浏览器插件就能跑 AI Agent,Curio 让自动化告别后端依赖
开发者 void5tar 刚开源了一个纯浏览器插件形式的 AI Agent 框架 Curio。不需要 Playwright、Puppeteer 那套后端架构,装个 Chrome 插件就能让 AI 直接操作当前页面——打开网页、读内容、点按钮、填表单、执行 JavaScript,甚至做基础的网页逆向分析。
这个思路跟 Vercel 前段时间推的 agent-browser 完全不同。agent-browser 走的是 CDP(Chrome DevTools Protocol)路线,本质上还是个 CLI 工具,需要启动独立的浏览器进程。Curio 直接把 content script 那套能力抽象成 function calling,AI 通过插件的 side panel 就能控制你正在浏览的页面。对于需要在真实浏览环境里调试、或者想直接操作已登录状态页面的场景,这种方式更直接。
实现思路:把浏览器 API 包装成 function calling
Curio 的核心实现并不复杂,但切入点很聪明。Chrome 插件的 content script 本身就能访问页面 DOM、监听事件、注入脚本,void5tar 做的事情是把这些能力标准化成 function calling 的格式,让 LLM 能通过工具调用的方式驱动浏览器。
具体来说:
- Content Script 抽象:把
document.querySelector、element.click()、element.value = xxx这些操作封装成独立的 function,每个 function 有明确的参数定义(selector、action type、value 等) - Page Script 注入:支持在页面上下文执行任意 JavaScript,这对绕过某些前端检测机制很关键。比如演示里提到的"学某通"视频学习任务会检测鼠标位置,通过注入脚本可以直接 mock 相关事件
- Agent 消息流:借鉴了 pi(可能是指某个开源 Agent 框架)的消息处理逻辑,支持 LLM 的流式输出。这意味着你能实时看到 AI 的思考过程和执行步骤,而不是等所有操作完成才返回结果
从代码组织看,Curio 把 Agent 的状态管理、工具调用、LLM 通信都放在插件的 background script 里,side panel 只负责 UI 展示。这种架构让插件能在后台持续运行,不会因为关闭 panel 就中断任务。
API 兼容性:不绑定特定模型
一个值得注意的设计是 Curio 支持所有 OpenAI/Anthropic 兼容的 API 格式。这意味着你可以用 GPT-4、Claude,也可以用 DeepSeek、Moonshot、Qwen 这些国产模型,甚至本地部署的 Llama。只要 API 遵循 OpenAI 的 function calling 规范,就能直接接入。
这个选择很实际。对于国内开发者来说,直连 OpenAI 或 Anthropic 的 API 有网络门槛,而 DeepSeek V3 这种模型在 function calling 能力上已经不输 GPT-4,价格还便宜一个数量级。Curio 不绑定特定模型,让开发者可以根据任务复杂度和成本预算灵活选择。
如果你在用 OpenAI Hub 这类聚合平台,配置会更简单——一个 API Key 就能在 GPT、Claude、Gemini、DeepSeek 之间切换,不用为每个模型单独配置 endpoint 和认证信息。
实际应用场景:从自动答题到网页逆向
void5tar 在演示里展示了两个典型场景:
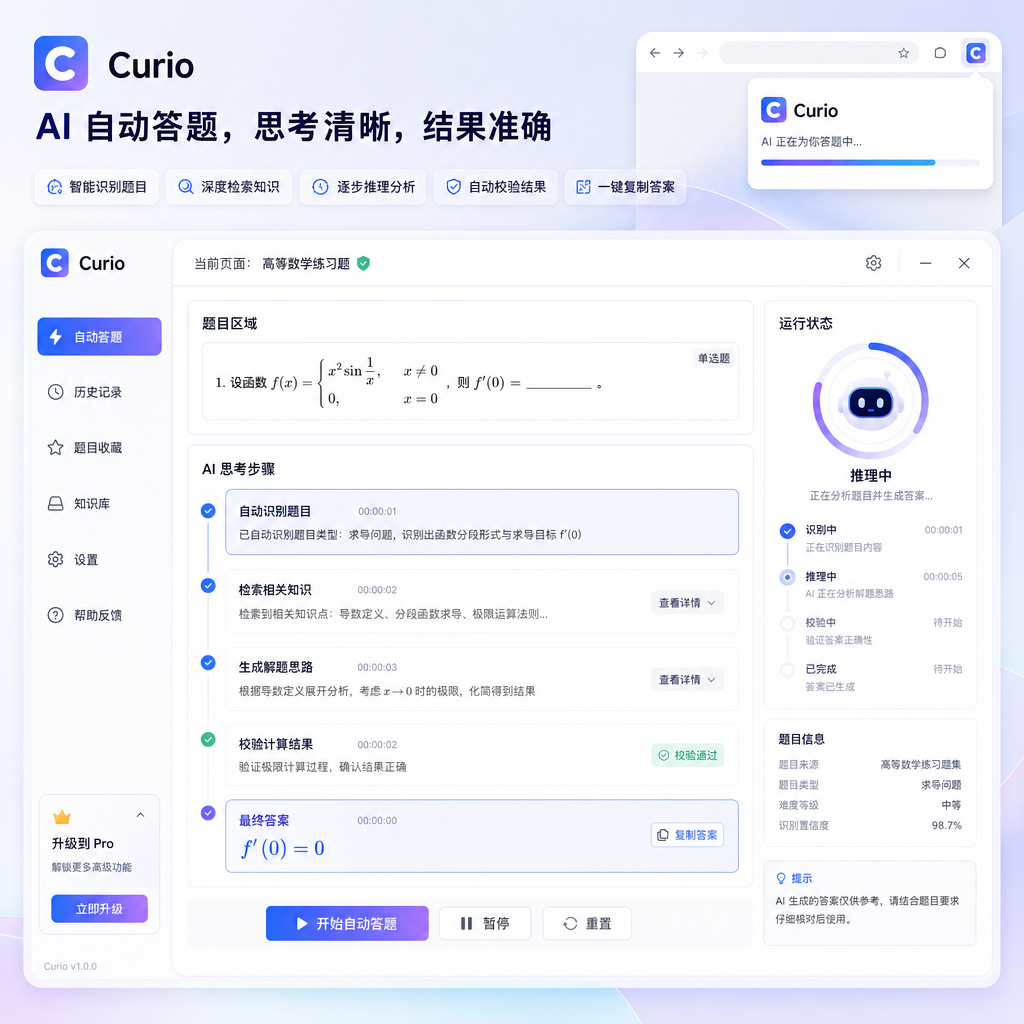
1. 自动答题
