TabPFN-3 发布:免训练表格模型单卡处理百万行数据
表格数据处理领域今天迎来重要更新。TabPFN-3 正式发布,这是继去年 11 月 TabPFN-2.5 和今年 1 月登上 Nature 的 TabPFNv2 之后的第三代产品。核心卖点还是那个:不用训练、不用调参、不用搜超参数,一次前向传播直接出结果。
这次升级的重点是规模和速度。单张 H100 能处理 100 万行数据,是上一代的 10 倍;推理速度提升 10 到 1000 倍不等,SHAP 解释性分析通过 KV 缓存加速了 120 倍;新增的 Thinking Mode 在 TabArena 基准测试中领先所有非 TabPFN 方法超 200 Elo,包括调了 4 小时的 AutoGluon 1.5 extreme。在大数据集切片上,这个差距扩大到 420 Elo。
对于做表格数据建模的开发者来说,这意味着什么?意味着你可以跳过整个训练流程,直接把数据扔给模型,几秒钟后拿到预测结果。这在小样本场景下尤其有用——传统机器学习方法在数据量不足时容易过拟合,而 TabPFN 通过在 1.3 亿合成表格数据集上预训练,已经学会了如何处理各种表格结构和分布。
技术架构:Transformer 如何处理表格数据
TabPFN 的核心思路是把表格预测问题转化为序列建模问题。传统做法是针对每个数据集训练一个专门的模型,TabPFN 反其道而行之:在海量合成数据集上预训练一个通用模型,推理时直接把训练集和测试样本拼接成序列输入,让模型通过上下文学习(In-Context Learning)完成预测。
这个思路借鉴了大语言模型的范式。GPT 系列模型能够通过 few-shot prompting 完成新任务,TabPFN 把同样的机制应用到表格数据上。具体来说,模型输入是 [训练集样本 1, 训练集样本 2, ..., 测试样本],输出是测试样本的预测结果。整个过程不需要梯度更新,只需要一次前向传播。
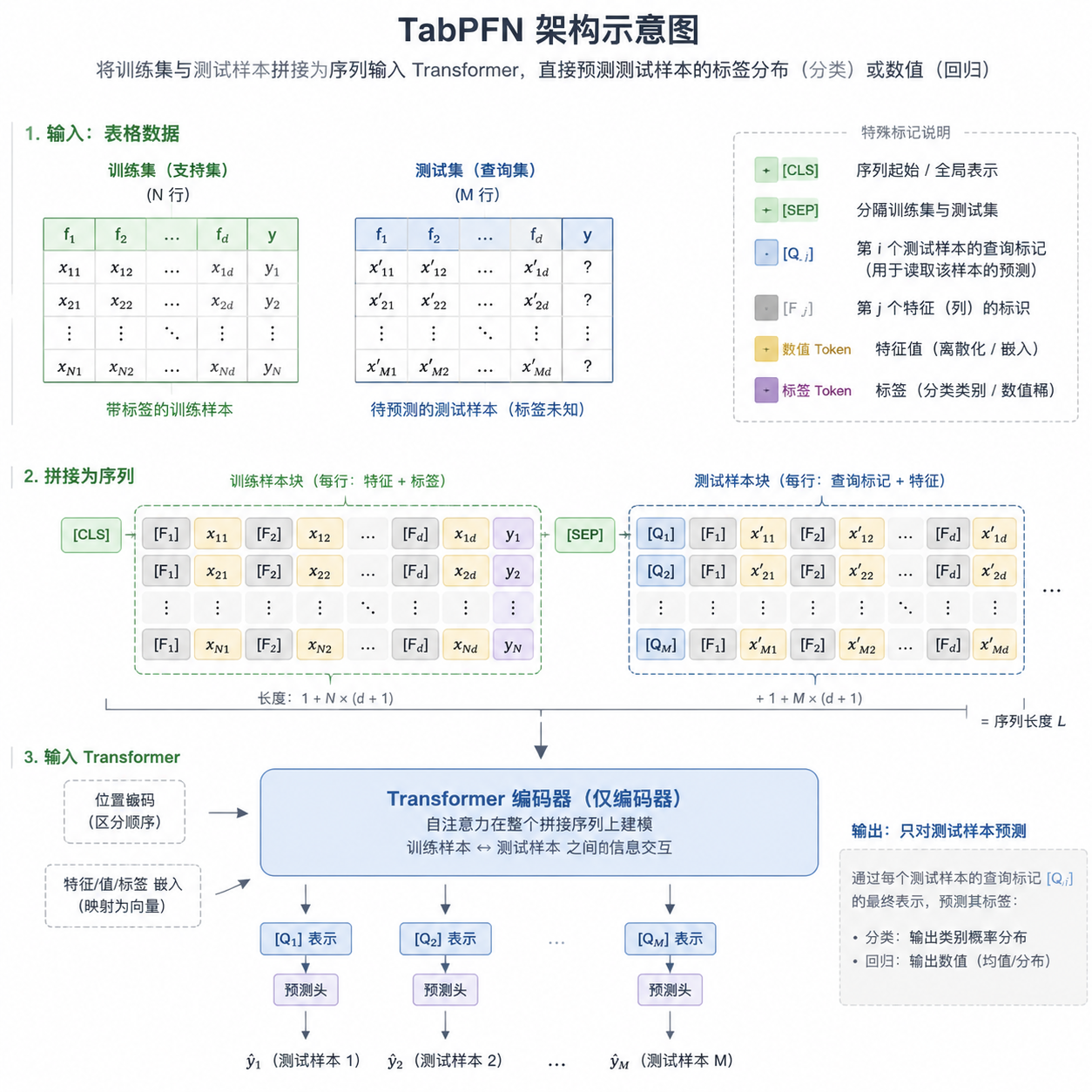
这种设计的优势在于:
- 零训练成本:不需要为每个数据集单独训练模型,省去了数据预处理、特征工程、模型选择、超参数调优等环节
- 泛化能力强:在 1.3 亿合成数据集上见过各种表格结构和分布,对新数据集的适应能力远超传统方法
- 推理速度快:没有训练开销,从数据到预测只需要几秒钟
但这也带来了限制:早期版本只能处理 1 万行以内的数据,特征数不超过 500。这次 TabPFN-3 把行数上限提升到 100 万,算是解决了最大的痛点。
TabPFN-3 的三大升级
1. 规模:单卡处理百万行数据
TabPFN-2.5 的行数上限是 10 万,TabPFN-3 直接跳到 100 万。这个提升不是简单的模型扩容,而是通过两个技术优化实现的:
KV 缓存优化:Transformer 的注意力机制需要存储所有 token 的 key 和 value,内存占用随序列长度平方增长。TabPFN-3 把 KV 缓存压缩到每百万行每个 estimator 约 8GB,使得单张 H100(80GB 显存)能够容纳完整的推理过程。
行分块推理:把百万行数据切分成多个块,分别计算注意力,最后合并结果。这个策略在保持精度的同时大幅降低了显存峰值。
这两个优化让 TabPFN-3 能够在单卡上处理中等规模的真实业务数据集。对比一下:AutoGluon 处理同样规模的数据需要数小时的训练时间,TabPFN-3 只需要几分钟的推理时间。
