AMD 推出 vLLM-ATOM 插件,直接加速 DeepSeek、Kimi 推理
AMD 昨天(5 月 11 日)发布了 vLLM-ATOM 插件,这是一个专门为 Instinct GPU 设计的推理加速方案。核心卖点是:不改你现有的 vLLM 命令、API 和工作流,插件在后台接管优化,直接提升 DeepSeek-R1、Kimi-K2.5、gpt-oss-120B 等模型的推理性能。
对开发者来说,这意味着你可以把现有基于 vLLM 的服务平滑迁移到 AMD GPU 上,不用重写代码,不用学新框架。AMD 把这套方案包装成"零学习成本",但实际效果如何,还得看具体场景和模型。
vLLM 生态的 AMD 原生方案
vLLM 是目前大模型推理领域最主流的开源框架之一,重点优化高并发服务场景下的吞吐和显存利用率。它不是简单的"单次调用"推理工具,而是强调请求调度、KV 缓存管理和连续批处理,适合把模型做成长期在线服务。
AMD 之前在 vLLM 上的支持主要依赖 ROCm 后端,但性能表现一直不如 NVIDIA 的 CUDA 生态成熟。这次推出的 vLLM-ATOM 插件,本质上是 AMD 自己做了一套更贴近 Instinct GPU 架构的优化方案,然后以插件形式集成到 vLLM 生态里。
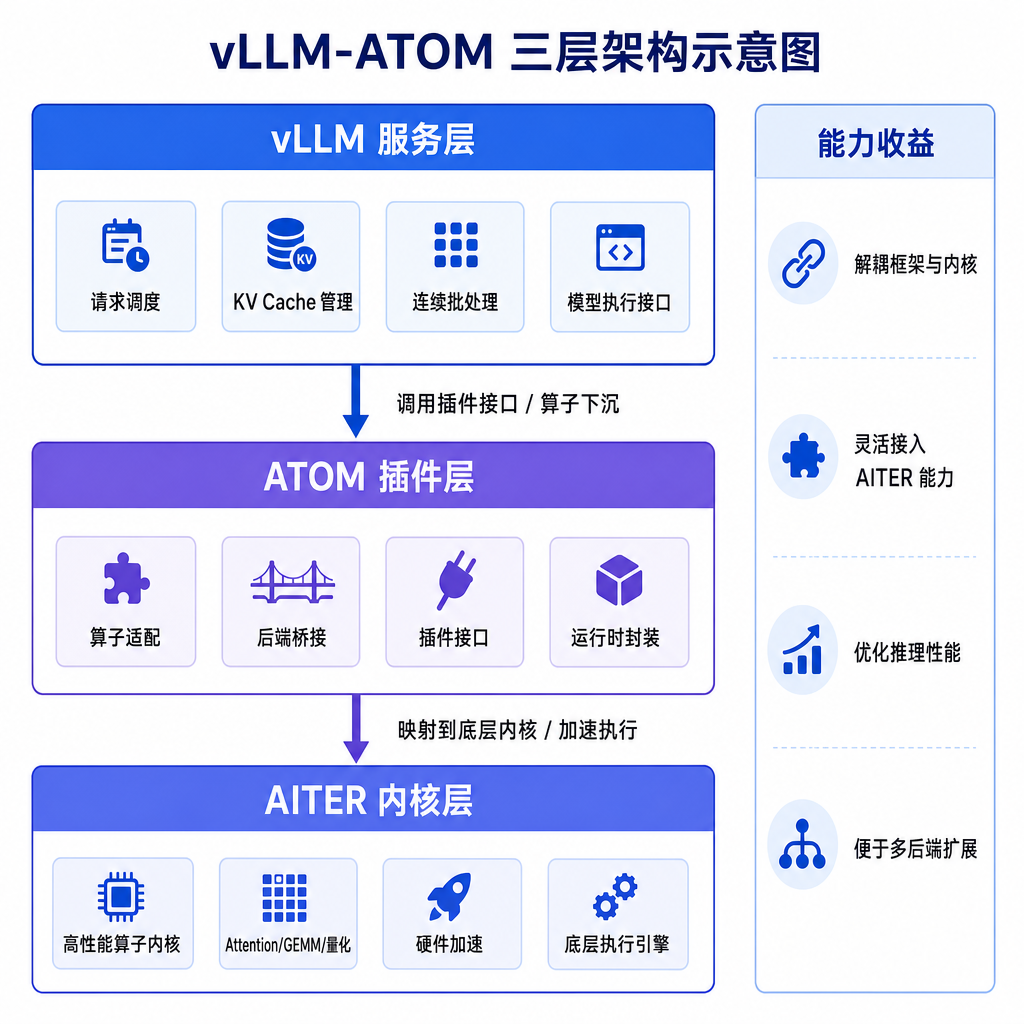
从架构设计看,vLLM-ATOM 分成三层:
- 最上层的 vLLM:负责请求调度、KV 缓存管理、连续批处理,以及兼容 OpenAI 的 API。这层保持不变,开发者继续用原来的接口。
- 中间层的 ATOM 插件:负责平台注册、模型实现、注意力后端路由和内核调优。这是 AMD 的核心优化层。
- 最底层的 AITER:提供 GPU 内核,包括融合 MoE、Flash Attention、量化 GEMM 和 RoPE 融合。这些是针对 AMD GPU 指令集优化的底层算子。
这种分层设计的好处是,AMD 可以在不动 vLLM 核心代码的前提下,把自己的优化注入进去。对 vLLM 社区来说,这也是一种相对友好的合作方式——成熟的优化可以逐步上游到 vLLM 的原生 ROCm 后端,让整个生态受益。
性能表现:MI355X 单卡吞吐破千
AMD 公布的性能数据显示,在 DeepSeek-R1-0528 模型上,MI355X 搭配 ATOM 框架,单卡吞吐量可以突破 1100 tok/s,延迟约 26 秒。作为对比,NVIDIA B200 搭配 TensorRT 在相近延迟下的吞吐量明显更低。
