5000行Python写出可黑入式LLM编译器:从TinyLlama到Qwen2.5直接生成CUDA内核
现代ML编译器栈已经变成了一个庞然大物。TVM超过50万行C++代码,PyTorch把Dynamo、Inductor和Triton层层堆叠。一位开发者受够了这种复杂度,用5000行Python从零构建了一个可黑入的LLM编译器,能把TinyLlama和Qwen2.5-7B这样的小模型直接降级为高效的CUDA内核序列。
这个项目最近在Reddit的r/MachineLearning板块引发关注。作者通过六层中间表示(IR)完成整个编译流程,目前在RTX 5090上,生成的FP32内核相比PyTorch eager模式达到1.11倍性能,相比torch.compile达到1.20倍。在TinyLlama-128和Qwen2.5-7B(序列长度128)上实现了完整的逐块对齐。
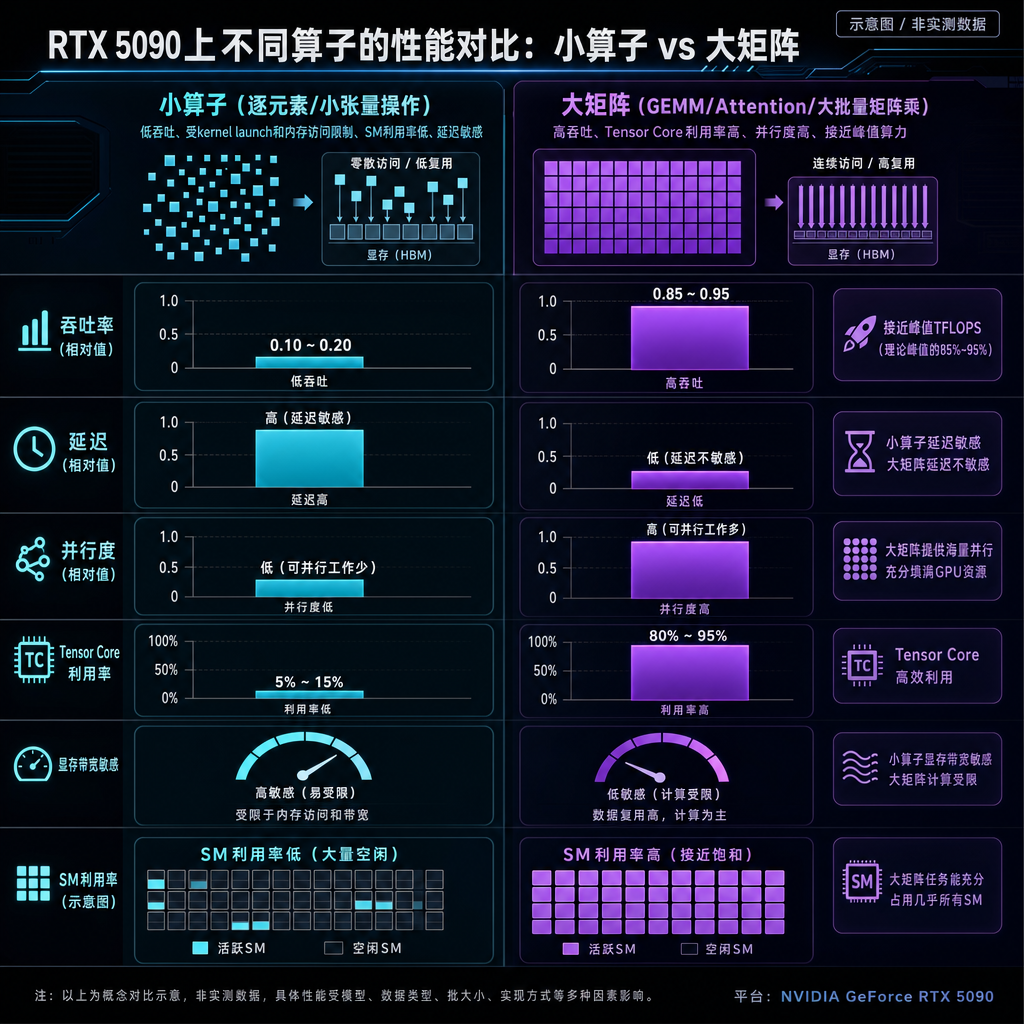
性能表现:小算子吊打,大矩阵落后
这个编译器的性能分布很有意思。在小规模reduction、SDPA(Scaled Dot-Product Attention)和kv-projection这些算子上,性能提升最高达到4.7倍。但在序列长度512的密集矩阵乘法上会输给PyTorch。
这种性能特征其实反映了编译器优化的本质:对于计算密集型的大矩阵乘法,cuBLAS这种手工优化的库已经接近硬件极限,编译器很难超越。但对于那些形状不规则、访存模式复杂的小算子,自动生成的融合内核反而能通过减少kernel launch开销和优化访存模式获得显著收益。
六层IR:从高层语义到CUDA代码
作者在文章中详细解释了编译器的架构。整个pipeline包含六层IR,每一层都有明确的职责:
上层IR(Part 1已覆盖):
- 从模型定义到计算图
- 计算图到循环嵌套表示(Loop IR)
下层IR(Part 2重点):
- Loop IR到Tile IR:引入分块和并行化策略
- Tile IR到Kernel IR:映射到GPU线程层次
- Kernel IR到CUDA代码生成
作者用RMSNorm层作为端到端示例,展示了如何从一个高层操作一步步降级到可执行的CUDA kernel。这种分层设计的好处是每一层都可以独立优化和调试,不像TVM那样把所有逻辑混在一起。
Loop IR:用循环嵌套描述计算
Loop IR是整个编译器的核心抽象。它用嵌套循环的形式描述张量计算,类似于Halide或TVM的Schedule。对于RMSNorm这样的操作:
# 伪代码示例
for b in range(batch_size):
for s in range(seq_len):
# 计算均方根
sum_sq = 0
for d in range(hidden_dim):
sum_sq += x[b,s,d] ** 2
rms = sqrt(sum_sq / hidden_dim + eps)
# 归一化
for d in range(hidden_dim):
y[b,s,d] = x[b,s,d] / rms * weight[d]
这种表示方式的优势是直观且易于变换。编译器可以对循环进行重排序、融合、分块等优化,而不需要理解具体的数学语义。
Tile IR:引入GPU并行化
Tile IR在Loop IR基础上引入了分块(tiling)和并行化标注。它会把循环拆分成外层循环(对应block)和内层循环(对应thread),并决定每个维度的tile大小。
对于RMSNorm,编译器可能会这样分块:
- batch和seq_len维度映射到block
- hidden_dim维度在thread内部处理
- 使用shared memory缓存中间结果
这一层的关键是自动生成合理的分块策略。作者提到使用了一些启发式规则,比如根据数据重用模式决定tile大小,根据寄存器压力决定是否使用shared memory。