这是最直观的应用。AI 读取题目内容,调用搜索或知识库获取答案,然后自动选择选项并提交。整个流程不需要人工介入。
这类任务的关键在于 DOM 解析的准确性。不同网站的题目结构差异很大,有的用 <input type=\"radio\">,有的用自定义组件。Curio 通过让 LLM 先分析页面结构、再生成对应的 selector,能适应大部分场景。当然,如果遇到复杂的 Shadow DOM 或者动态生成的元素,可能需要多轮交互才能定位准确。
2. 网页逆向分析
这个场景更有技术含量。演示里提到的"学某通"视频学习任务会检测鼠标是否在视频区域内,如果检测到鼠标长时间不动或者离开页面,就会暂停计时。
传统的绕过方式是写油猴脚本,手动分析前端代码找到检测逻辑,然后 hook 相关函数。Curio 的做法是让 AI 先读取页面的 JavaScript 代码,识别出检测机制(比如 addEventListener('mousemove') 或者 setInterval 检查鼠标坐标),然后注入脚本 mock 这些事件。
这种方式的优势是通用性强。你不需要为每个网站写专门的脚本,只要告诉 AI "绕过鼠标位置检测",它会自己分析并生成对应的注入代码。当然,对于做了代码混淆或者用了 WebAssembly 的网站,AI 的分析能力会受限,这时候还是需要人工介入。
与 agent-browser 的对比:架构差异决定适用场景
Vercel 的 agent-browser 最近也挺火,但两者的设计思路完全不同:
| 维度 | Curio | agent-browser |
|---|---|---|
| 运行环境 | 浏览器插件,操作当前页面 | 独立 CLI,启动新的浏览器实例 |
| 技术路线 | Content Script + Page Script | Chrome DevTools Protocol |
| 状态管理 | 可直接操作已登录页面 | 需要通过 --profile 加载用户配置或手动登录 |
| 元素定位 | LLM 生成 selector | Snapshot 生成 @e1、@e2 引用 |
| 适用场景 | 调试、逆向、需要真实浏览环境的任务 | CI/CD、批量自动化、无头环境 |
| 性能开销 | 依赖当前浏览器,无额外进程 | 需要启动独立浏览器,有进程开销 |
agent-browser 的优势在于标准化和可复现性。它通过 snapshot 机制生成元素引用(比如 @e1 代表页面上第一个可交互元素),AI 不需要自己写 CSS selector,页面结构变化时引用依然有效。这对 E2E 测试和 CI/CD 场景很友好。
但 agent-browser 有个明显的短板:它启动的是全新的浏览器实例,没法直接操作你当前正在浏览的页面。如果你想让 AI 帮你在已登录的后台系统里批量处理数据,或者在调试时让 AI 自动填写表单,agent-browser 就不太方便了——你得先想办法把登录状态迁移过去,或者用 --profile 加载用户配置。
Curio 正好补上了这个空白。因为它是插件形式,可以直接访问当前标签页的 DOM 和 JavaScript 上下文,包括 cookies、localStorage、已登录的会话状态。这对需要在真实浏览环境里操作的场景非常实用。
技术实现的几个细节
1. Function Calling 的参数设计
一个好的 function calling 设计需要在灵活性和可控性之间平衡。Curio 的 function 参数大概是这样的结构:
{
\"name\": \"click_element\",
\"parameters\": {
\"selector\": \"string\", // CSS selector
\"wait_for\": \"number\", // 等待时间(ms)
