Claude Code 学会了「做梦」

Anthropic 为 Claude Code 灰度上线 Auto Dream 功能,让 Agent 在空闲时自动整理、合并记忆,解决 AI 编程助手长期协作中的上下文退化问题。
Anthropic 在 3 月底给 Claude Code 悄悄加了一个新功能,叫 Auto Dream。
名字起得很浪漫,但干的事情很实在——让 Agent 在你不用它的时候,自动整理之前积累的记忆笔记。合并冗余的,清除矛盾的,把模糊的推断变成确定的知识。
简单说,Claude Code 学会了做梦。
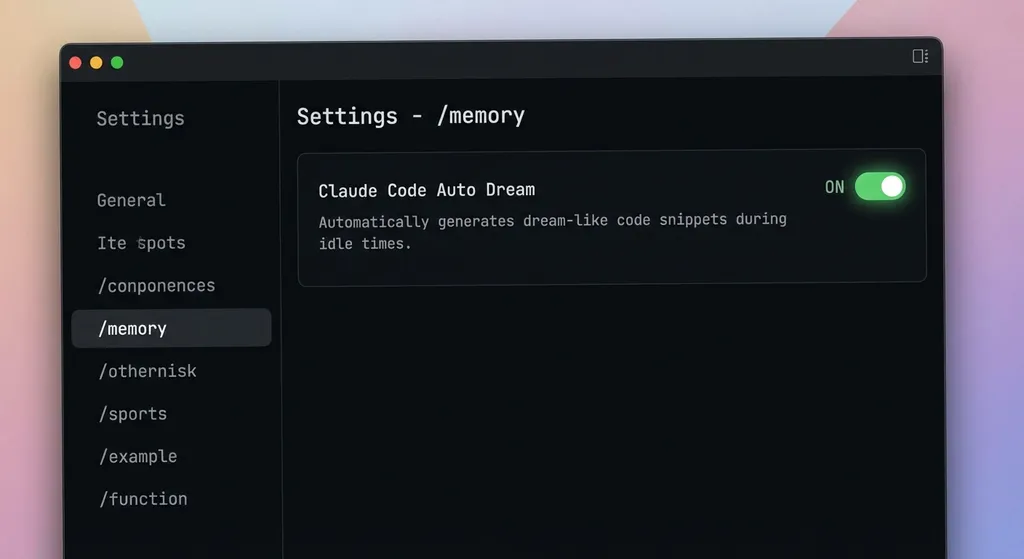
目前这个功能还在灰度阶段,没有全量放开。但已经有一批用户拿到了,你可以在 Claude Code 里输入 /memory,看看有没有 auto-dream 这个选项。如果有,打开就行。
先说前情:Auto Memory 是怎么回事
要理解 Auto Dream 在解决什么问题,得先聊它的前置功能——Auto Memory。
今年 2 月,Claude Code 上线了一套全自动的记忆系统,默认开启。在你跟 Claude Code 协作的过程中,它会自动把它认为重要的东西记下来:你用什么框架、偏好什么代码风格、项目架构长什么样、你纠正过它什么错误。
这些笔记按项目隔离,存在本地:
~/.claude/projects/<你的项目名>/memory/
目录里有一个 MEMORY.md 作为索引,下面挂着几类文档:
- user:关于你这个人的偏好和习惯
- feedback:你对 Claude 的纠正或肯定
- project:项目进展、技术决策、架构背景
- reference:外部资源的指引
这套机制的好处很明显。你不用每次开新对话都重复一遍「我用的是 Next.js 14,App Router,样式用 Tailwind,测试用 Vitest」。Claude Code 自己记着呢。
但问题也很明显。
记忆越多,越容易出错
用过一段时间 Claude Code 的开发者应该都有体感:项目做到中后期,Claude 的表现会开始飘。明明之前纠正过的问题又犯了,明明确认过的技术方案又开始摇摆。
原因不复杂。Auto Memory 是「只管记、不管理」的。每次对话产生的记忆碎片都往里塞,时间一长,记忆文件里充斥着重复的条目、前后矛盾的信息、早已过时的决策记录。
这就像你的笔记本写了三个月,从来没整理过。翻开一看,第 5 页写着「数据库用 PostgreSQL」,第 38 页写着「迁移到 MySQL」,第 72 页又写着「还是 PostgreSQL 好」。你自己看了都头大,何况是一个靠上下文窗口理解世界的 AI。
更要命的是,这些记忆文件会被注入到每次对话的上下文里。记忆越臃肿,真正有用的信息密度就越低,留给当前任务的上下文空间也越小。
之前业界的通用做法是 compact——压缩上下文。包括 OpenClaw 在内的命令行 AI 工具基本都是这个思路。但 compact 本质上是有损压缩,它在缩减长度的同时不可避免地丢信息。压得狠了,关键细节没了;压得轻了,问题没解决。
Auto Dream 要解决的就是这个事。
Auto Dream 的机制:后台子代理 + 双条件触发
Auto Dream 的设计思路,Anthropic 显然借鉴了人类睡眠时大脑整理记忆的机制。
我们睡觉的时候,大脑并没有完全停工。它在做一件很重要的事:编排记忆。把白天接收的海量信息筛一遍,重要的巩固,冗余的丢弃,碎片化的线索串成完整的认知。睡眠不足的人记忆力下降,不是因为没记住,是因为大脑没来得及整理。
Auto Dream 做的是同样的事,只不过对象从神经突触变成了 Markdown 文件。
它的触发需要同时满足两个条件:
- 距离上次整理已经过了 24 小时
- 中间至少积累了 5 个对话记录
两个条件缺一不可。如果你一天只跟 Claude Code 聊了两句,它不会触发——没什么好整理的。如果你一口气聊了 20 轮但中间没隔一天,它也不会触发——还没到「该睡一觉」的时候。