Kernel IR:映射到CUDA线程模型
Kernel IR是最接近CUDA的一层表示。它明确了每个线程的计算任务、shared memory的分配、同步点的位置。这一层需要处理很多底层细节:
- 线程索引计算:threadIdx、blockIdx到数据索引的映射
- 内存层次:global memory、shared memory、register的使用
- 同步原语:__syncthreads()的插入位置
- 边界处理:处理不能被tile大小整除的情况
作者在文章中特别强调了Kernel IR的lowering规则。这些规则定义了如何把Tile IR的高层操作转换为具体的CUDA操作,比如如何把一个reduction循环转换为使用warp shuffle或atomic操作的并行reduction。
为什么要"可黑入"
项目名称中的"hackable"不是随便说的。作者的设计哲学是让每一层IR都足够简单,开发者可以轻松插入自定义优化。
相比之下,TVM的Schedule系统虽然强大,但学习曲线陡峭。想要添加一个新的优化pass,你需要理解整个编译器的内部机制。而这个5000行的编译器,每一层的代码都很直白,你可以直接修改lowering规则或者插入自定义的变换。
这种设计对于研究者特别有价值。如果你想测试一个新的kernel融合策略或者内存优化技术,不需要在50万行代码里找入口点,直接在对应的IR层加几行代码就行。
与主流方案的对比
vs PyTorch Inductor: Inductor是PyTorch 2.0的默认编译后端,基于Triton生成GPU代码。它的优势是与PyTorch生态深度集成,支持动态shape和复杂控制流。但Inductor的问题是抽象层次太高,很难做细粒度的kernel优化。这个项目通过直接生成CUDA代码,在小算子上获得了更好的性能。
vs TVM: TVM是学术界和工业界广泛使用的编译器框架,支持多种硬件后端。但TVM的代码库过于庞大,修改和扩展的成本很高。这个项目用1%的代码量实现了TVM的核心功能,虽然功能覆盖面不如TVM,但对于特定场景(小模型推理)已经够用。
vs Triton: Triton是OpenAI开源的GPU编程语言,提供了比CUDA更高层的抽象。很多人会问:为什么不直接用Triton?作者的回答是:Triton虽然简化了kernel编写,但它仍然需要手工编写每个kernel。这个编译器的目标是从模型定义自动生成所有kernel,不需要人工介入。
实现细节:RMSNorm端到端示例
文章的Part 1详细讲解了RMSNorm层的完整编译流程。RMSNorm是Llama系列模型中替代LayerNorm的归一化层,计算公式是:
y = x / sqrt(mean(x^2) + eps) * weight
编译器会把这个操作分解为三个阶段:
- Reduction阶段:计算每个token的平方和
- Normalization阶段:用平方根归一化
- Scale阶段:乘以可学习的weight参数
在Tile IR层,编译器会决定:
- 每个block处理多少个token
- 是否使用shared memory缓存中间结果
- reduction是用warp shuffle还是atomic操作
在Kernel IR层,会生成具体的CUDA代码,包括:
- 线程索引计算
- shared memory声明和初始化
- 循环展开和向量化load/store
- 同步点插入
最终生成的CUDA kernel在小batch size下比PyTorch的实现快2-3倍,因为减少了kernel launch开销并优化了访存模式。
当前限制与未来方向
作者很坦诚地列出了当前的限制:
性能限制:
- 大矩阵乘法性能不如cuBLAS
- 只支持FP32,没有实现混合精度