\"scroll_into_view\": \"boolean\" // 是否滚动到可见区域
}
}
这种设计让 LLM 能精确控制每个操作的细节。比如点击一个按钮前,可能需要先滚动到可见区域,然后等待 500ms 让动画完成,再执行点击。如果只提供一个简单的 click(selector) 接口,遇到复杂交互就会出问题。
2. 错误处理和重试机制
网页自动化最大的挑战是不确定性。元素可能还没加载完、selector 可能写错、网络请求可能超时。Curio 需要把这些错误信息反馈给 LLM,让它能自己调整策略。
比如 click_element 返回 {\"success\": false, \"error\": \"Element not found\"},LLM 看到这个错误后,可能会先调用 wait_for_element 等待元素出现,或者调用 get_page_content 重新分析页面结构。
这种"执行-反馈-调整"的循环是 Agent 能力的核心。如果只是简单地抛出异常,LLM 就没法自主恢复,任务就会中断。
3. 安全性考虑
Curio 支持注入任意 JavaScript 代码,这在安全性上是个双刃剑。一方面,这让它能绕过各种前端限制,做一些"不太规矩"的事情。另一方面,如果 LLM 生成了恶意代码(比如窃取 cookies 并发送到外部服务器),后果会很严重。
void5tar 在文档里没有详细说明安全机制,但从插件的权限声明看,它应该只能访问用户主动打开的标签页,不能后台偷偷操作其他页面。不过对于企业用户来说,在生产环境使用这类工具前,最好先做代码审计,确保没有数据泄露风险。
一个可能的改进方向是增加沙箱机制,限制注入代码的能力范围。比如禁止访问 document.cookie、禁止发起跨域请求、禁止修改关键 DOM 节点等。这会牺牲一部分灵活性,但能大幅降低安全风险。
开源生态的意义:降低 AI Agent 的使用门槛
Curio 的开源对整个 AI Agent 生态有积极意义。在此之前,想要搭建一个能操作浏览器的 Agent,你需要:
- 部署一个后端服务(Node.js + Playwright 或 Python + Selenium)
- 处理浏览器驱动的安装和更新
- 管理浏览器实例的生命周期(启动、关闭、崩溃恢复)
- 处理网络代理、反爬虫检测等问题
- 把这些能力封装成 API 供 LLM 调用
这套流程对非专业开发者来说门槛很高。Curio 把所有复杂度都封装在插件里,用户只需要:
- 在 Chrome 应用商店安装插件(或者从 GitHub Releases 下载)
- 配置 API Key
- 在 side panel 里输入任务描述
这种"开箱即用"的体验,能让更多人尝试 AI Agent 的能力,而不是被技术细节劝退。
从开发者的角度看,Curio 的代码也有参考价值。它展示了如何用相对简单的架构实现一个可用的 Agent 框架,而不是一上来就搞微服务、消息队列、分布式调度这些重型设计。对于想要快速验证想法的团队,这种轻量级方案更合适。
当前的局限性和改进空间
作为一个刚开源的项目,Curio 还有不少可以优化的地方:
1. 元素定位的鲁棒性
目前 Curio 依赖 LLM 生成 CSS selector,这在简单页面上没问题,但遇到复杂的单页应用(React、Vue 等框架生成的动态 DOM)时,selector 的准确性会下降。
agent-browser 的 snapshot 机制是个不错的参考。它会在每次操作前生成一个"可交互元素列表",给每个元素分配一个临时 ID(比如 @e1、@e2),LLM 只需要引用这些 ID,不需要自己写 selector。这种方式对 LLM 更友好,也更不容易出错。
Curio 可以考虑增加类似的机制,或者提供一个"元素选择器"工具,让用户在页面上直接点击要操作的元素,插件自动生成对应的 selector。
