Codex Nexus 开源:让 Codex 全端接入任意 AI 模型
Codex 的 CLI、IDE 和桌面 App 体验不错,但只能用官方指定的模型。想换个 DeepSeek V3 或 Claude 3.5 Sonnet?协议不兼容,直接卡死。开发者 linzy66 受够了这个限制,干脆自己写了个协议翻译层 Codex Nexus,让 Codex 全端生态能接入任何 OpenAI 兼容的模型。项目已在 GitHub 开源,提供 Web 管理界面,启动后自动修改 Codex 配置,开箱即用。
这个项目的价值在于打破了 Codex 的模型锁定。AI 编程工具的核心是模型能力,但工具厂商往往只对接自家或合作方的模型。Codex Nexus 用一个中继层解决了这个问题,让开发者能自由选择最适合当前任务的模型——代码补全用 DeepSeek Coder,复杂推理换 Claude,成本敏感时切到开源模型。这种灵活性对重度用户来说是刚需。
为什么需要协议翻译层
Codex 的 CLI、IDE 插件和桌面 App 都基于特定的 API 协议与后端通信。这个协议不是标准的 OpenAI Chat Completions 格式,而是 Codex 自己定义的 Responses 协议。即使你手里有 DeepSeek 或 Claude 的 API Key,也没法直接填进 Codex 的配置里——协议对不上,请求发不出去。
市面上的 AI 模型服务商基本都兼容 OpenAI 的 Chat Completions 格式,这已经是事实标准。但 Codex 走的是自己的路线,导致用户被锁在官方支持的模型列表里。想用新模型?要么等官方更新,要么放弃 Codex 换别的工具。
Codex Nexus 的思路很直接:在 Codex 客户端和模型服务之间加一层协议转换。Codex 发出 Responses 格式的请求,Nexus 翻译成 Chat Completions 格式转发给模型服务商,拿到响应后再翻译回 Responses 格式返回给 Codex。双向翻译,无缝对接。
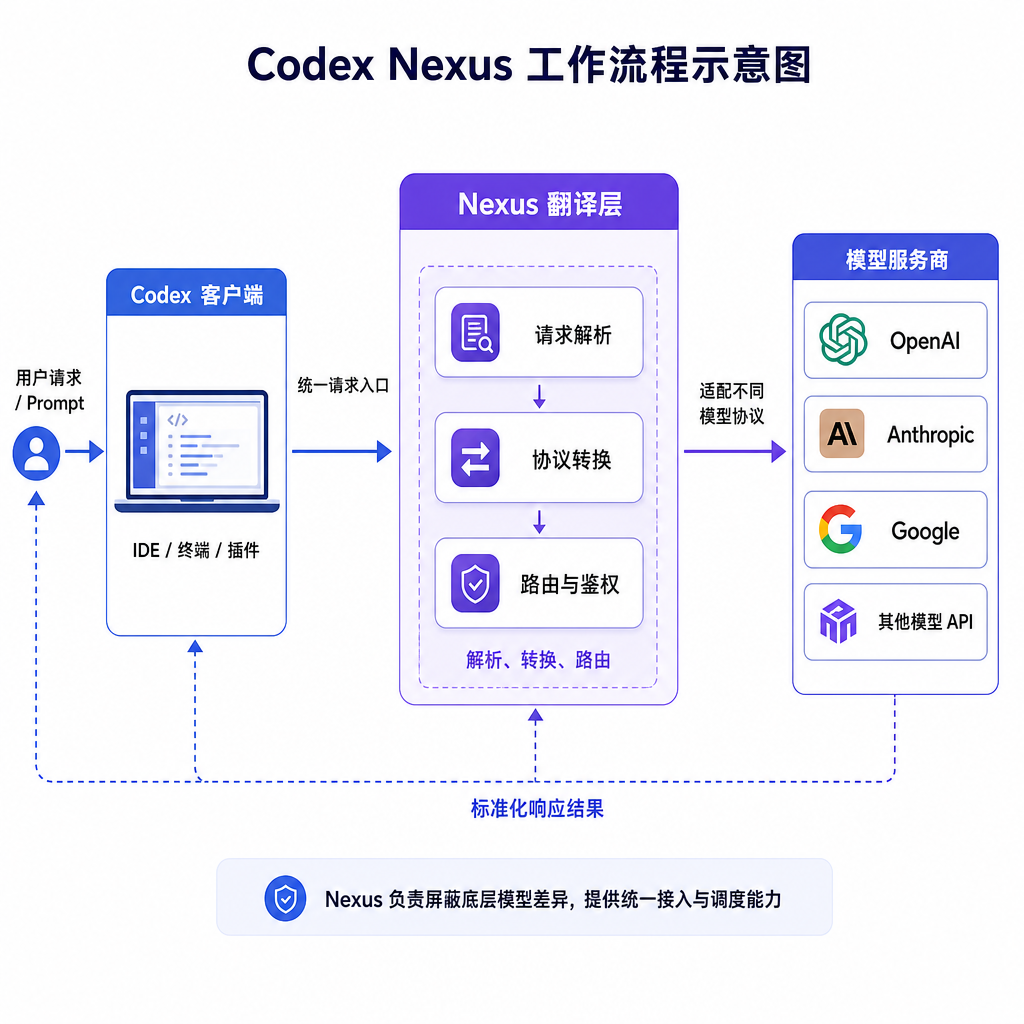
核心特性:自动配置 + Web 管理
Codex Nexus 最省心的地方是自动配置。传统的代理工具需要手动改客户端配置文件,填 API 地址、端口、认证信息,容易出错。Nexus 启动后会自动检测 Codex 的配置文件位置,直接把 API Base URL 改成本地的中继服务地址,用户完全不用动手。
项目提供了 Web 管理界面,可以在浏览器里配置模型列表、API Key、请求参数。界面设计很实用,支持多模型配置,每个模型可以单独设置 Base URL、API Key、默认参数(temperature、max_tokens 等)。切换模型只需要在界面里点一下,不用重启 Codex 客户端。
从作者在 Linux.do 社区发的截图看,Web 界面分为几个主要模块:
- 模型管理:添加、编辑、删除模型配置,支持自定义模型名称和参数
- 请求日志:实时查看 Codex 发出的请求和模型返回的响应,方便调试
- 配置导入导出:支持 JSON 格式的配置文件,可以快速迁移或分享配置
- 系统设置:配置 Nexus 监听端口、日志级别等全局参数
这套设计对开发者很友好。调试 AI 应用时,能看到完整的请求响应日志是基本需求。Nexus 把这个功能做进了 Web 界面,比翻日志文件方便多了。
技术实现:协议映射的细节