2. 速度:推理提速 10-1000 倍
推理速度的提升来自多个层面:
- 基础推理:相比 TabPFN-2.5 提速 10 倍,主要得益于 KV 缓存和算子优化
- SHAP 解释性分析:提速 120 倍,因为 SHAP 需要多次推理计算特征重要性,KV 缓存的复用效果更明显
- 批量预测:对于多个测试样本,可以并行处理,速度提升可达 1000 倍
这个速度优势在生产环境中很关键。传统机器学习流程中,模型训练是离线完成的,推理速度通常不是瓶颈。但 TabPFN 的范式是"推理即训练",推理速度直接决定了端到端的响应时间。TabPFN-3 把推理时间压缩到秒级,使得实时预测成为可能。
3. Thinking Mode:测试时计算推动精度上限
Thinking Mode 是 TabPFN-3 最有意思的新功能,目前只在 API 中提供。它的思路是在推理时进行额外的"思考"——通过一次性的额外拟合(one-time extra fitting)来提升预测精度。
这个机制类似于大语言模型的 Chain-of-Thought prompting,但应用在表格数据上。具体来说,模型会在推理时分析训练集的分布特征,动态调整预测策略。这个过程不涉及梯度更新,而是通过增加推理时的计算量来换取更高的精度。
效果如何?在 TabArena 基准测试中,Thinking Mode 版本的 TabPFN-3 领先所有非 TabPFN 方法超 200 Elo,包括调了 4 小时的 AutoGluon 1.5 extreme。在大数据集切片(行数更多、特征更复杂)上,这个差距扩大到 420 Elo。
TabArena 是一个综合性的表格数据基准测试,包含分类、回归、时间序列等多种任务,数据集来自 Kaggle、UCI 等真实场景。200 Elo 的差距意味着 TabPFN-3 在 75% 的对局中能够战胜对手,这是一个相当显著的优势。
与传统方法的对比:93% 胜率意味着什么
TabPFN-3 在经典机器学习方法上的胜率达到 93%。这个数字需要放在具体场景下理解:
小样本场景(1000 行以内):TabPFN 的优势最明显。传统方法在小样本下容易过拟合,需要大量的特征工程和正则化技巧。TabPFN 通过预训练学到了表格数据的通用模式,能够在少量样本下做出合理的预测。
中等规模场景(1000-10 万行):TabPFN 依然有优势,但差距缩小。这个区间是传统机器学习方法的舒适区,XGBoost、LightGBM 等梯度提升树模型经过调参后能够达到很高的精度。TabPFN 的优势在于省去了调参过程,开箱即用。
大规模场景(10 万行以上):TabPFN-3 把上限推到了 100 万行,但在这个规模下,传统方法经过充分调优后的精度可能更高。原因在于,TabPFN 的预训练数据集虽然规模大,但每个合成数据集的行数有限,模型在超大规模数据上的泛化能力还需要验证。
另一个需要注意的点是特征类型。TabPFN 对数值特征和类别特征都有很好的支持,但对于高维稀疏特征(如文本 embedding、图像特征)的处理能力不如深度学习方法。如果你的表格数据中包含大量非结构化特征,可能需要结合其他模型使用。
应用场景:什么时候该用 TabPFN
TabPFN-3 最适合以下场景:
1. 快速原型验证
你有一个新的业务问题,拿到了一批数据,想快速验证机器学习是否可行。传统流程需要几天时间:数据清洗、特征工程、模型选择、调参、评估。用 TabPFN,几分钟就能拿到一个 baseline,帮你判断这个问题是否值得深入投入。
