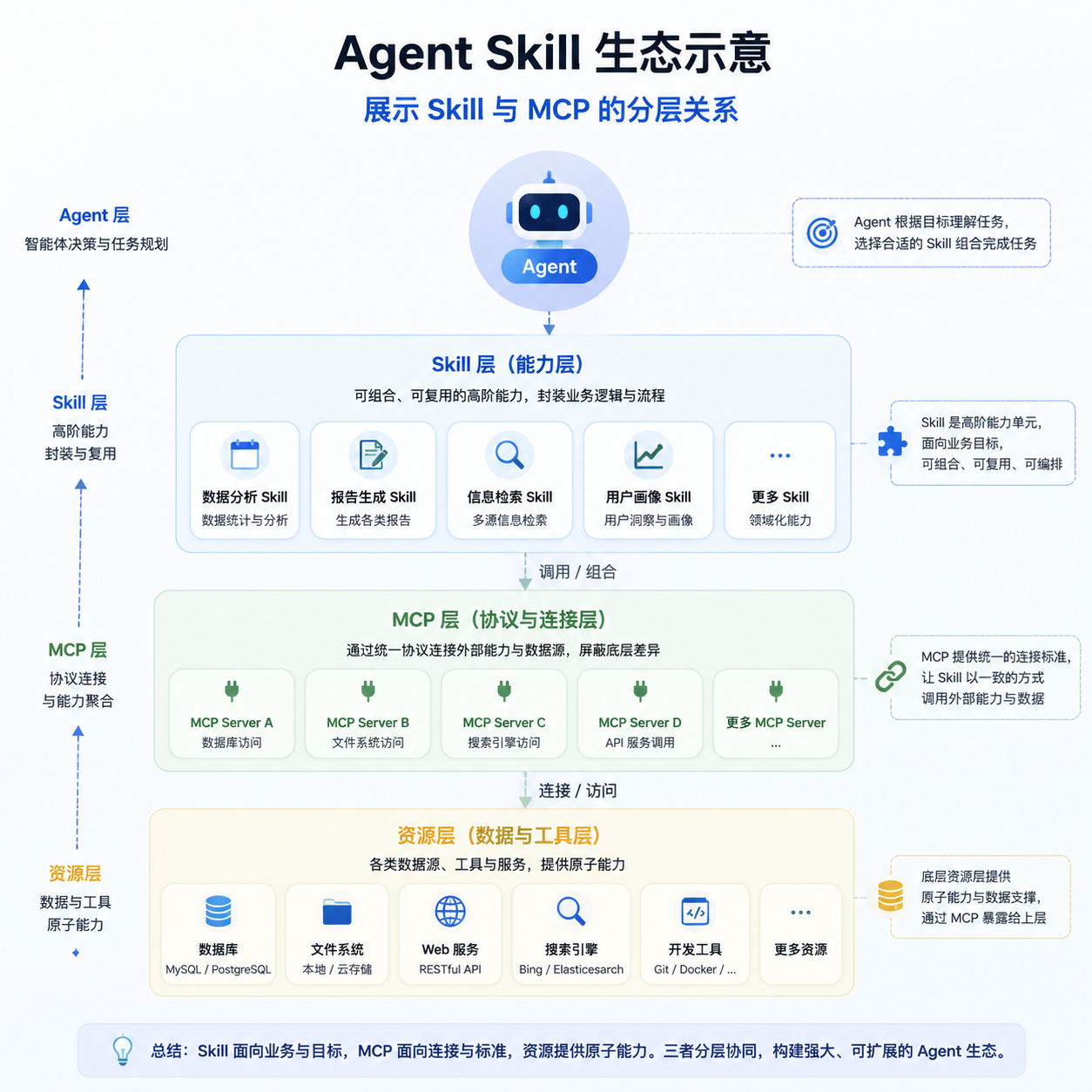
一些实际使用建议
几个用下来的小经验:
- 配合 Claude Sonnet 4.5 / GPT-5 这类长上下文模型效果最好。短上下文模型读几个文件就爆了,发挥不出按需读取的优势。OpenAI Hub 上这些主流长上下文模型都能直连调用,国内不用折腾代理。
- 明确告诉 Agent 你想看哪个仓库。虽然有搜索功能,但直接给出
owner/repo比让它自己搜更准。 - 复杂问题分两步:先让 AI 读目录树和 README,再让它针对性深入。一次性让它"分析整个项目"基本会失败。
写在最后
gread 不是什么颠覆性的东西,但属于那种"用过就回不去"的工具。AI 编程这一年的进化,越来越多发生在工具层而不是模型层——模型能力其实早就够了,真正卡脖子的是上下文怎么喂、工具怎么调。
三天写一个解决真实痛点的工具,开源、免费、有自己的服务端兜底——这种项目越多越好。
参考来源
- linux.do 原帖:开源 Skill 让 Agent 访问 GitHub 源码和文档:作者 NitroRCr 的发布与说明
- NitroRCr/gread (GitHub):项目主仓库,含完整源码与自托管文档
- Lirsakura/skills-hub (GitHub):开源 Skill 平台,了解 Skill 生态
- partme-ai/full-stack-skills (GitHub):另一个 Agent Skills 仓库,可对照参考