Codex 的 Responses 协议和 OpenAI 的 Chat Completions 格式在结构上有明显差异。Responses 协议更接近流式响应的设计,每个响应块包含增量内容和元数据。Chat Completions 则是标准的 JSON 格式,支持 messages 数组、role 字段、function calling 等特性。
Codex Nexus 需要处理的映射包括:
- 请求格式转换:把 Codex 的 prompt、context、options 映射到 Chat Completions 的 messages、temperature、max_tokens 等字段
- 流式响应处理:Codex 期望的是 SSE(Server-Sent Events)格式的流式响应,需要把 Chat Completions 的 stream 响应转换成 Responses 协议的增量块
- 错误处理:统一不同模型服务商的错误格式,转换成 Codex 能识别的错误响应
- 元数据传递:保留 token 使用量、finish_reason 等元数据,确保 Codex 能正确显示统计信息
从项目的 GitHub 仓库看,核心代码用 Python 实现,依赖 FastAPI 做 Web 服务,用 httpx 处理异步 HTTP 请求。代码结构清晰,主要模块包括:
translator.py:协议转换的核心逻辑config.py:配置管理和持久化proxy.py:HTTP 代理服务器实现web.py:Web 管理界面的后端 API
作者在代码里做了不少容错处理。比如某些模型服务商的流式响应格式不完全符合 OpenAI 规范,Nexus 会尝试修复或降级到非流式模式。这种细节决定了工具的可用性——理论上能跑和实际能用是两回事。
使用场景:多模型协作的实际价值
单纯支持多模型还不够,关键是这些模型能在实际工作流里发挥各自优势。Codex Nexus 让开发者可以根据任务特点选择模型:
代码补全和重构:DeepSeek Coder V2 在代码理解和生成上表现出色,尤其是处理大型代码库时的上下文理解能力。用它做日常的代码补全和简单重构,速度快、成本低。
复杂架构设计:涉及系统设计、技术选型、性能优化等需要深度推理的任务,Claude 3.5 Sonnet 或 GPT-4 更合适。这些模型的推理能力更强,能给出更全面的分析和建议。
文档和注释生成:Qwen 2.5 Coder 或 Gemini 1.5 Pro 在自然语言生成上有优势,用来写 README、API 文档、代码注释效果不错。
成本敏感场景:如果是个人项目或者预算有限,可以用开源模型(通过 Ollama 或 vLLM 本地部署)替代商业模型。虽然效果有差距,但基本的代码补全和问答足够用。
这种多模型协作的工作流在 AI 编程工具里还不常见。大部分工具要么只支持单一模型,要么虽然支持多模型但切换成本高(需要重新配置或重启)。Codex Nexus 把切换成本降到最低,让多模型协作变得实用。
开源生态的意义:打破工具锁定
Codex Nexus 的开源对 AI 编程工具生态有积极影响。过去一年,AI 编程工具的竞争主要集中在模型能力和产品体验上,但工具厂商往往通过模型锁定来维持用户粘性。用户想换模型就得换工具,迁移成本很高。
开源的协议翻译层打破了这种锁定。只要工具的客户端协议是已知的,就可以写一个类似 Nexus 的中继层,让用户自由选择后端模型。这对用户是好事,对工具厂商则是压力——不能再靠模型独占性留住用户,必须在产品体验和功能上做出差异化。