2. 多标签页支持
当前 Curio 只能操作单个标签页。如果任务需要在多个页面之间切换(比如从列表页打开详情页、或者在多个网站之间对比数据),就需要手动切换标签页,然后重新启动 Agent。
一个可能的改进是增加标签页管理能力,让 LLM 能通过 function calling 打开新标签页、切换标签页、关闭标签页。这需要用到 Chrome 的 chrome.tabs API,技术上不难实现。
3. 任务持久化和恢复
如果任务执行到一半浏览器崩溃了,或者用户不小心关闭了插件,当前的进度就会丢失。对于复杂的多步骤任务(比如批量处理 100 条数据),这会很痛苦。
可以考虑增加任务状态的持久化,把每一步的执行结果保存到 chrome.storage 里。这样即使中断了,也能从上次的断点继续执行。
4. 调试和日志
当前插件的日志信息比较简单,如果任务失败了,很难定位是哪一步出了问题。可以增加更详细的执行日志,包括:
- 每个 function calling 的参数和返回值
- 页面 DOM 的快照(在关键步骤保存 HTML)
- 网络请求的记录(哪些 API 被调用了、返回了什么)
- LLM 的思考过程(类似 Chain-of-Thought 的中间推理步骤)
这些信息对调试和优化 prompt 都很有帮助。
对开发者的启发:插件是个被低估的 Agent 载体
Curio 的出现提醒我们,浏览器插件是个被低估的 Agent 载体。相比独立的桌面应用或 Web 服务,插件有几个独特优势:
- 无需安装额外依赖:用户的浏览器就是运行环境,不需要配置 Python、Node.js、Docker 这些东西
- 天然的权限隔离:插件只能访问用户授权的页面,不会影响系统的其他部分
- 与浏览器深度集成:可以访问 cookies、localStorage、浏览历史等数据,也可以监听网络请求、修改 HTTP 头
- 跨平台:Chrome 插件在 Windows、macOS、Linux 上都能用,不需要为每个平台单独打包
这些特性让插件特别适合做"个人助理"类的 Agent。比如:
- 邮件助手:自动分类邮件、生成回复草稿、提取关键信息
- 购物助手:比价、追踪降价、自动填写收货信息
- 学习助手:总结文章、翻译外文、生成笔记
- 工作助手:自动填写表单、批量处理数据、生成报告
这些场景的共同点是需要在真实的浏览环境里操作,而不是在一个隔离的自动化环境里。Curio 证明了这条路是可行的。
写在最后
Curio 还很年轻,代码量不大,功能也比较基础。但它的价值在于提供了一个新的思路:AI Agent 不一定要依赖复杂的后端架构,一个浏览器插件就能完成很多实用的自动化任务。
对于开发者来说,这是个值得关注的项目。你可以直接用它来解决一些重复性的浏览器操作,也可以基于它的代码学习如何把浏览器 API 封装成 function calling。如果你有更复杂的需求,也可以 fork 代码自己改造。
对于 AI Agent 生态来说,Curio 和 agent-browser 代表了两个不同的方向:一个追求轻量和易用,一个追求标准化和可复现性。两者不是竞争关系,而是互补的。根据具体场景选择合适的工具,才是正确的做法。
项目刚开源,作者在 Linux.do 社区征集反馈。如果你对浏览器自动化或 AI Agent 感兴趣,不妨去 GitHub 看看代码,或者下载插件试用一下。开源项目的成长需要社区的参与,你的反馈可能会影响项目的后续方向。
参考资料
- Curio GitHub 仓库 - 项目源码和安装说明
- Linux.do 社区讨论帖 - 作者发布的项目介绍和演示
- agent-browser 技术解析 - Vercel agent-browser 的技术对比参考