一封邮件,关掉了一条产业链
2026 年 5 月 8 日,OpenAI 给开发者发了一封措辞克制的邮件:自助微调(Fine-tuning)API 即将全面下线。新用户从即日起就别想再创建任务了,存量活跃用户能用到 2027 年 1 月 6 日;至于那些已经训练好、跑在生产环境的微调模型,命运和底层基座绑定——基座一旦退役,模型立刻停止推理。
这不是一次普通的产品调整。自助微调 API 自 2023 年 8 月 GPT-3.5 时代上线以来,已经被数千家组织用来训了几十万个模型。Indeed 用它把推荐 token 数砍掉 80%、月推送从不到 100 万条干到 2000 万条;Harvey 借助定制模型让律师在 97% 的场景下更愿意用它而非 GPT-4。如今,这条被无数初创团队当作"垂直行业起手式"的路径,被 OpenAI 亲手关上了。

OpenAI 的官方说法:你不需要微调了
邮件里给的理由很"OpenAI"——
新一代基座模型(GPT-5.5)在指令遵循和格式控制上已经足够强大,相比昂贵且笨重的微调,Prompt 工程 + RAG(检索增强)更便宜、更快、覆盖面更广,足以解决绝大多数场景。
这话听起来政治正确,技术上也确实有几分道理。GPT-5.5 这一代模型在长上下文(已经稳定支持 1M token)、JSON Schema 严格输出、工具调用这些"以前必须微调才能稳"的能力上,确实已经做到了开箱即用。配合 OpenAI 自家的 Responses API 和向量存储,Prompt + RAG 的工程组合现在能覆盖 80% 以上的常见场景。
但"绝大多数"不是"全部",这恰恰是问题所在。
微调到底解决什么 Prompt 解决不了的事?
搞过严肃产品的人都明白,微调和 Prompt 是两个层次的事:
- 风格与语气的内化:医疗、法律、金融这些行业,用词的精确度不是塞几条 few-shot 能稳住的。Harvey 当年喂了100 亿 token 的法律语料才让模型"像律师一样说话",这种深度无法用上下文窗口替代。
- token 成本的结构性压缩:Indeed 的案例就是教科书——把指令"烧"进权重里,prompt 从几千 token 缩到几百,规模化之后省下来的是真金白银。
- 小语种与垂直语料:SK Telecom 在韩语电信客服场景里,微调后意图识别提升 33%、满意度从 3.6 拉到 4.5,这种领域差距 RAG 补不上来,因为问题不在"知识"而在"表达分布"。
- 延迟敏感场景:微调后的小模型可以做到几十毫秒级响应,而塞满 RAG 上下文的大模型动辄秒级延迟。
换句话说,OpenAI 说"你不需要微调",约等于说"绝大多数客户不值得我为之维护这条产品线"。
真实原因:底层接口的战略收缩
科技媒体 Startup Fortune 的判断我比较认同:这是 OpenAI 在主动收缩它的底层模型接口。
过去两年里,OpenAI 已经悄悄做了几件类似的事:
- 从 GPT-5.4 开始,不再发布单独的
-chat系列 API 模型,开发者只能用统一的产品化接口; - Assistants API 在 2025 年中被合并进 Responses API,参数自由度下降;
- logprobs、embedding 维度自定义等"底层把手"陆续收回;
- 现在轮到了微调。
这是一条非常清晰的产品哲学迁移:OpenAI 不再希望你把它当"模型供应商",而是希望你把它当"AI 产品平台"。它要的是垂直一体化——你用 ChatGPT、用 GPT Store、用它的 Agent Builder,而不是拿走它的权重去做你自己的差异化产品。
对 OpenAI 自己来说,这笔账很划算:
- 微调服务的 GPU 占用极不经济,一个长尾客户的训练任务可能挤占本可以服务千万次推理的算力;
- 维护多版本基座 + 海量定制权重的工程复杂度极高;