触发时机也值得说。它不是在你关掉 Claude Code 之后偷偷运行的(至少现在不是),而是在你下次打开对话开始干活的时候,系统在后台检查触发条件。如果满足了,它会单独起一个子代理(sub-agent)来执行整理任务。
这个子代理完全在后台运行,不占用你当前的对话。你该写代码写代码,该调试调试,做梦的事它自己默默处理。整理完了,你的记忆文件就变干净了,下次对话的上下文质量也就上去了。
用一个开发者的话说:「31 分钟前被整理了一下,我都不知道。」
它具体整理了什么?
从泄露的 Claude Code 源码和实际使用反馈来看,Auto Dream 的整理逻辑大致包括几个层面:
合并冗余。 如果你在不同对话里反复确认了同一个技术决策,比如三次提到「路由用 file-based routing」,它会合并成一条确定的记录。
消除矛盾。 如果早期记忆写着「用 REST API」,后来又改成了「用 GraphQL」,它会根据时间线保留最新的决策,把过时的清掉。
提升确定性。 有些记忆是 Claude 自己推断的,带有不确定性,比如「用户可能偏好函数式写法」。如果后续对话中这个推断被反复验证,Auto Dream 会把它升级为确定的知识。
结构化重组。 散落在不同文件里的相关信息会被归拢到一起,索引文件 MEMORY.md 也会同步更新。
整理前后的差异可以很直观地感受到。有用户反馈,整理前他的记忆目录「非常恐怖」,整理后变成了结构清晰的几个文档,每个文档内容精炼、没有废话。
这对实际编码体验的影响是直接的。记忆干净了,注入上下文的噪音就少了,Claude Code 对你的项目和偏好的理解就更准确,犯低级错误的概率也就降下来了。
现阶段的问题
说完好的,也得说说现实。
Auto Dream 目前还在灰度,稳定性不够。最典型的问题是手动触发经常失败。按照官方推荐输入 /dream,大概率会看到:
Unknown skill: dream
系统找不到 dream 这个 skill。自动触发倒是基本正常,但手动触发的体验还比较粗糙。
另外,触发条件的设计也有讨论空间。24 小时 + 5 个对话,这个阈值对于高强度使用的开发者来说可能偏保守。一天写十几个小时代码、开几十轮对话的人,可能希望整理频率更高一些。当然,这大概率是灰度期的保守策略,后续应该会开放自定义。
还有一个更根本的问题:整理的质量取决于模型本身的判断力。哪些信息该留、哪些该丢、哪些矛盾该怎么解决,这些都是模型在做决策。如果模型判断失误,把重要信息当冗余清掉了,反而会造成更大的问题。目前还没有看到回滚机制——不过记忆文件存在本地,理论上你可以用 Git 追踪变更,自己做版本管理。
为什么这件事值得关注
坦率地说,Auto Dream 不是一个多么惊天动地的功能。它没有让 Claude Code 突然变强,也没有解锁什么新能力。但它切中了一个真实的、长期被忽视的痛点。
AI 编程助手的竞争正在从「单次对话有多聪明」转向「长期协作有多靠谱」。Cursor、Windsurf、GitHub Copilot,大家在模型能力上的差距越来越小,真正拉开体验差距的,是谁能在第 100 次对话时还像第 1 次一样准确地理解你的项目。
这就是记忆管理的价值。
之前的做法,不管是 system prompt 里硬编规则,还是 .cursorrules 这样的静态配置文件,本质上都是「手动记忆」——你得自己告诉 AI 该记什么。Auto Memory 把这一步自动化了,但没解决「记太多、记乱了」的问题。Auto Dream 补上了这块。
从技术路线上看,这其实是在 Agent 层面复刻人类认知系统的「工作记忆 + 长期记忆 + 睡眠整合」三件套。工作记忆是当前对话的上下文窗口,长期记忆是 Auto Memory 写入的文件,睡眠整合就是 Auto Dream。
三者配合,才构成一个完整的记忆系统。
而且从 Claude Code 源码中暴露的 Kairos 和 Daemon 模式来看,Anthropic 的野心不止于此。现在的 Auto Dream 是「你开机的时候它在后台做梦」,未来很可能演进到「你关机了它还在做梦」——真正的异步后台 Agent。到那个阶段,记忆整理只是它在后台能做的事情之一。