这个数据来自 AMD 自己的测试,具体测试条件包括 FP8 精度、特定的批处理大小和序列长度。实际生产环境中,性能表现会受到模型结构、输入分布、并发请求数等多种因素影响。但至少说明,AMD 在 Instinct GPU 上的推理优化已经做到了可以和 NVIDIA 正面竞争的水平。
从技术实现看,ATOM 的性能提升主要来自几个方面:
- 分页 KV 缓存:这是 vLLM 的核心优化之一,ATOM 在此基础上针对 AMD GPU 的内存层次结构做了进一步调优。
- 分段编译和图捕获:prefill 阶段用 eager 模式,decode 阶段用 graph replay,减少 kernel launch 开销。
- 融合算子:MoE 路由、Flash Attention、量化 GEMM 等关键算子都做了融合优化,减少显存访问次数。
- 多 GPU 并行:支持张量并行和流水线并行,适配 MI350、MI400 等多卡配置。
值得注意的是,ATOM 目前主要针对 Instinct MI350、MI400 和 MI355X 等高端 GPU。如果你用的是 Radeon Pro 或者更早的 MI 系列,可能无法获得完整的性能提升。
支持的模型和场景
vLLM-ATOM 目前支持的模型覆盖了主流的开源大模型,包括:
- 稠密模型:Llama 2/3/3.1、Qwen 系列
- MoE 模型:Qwen3-MoE(128 专家,top-8 路由)、Mixtral(8 专家,top-2 路由)、DeepSeek V2/V3(MLA 注意力)、GLM-4-MoE
- 混合架构:Qwen3-Next(全注意力 + Gated DeltaNet)、GLM-5(MLA 注意力,类似 DeepSeek V3.2)
- 多模态模型:支持文本加视觉的 VLM 场景
AMD 特别强调了对 DeepSeek-R1-0528、Kimi-K2.5-MXFP4、gpt-oss-120b 等最新模型的支持。这些模型要么是最近几个月刚发布的,要么是在推理优化上有特殊需求的(比如 Kimi 的 MXFP4 量化格式)。
从支持列表看,AMD 的策略是优先覆盖国内开发者常用的模型。DeepSeek、Kimi、GLM 这些模型在国内的使用量很大,支持它们可以快速打开市场。相比之下,NVIDIA 的 TensorRT-LLM 虽然性能强,但对新模型的支持速度往往慢半拍,这给了 AMD 一个切入点。
部署门槛:真的零学习成本吗?