- 而通用基座越强,定制需求的边际价值越低。
初创公司的护城河,正在被填平
问题在于另一边。
过去三年,围绕 OpenAI 生态,有相当一批初创公司的技术叙事是这样的:
"我们用专有数据微调了 GPT-3.5/4,在 XX 垂直场景下比通用模型好 30%。"
这种"轻量定制壁垒"是很多 YC 项目能拿融资的核心叙事。微调 API 一关,这个叙事直接破产。
剩下的选项不多:
| 路径 | 现实问题 |
|---|---|
| 转向 Prompt + RAG | 没有壁垒,竞品复制只需一周 |
| 走 OpenAI 的 Custom Model 计划 | 起步报价百万美元级,初创公司玩不起 |
| 转投开源(Llama、Qwen、DeepSeek) | 自建训练和推理栈,团队和成本陡增 |
| 用 Anthropic、Google 的微调 | Claude 至今没开放公开微调,Gemini 的微调也在收紧 |
这就是 Startup Fortune 那句话的分量——"这改变了创业剧本"。当底层定制路径关闭,OpenAI 生态里的初创团队要么向上做应用层(卷 UI 和工作流),要么向下逃到开源(自建模型能力)。中间那条最舒服的"在巨人肩膀上做微调"的路,没了。
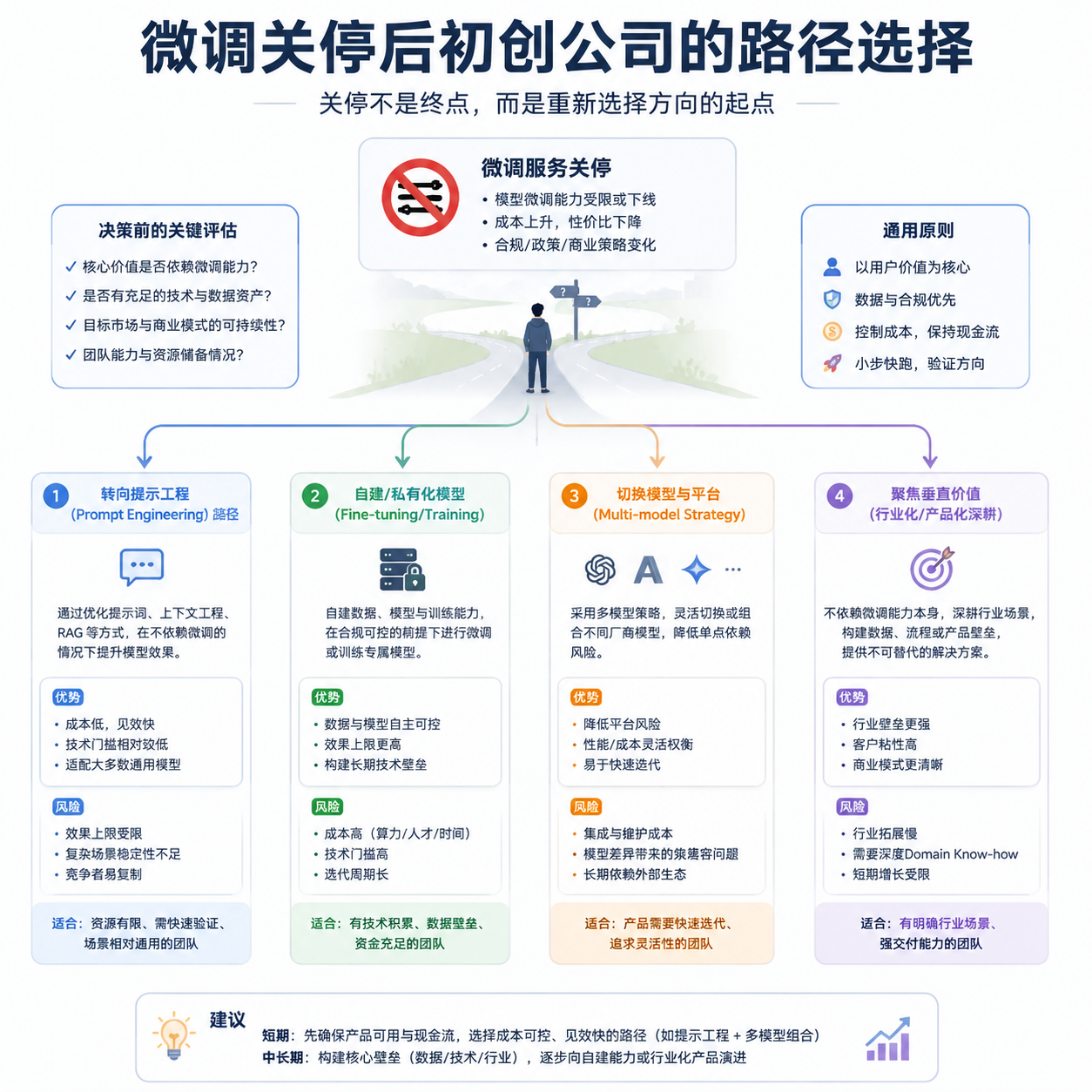
给开发者的几条务实建议
如果你团队里现在还有跑在 OpenAI 微调模型上的生产业务,时间其实没那么充裕。基座退役通常提前 6 个月通知,意味着你最晚需要在 2026 年底之前完成迁移评估。
短期(3 个月内):
- 把所有依赖微调模型的链路盘一遍,标注它们对"格式稳定性"和"风格一致性"的依赖度;
- 对每个微调任务做一次 GPT-5.5 + 精细 Prompt 的对照实验,很多场景你会发现确实可以平替;
- 把训练数据备份好——这些数据在你转向开源方案时仍然是核心资产。
中期(6-12 个月):
- 高敏感、高定制度的业务,开始评估 Qwen3、DeepSeek-V4、Llama 4 这些开源底座的微调可行性;
- 推理侧考虑多模型路由架构,不要把单一供应商当作架构假设。
顺便提一句,多模型路由这件事,OpenAI Hub 这类聚合平台目前是比较省事的方案——一个 Key 同时调 GPT-5.5、Claude、Gemini、DeepSeek,国内直连,OpenAI 格式兼容。在你重构架构、做 A/B 评测的过渡期,至少能省掉一堆账号和网络的折腾。
一个时代的注脚
2023 年 8 月微调 API 上线时,OpenAI 写的产品博客标题是《让开发者更精准地掌控模型》。三年后,同一家公司宣布关停时的措辞是《Prompt 已经足够》。
这中间发生的,不只是一个 API 的生死,更是 AGI 公司心智模型的转变——当基座足够强,定制就成了一种"低效的浪费"。这个判断对不对,要看接下来一年里,那些被踢出微调俱乐部的初创公司,能不能在 Prompt + RAG 的红海里找到新护城河;也要看 Anthropic、Google、以及国内的开源阵营,会不会顺势接住这一波被释放出来的定制需求。
模型定制的"平民时代"结束了。下一个时代是什么样,可能比这次关停本身更值得关注。
参考来源
- OpenAI 将彻底关闭微调 API:大模型全面转向 Prompt(linux.do) — 国内开发者社区对此次关停的第一手讨论
- 为什么 OpenAI 停止发布 -chat API 模型?(reddit) — 开发者关于 OpenAI 接口收缩趋势的讨论
- Hello GPT-4o 评论区(reddit) — 关于"Prompt 管理者时代"的早期讨论
- OpenAI 模型规范与 API 变更解读(zhihu) — 中文社区对 OpenAI 近期 API 策略变化的分析