对开发者的实际建议
如果你已经拿到了灰度资格,建议直接打开。在 Claude Code 中输入:
/memory
找到 auto-dream 选项,开启即可。
如果你还没拿到,也不用急。可以先做一件事:去看看你的记忆目录。
ls ~/.claude/projects/
挑一个用得久的项目,打开它的 memory/MEMORY.md,看看里面是什么状态。如果已经乱成一锅粥了,你可以手动整理一下,或者等 Auto Dream 全量上线后让它帮你处理。
另外,既然记忆文件存在本地,强烈建议把 ~/.claude/ 目录纳入版本管理。不用推到远端,本地 Git 就行。这样万一 Auto Dream 整理出了问题,你还能回滚。
cd ~/.claude
git init
git add .
git commit -m "memory snapshot before auto-dream"
对于重度依赖 Claude API 做自动化工作流的团队来说,记忆管理这个方向也值得关注。如果你通过 API 调用 Claude 模型来驱动自己的 Agent,类似的记忆整合逻辑完全可以在应用层自己实现。比如用一个定时任务,周期性地调用模型来整理你的 Agent 记忆存储。
通过 OpenAI Hub 调用 Claude 模型的示例:
from openai import OpenAI
client = OpenAI(
base_url="https://api.openai-hub.com/v1",
api_key="你的 OpenAI Hub Key"
)
# 读取当前记忆文件内容
with open("memory/MEMORY.md", "r") as f:
raw_memory = f.read()
response = client.chat.completions.create(
model="claude-sonnet-4-20250514",
messages=[
{
"role": "system",
"content": "你是一个记忆整理助手。请合并冗余信息,消除矛盾条目,保留最新决策,输出结构化的记忆文档。"
},
{
"role": "user",
"content": f"请整理以下记忆文件:\n\n{raw_memory}"
}
]
)
print(response.choices[0].message.content)
这段代码兼容 OpenAI 格式,换个 model 参数就能切到 GPT、Gemini 或 DeepSeek,方便你对比不同模型在记忆整合任务上的表现。
写在最后
AI Agent 的记忆问题,行业里喊了很久,但大多数方案还停留在 RAG 检索或者向量数据库的思路上——本质上是「怎么找到记忆」,而不是「怎么管理记忆」。
Auto Dream 的思路不一样。它不是在检索层做优化,而是在记忆本身的质量上下功夫。先记下来,再整理好,最后用的时候自然就准了。
这个思路对不对?我觉得方向是对的。人类的记忆系统就是这么运作的,而且被几百万年的进化验证过了。
至于 Anthropic 能不能把它做好,现在还不好说。灰度阶段的粗糙是正常的,关键看全量上线后的稳定性和整理质量。但至少,他们在认真思考一个正确的问题。
在 AI 编程助手这条赛道上,谁先把记忆管理做到位,谁就能在长期协作场景里拉开身位。Auto Dream 是 Anthropic 在这个方向上迈出的一步,不大,但很实在。
参考来源:
- Claude Code 悄悄学会了做梦 - 新浪财经:Auto Dream 功能的详细使用体验和触发机制解析
- 翻遍 Claude Code 泄露的 50 万行代码,我终于发现了它好用的秘密 - 腾讯新闻:从源码层面分析 autoDream 的记忆整合逻辑
- 当 Claude Code 悄悄学会了做梦 - 网易:Auto Memory 与 Auto Dream 的功能对比和记忆目录结构说明
- Claude Code 悄悄学会了做梦 - CSDN:灰度阶段的已知问题和手动触发方式