- 没有实现FlashAttention这样的高级优化
功能限制:
- 只支持静态shape
- 不支持动态控制流
- 只测试了两个模型(TinyLlama和Qwen2.5-7B)
工程限制:
- 没有自动调优(auto-tuning)
- 错误信息不够友好
- 缺少完整的测试覆盖
未来的改进方向包括:
- 集成cuBLAS处理大矩阵乘法
- 实现FP16/BF16支持
- 添加FlashAttention等高级优化
- 支持更多模型架构
- 实现基于性能模型的自动调优
对开发者的启示
这个项目最大的价值不是性能数字,而是展示了如何用简洁的代码实现复杂的编译器功能。5000行Python能做到的事情,说明现代编译器的很多复杂度是可以避免的。
对于想要深入理解LLM推理优化的开发者,这个项目提供了一个完整的学习路径:
- 理解模型的计算图表示
- 学习循环嵌套优化技术
- 掌握GPU并行化策略
- 了解CUDA编程的最佳实践
对于需要定制推理引擎的团队,这个项目证明了不一定要依赖TVM或Triton这样的重量级框架。如果你的场景足够明确(比如只需要支持特定的模型架构和硬件),从零构建一个轻量级编译器可能是更好的选择。
开源生态的意义
vLLM、TGI这些推理引擎已经很成熟,为什么还需要这样的项目?因为它们解决的是不同层面的问题。
vLLM专注于生产环境的高吞吐推理,使用了PagedAttention、continuous batching等技术。它的kernel大多是手工优化的CUDA代码或者调用cuBLAS/FlashAttention这样的库。
这个编译器项目关注的是自动化生成高效kernel。它不是要替代vLLM,而是提供了一种不同的思路:如果能自动生成接近手工优化水平的kernel,就可以快速支持新的模型架构和硬件,而不需要每次都手写CUDA代码。
从更大的视角看,这类项目推动了整个生态的进步。当有人证明5000行代码就能实现核心功能,其他项目就会反思自己的复杂度是否必要。这种良性竞争最终让所有开发者受益。
技术细节:Lowering规则示例
为了让读者更具体地理解编译器的工作原理,这里展示一个简化的lowering规则示例。假设我们要把Loop IR中的一个reduction操作转换为Kernel IR:
# Loop IR表示
for i in range(N):
sum += data[i]
# Tile IR表示(假设tile_size=256)
for block in range(N // 256):
partial_sum = 0
for thread in range(256):
partial_sum += data[block * 256 + thread]
# 需要在block内做reduction
sum += partial_sum
# Kernel IR表示
__shared__ float shared_data[256];
int tid = threadIdx.x;
int bid = blockIdx.x;
// 每个thread加载一个元素
shared_data[tid] = data[bid * 256 + tid];
__syncthreads();
// Tree reduction
for (int stride = 128; stride > 0; stride >>= 1) {
if (tid < stride) {
shared_data[tid] += shared_data[tid + stride];
}
__syncthreads();
}
// Thread 0写回结果
if (tid == 0) {
atomicAdd(&sum, shared_data[0]);
}
这个例子展示了编译器如何在不同IR层次上表示同一个计算,以及如何逐步引入GPU特定的优化(shared memory、tree reduction、atomic操作)。