从技术角度看,Codex Nexus 的实现并不复杂,核心代码可能只有几百行。但它解决的是真实痛点,而且开源出来让其他开发者可以参考或直接使用。这种"小而美"的开源项目往往比大型框架更有实用价值。
项目目前还在早期阶段,作者在 Linux.do 社区表示会继续完善功能,欢迎提 Issue 和 PR。从社区反馈看,已经有用户在实际使用并提出改进建议,比如支持更多模型服务商、优化流式响应的延迟、增加请求缓存等。
与 API 聚合平台的互补关系
值得一提的是,Codex Nexus 和 API 聚合平台(如 OpenAI Hub)是互补而非竞争关系。API 聚合平台解决的是"一个 Key 调所有模型"的问题,统一了不同模型服务商的接入方式,提供统一的计费和管理。Codex Nexus 解决的是"让不兼容 OpenAI 格式的工具能用 OpenAI 兼容模型"的问题,是协议层面的适配。
实际使用中,两者可以组合:用户在 API 聚合平台申请一个 Key,在 Codex Nexus 里配置这个 Key 作为后端,就能在 Codex 里无缝切换平台支持的所有模型。这种组合既享受了聚合平台的便利(统一计费、国内直连、负载均衡),又保留了 Codex 的使用体验。
对于国内开发者来说,这个组合尤其实用。直接调用 OpenAI、Anthropic 的官方 API 存在网络问题,API 聚合平台提供国内节点解决了连通性。Codex Nexus 则让 Codex 这类优秀的 AI 编程工具能用上这些模型,不用因为协议问题放弃工具或模型。
未来方向:更多工具的适配
Codex Nexus 目前专注于 Codex 生态,但这个思路可以推广到其他 AI 编程工具。Cursor、Continue、Cody 等工具都有类似的模型锁定问题,理论上都可以用协议翻译层来解决。
如果社区能围绕这个方向形成一套通用的协议适配方案,对整个 AI 编程工具生态都是好事。用户不用再纠结"选工具还是选模型",可以自由组合最适合自己的工具和模型。工具厂商也能专注于产品体验,而不是靠模型独占性来留住用户。
从技术演进的角度看,AI 编程工具最终可能会走向"前端工具 + 后端模型"的分离架构。前端工具负责代码编辑、上下文管理、UI 交互,后端模型通过标准协议提供 AI 能力。Codex Nexus 这类项目是这个方向的早期探索。
当然,这个愿景能否实现还取决于工具厂商的态度。如果厂商刻意混淆协议或频繁变更接口来阻止第三方适配,开源社区的努力就会打折扣。但从目前看,大部分 AI 编程工具的协议都是可逆向的,社区有能力做出适配方案。
总结
Codex Nexus 用一个简洁的协议翻译层解决了 Codex 的模型锁定问题,让开发者能自由选择后端模型。项目开源、提供 Web 管理界面、自动配置客户端,实用性很强。对于重度使用 AI 编程工具的开发者来说,这是个值得关注的项目。
更重要的是,Codex Nexus 代表了一种思路:用开源工具打破商业产品的锁定,让用户重新获得选择权。这种思路在 AI 时代尤其重要——模型迭代快、工具层出不穷,用户需要灵活组合而不是被绑定在单一方案上。
项目目前还在早期,功能和稳定性还有提升空间。但方向是对的,社区反馈也积极。如果你在用 Codex 并且想尝试不同模型,可以去 GitHub 看看,提 Issue 或 PR 帮助项目完善。开源的价值就在于此——发现问题、解决问题、分享方案,让更多人受益。
参考来源
- Codex Nexus GitHub 仓库 - 项目源码和使用文档
- Linux.do 社区讨论帖 - 作者发布的项目介绍和使用说明,包含 Web 界面截图和工作流程图