AMD 宣称 vLLM-ATOM 是"零学习成本",但实际部署时还是有一些需要注意的地方。
首先,你需要安装 ROCm 环境。AMD 官方推荐 ROCm 6.0 或更高版本,这本身就是一个不小的工程。ROCm 的安装和配置比 CUDA 复杂,尤其是在多卡环境下,驱动、内核模块、容器运行时等各个环节都可能出问题。
其次,vLLM-ATOM 可以作为独立的推理服务器运行,也可以作为 vLLM 的插件后端集成。如果你选择插件模式,需要在 vLLM 的配置中指定使用 ATOM 后端。这个过程理论上是无缝的,但实际操作中可能会遇到版本兼容性问题。
再次,性能调优还是需要一些经验。虽然 ATOM 提供了默认的优化配置,但不同模型、不同硬件配置下,最优的批处理大小、KV 缓存策略、并行方式都不一样。AMD 提供了一个 benchmark dashboard,可以查看不同配置下的延迟、吞吐和质量指标,但你还是需要自己测试和调整。
最后,生态成熟度还是个问题。vLLM 社区的主要贡献者和用户都在 NVIDIA 生态里,遇到问题时,CUDA 相关的讨论和解决方案会更多。AMD 虽然在积极推动,但社区支持还是弱一些。
对开发者的实际意义
vLLM-ATOM 的发布,对开发者来说有几个实际意义:
- 多一个硬件选择:如果你在做大模型推理服务,现在可以考虑用 AMD GPU 了。尤其是在成本敏感的场景下,AMD 的性价比可能更有吸引力。
- 避免供应链风险:NVIDIA H100/H200 的供货一直很紧张,AMD Instinct 可以作为备选方案。虽然生态成熟度还有差距,但至少是一个可用的选项。
- 推动竞争:AMD 的入局会倒逼 NVIDIA 在价格和性能上做出更多让步,长期看对整个行业是好事。
但也要看到局限性:
- 生态差距:CUDA 生态的成熟度、工具链的完善度、社区的活跃度,AMD 短期内很难追上。
- 模型覆盖:虽然 ATOM 支持主流模型,但一些小众模型、定制模型可能还需要自己适配。
- 长期支持:AMD 在 AI 领域的投入是否能持续,这是一个问号。如果未来 AMD 战略调整,现在投入的迁移成本可能打水漂。
与 vLLM 原生 ROCm 后端的关系
一个容易混淆的点是:vLLM-ATOM 和 vLLM 原生的 ROCm 后端是什么关系?
vLLM 本身就支持 ROCm,这是社区维护的原生后端。vLLM-ATOM 是 AMD 自己做的一套优化方案,以插件形式提供。两者可以共存,开发者可以选择用哪个。
AMD 的策略是:先在 ATOM 里快速迭代新优化,验证效果后再逐步上游到 vLLM 的原生 ROCm 后端。这样既能保证 AMD 自己的优化能快速落地,又能回馈社区,是一种比较聪明的做法。
对开发者来说,如果你追求最新的性能优化,可以用 vLLM-ATOM;如果你更看重稳定性和社区支持,可以用 vLLM 原生的 ROCm 后端。两者的 API 是兼容的,切换成本不高。
国内开发者的机会
vLLM-ATOM 对 DeepSeek、Kimi、GLM 等国产模型的重点支持,对国内开发者来说是个好消息。这些模型在国内的使用量很大,但在 NVIDIA 的 TensorRT-LLM 上支持往往滞后。AMD 的快速跟进,给了国内开发者一个更灵活的选择。
尤其是在推理成本敏感的场景下,比如 ToC 的 AI 应用、大规模的推理服务,AMD GPU 的性价比优势可能更明显。如果 vLLM-ATOM 的性能表现能稳定在宣传的水平,国内云服务商和 AI 公司可能会更愿意尝试 AMD 方案。
另一个值得关注的点是量化支持。vLLM-ATOM 支持 FP8、MXFP4 等量化格式,这对降低推理成本很重要。Kimi-K2.5-MXFP4 就是一个典型例子,通过激进的量化,在保持模型效果的前提下大幅降低显存占用和计算量。AMD 在这方面的支持力度,可能会影响国内开发者在量化方案上的选择。
总结
vLLM-ATOM 是 AMD 在大模型推理领域的一次重要尝试。从技术实现看,分层架构、插件化集成、针对性优化,这些设计都比较合理。从性能数据看,MI355X 的表现已经可以和 NVIDIA 正面竞争。从生态策略看,先快速迭代再上游回馈,也是一种务实的做法。
但能否真正撼动 NVIDIA 在推理领域的地位,还要看几个关键因素:ROCm 生态的成熟度能否持续提升、AMD 在 AI 领域的投入能否长期维持、开发者社区的接受度如何。短期内,vLLM-ATOM 更像是一个补充选项,而不是替代方案。
对国内开发者来说,这是一个值得关注的方向。如果你在做大模型推理服务,尤其是用 DeepSeek、Kimi、GLM 这些模型,可以试试 vLLM-ATOM,看看实际效果如何。多一个选择总是好事,尤其是在硬件供应链和成本压力都很大的当下。
参考来源
- AMD 推出 vLLM-ATOM 插件,加速 DeepSeek、Kimi 等 AI 推理性能 - IT之家 - AMD 官方发布信息和技术细节
- AMD ATOM 推理引擎:如何用分页 KV 缓存和分段编译实现大模型推理性能翻倍 - 知乎 - ATOM 架构深度解析和性能测试数据
- vLLM-ATOM GitHub 仓库 - 开源代码和文档