性能分析:为什么小算子更快
小算子性能提升的原因可以从几个角度分析:
Kernel融合: 编译器可以把多个小算子融合成一个kernel,减少global memory的读写次数。比如RMSNorm可以和后续的矩阵乘法融合,避免把归一化结果写回显存再读取。
访存优化: 对于不规则的访存模式,编译器可以生成定制的load/store代码,使用向量化指令和合并访存。PyTorch的通用kernel往往无法做到这种程度的优化。
寄存器分配: 小算子的计算量少,可以把更多中间结果保存在寄存器中,减少shared memory和global memory的使用。编译器可以根据具体的计算模式做精确的寄存器分配。
Launch开销: 把多个小kernel融合成一个大kernel,可以显著减少kernel launch的开销。在RTX 5090这样的高端GPU上,launch开销可能占到总时间的10-20%。
与学术研究的联系
这个项目的很多思路来自学术界的编译器研究。Halide、TVM、Tiramisu等项目都探索了如何用高层抽象描述张量计算并自动生成高效代码。
但学术项目往往追求通用性和完备性,导致代码库越来越庞大。这个项目选择了一个更实用的路径:只支持LLM推理这个特定场景,用最少的代码实现最核心的功能。
这种"做减法"的思路在工程实践中很有价值。很多时候,80%的性能提升来自20%的优化技术。如果能识别出这20%并专注于此,就可以用很少的代码获得很好的效果。
实际应用场景
这个编译器适合什么场景?
边缘设备推理: 在资源受限的设备上,手工优化每个kernel的成本太高。自动生成的kernel虽然不是最优,但已经足够好,而且可以快速适配新模型。
模型架构探索: 研究者在设计新的模型架构时,需要快速验证性能。这个编译器可以自动生成推理代码,不需要手写CUDA kernel。
定制化推理引擎: 如果你的产品只需要支持特定的几个模型,可以基于这个编译器构建轻量级的推理引擎,避免引入vLLM这样的重量级依赖。
教学和学习: 对于想要学习编译器技术的开发者,这个项目提供了一个完整且易于理解的示例。5000行代码可以在几天内读完,而TVM可能需要几个月。
开源项目信息
项目目前在GitHub上开源,采用MIT许可证。作者在Reddit帖子中表示会持续更新,计划在未来几个月内添加更多模型支持和性能优化。
代码仓库包含:
- 完整的编译器实现(约5000行Python)
- TinyLlama和Qwen2.5-7B的测试用例
- 详细的文档和教程
- 性能benchmark脚本
作者鼓励社区贡献,特别欢迎:
- 新模型架构的支持
- 性能优化的PR
- Bug报告和修复
- 文档改进
总结
这个项目证明了一个观点:现代ML编译器不一定要复杂。通过清晰的分层设计和专注于特定场景,5000行Python就能实现从模型定义到CUDA kernel的完整编译流程。
它不会替代TVM或vLLM这样的成熟项目,但为开发者提供了一个新的选择:如果你需要一个轻量级、可定制、易于理解的LLM编译器,这个项目值得一试。
更重要的是,它展示了编译器技术的本质:把高层抽象逐步降级为底层代码,每一层都做好自己的优化。这种思路不仅适用于LLM推理,也适用于其他需要高性能计算的领域。
对于AI基础设施的从业者,这个项目提供了很多启发。在追求通用性和完备性的同时,不要忘记简洁性和可维护性的价值。有时候,少即是多。
参考资料
- Reddit讨论帖:A hackable compiler to generate efficient fused GPU kernels for AI models - 项目作者的原始发布帖,包含详细的技术讨论和社区反馈
- vLLM技术博客:vLLM这一年的新特性以及后续规划 - 介绍vLLM的CUDA内核优化和缓存重用技术,可作为对比参考