2. 小样本预测任务
医疗、金融、工业等领域经常遇到小样本问题:数据采集成本高,标注困难,样本量只有几百到几千。传统方法在这种场景下很难训练出可靠的模型,TabPFN 通过预训练的先验知识能够在小样本下做出合理的预测。
3. 多任务场景
如果你需要为几十个甚至上百个不同的表格数据集构建预测模型,传统方法需要为每个数据集单独训练和调优,工作量巨大。TabPFN 可以用同一个模型处理所有数据集,大幅降低维护成本。
4. 实时预测需求
某些场景下,训练数据会频繁更新,需要模型快速适应新数据。传统方法需要重新训练,TabPFN 只需要重新推理,响应速度快得多。
不适合的场景:
- 超大规模数据(百万行以上):虽然 TabPFN-3 支持百万行,但在这个规模下,传统方法经过充分调优后的精度可能更高
- 极致精度要求:如果你需要在 Kaggle 竞赛中冲榜,或者业务对精度有极高要求,传统方法 + 大量调参可能是更好的选择
- 高维稀疏特征:如果数据中包含大量文本、图像等非结构化特征,深度学习方法可能更合适
开源生态与商业化
TabPFN 的前两个版本已经积累了 300 万次下载和 200 多篇应用论文,在学术界和工业界都有不少用户。TabPFN-3 延续了开源策略,代码和模型权重都在 GitHub 上公开,但 Thinking Mode 目前只通过 API 提供。
这个策略很聪明:基础功能开源,吸引用户和开发者;高级功能商业化,为持续研发提供资金支持。类似的策略在 Hugging Face、Replicate 等平台上也很常见。
从技术路线上看,TabPFN 代表了一种新的范式:用预训练 + 上下文学习取代传统的训练 + 推理流程。这个范式在 NLP 领域已经被证明非常有效,现在正在向表格数据、时间序列、图数据等其他领域扩展。TabPFN 的时间序列版本 TabPFN-TS 已经在 GIFT-Eval 基准测试中取得了不错的成绩,未来可能还会有更多垂直领域的变体。
与大语言模型的对比
有人可能会问:既然大语言模型也能处理表格数据,为什么还需要 TabPFN?
确实,GPT-4、Claude 等大模型可以通过 prompt 的方式处理表格数据,但它们的设计目标是通用语言理解,而不是表格预测。具体差异:
精度:TabPFN 在表格预测任务上的精度远高于大语言模型。原因在于,TabPFN 的预训练数据全部是表格数据,模型架构也针对表格结构优化;而大语言模型的预训练数据以文本为主,表格数据只是其中很小的一部分。
成本:TabPFN 可以在单张 GPU 上运行,推理成本很低;大语言模型需要调用 API,按 token 计费,处理大规模表格数据的成本很高。
可解释性:TabPFN 提供 SHAP 等传统机器学习的解释性工具,能够分析特征重要性;大语言模型的决策过程是黑盒,难以解释。
延迟:TabPFN 的推理速度在秒级,大语言模型的 API 调用延迟通常在几秒到几十秒。
当然,大语言模型也有自己的优势:它们可以处理非结构化数据,可以通过自然语言交互,可以完成更复杂的推理任务。两者的定位不同,不是替代关系,而是互补关系。
未来展望
TabPFN-3 的发布标志着表格数据建模进入了一个新阶段。从技术演进的角度看,有几个值得关注的方向:
规模继续扩大:100 万行还不是终点,未来可能会支持千万行甚至亿级数据。这需要更高效的注意力机制和分布式推理技术。
多模态融合:表格数据往往不是孤立存在的,可能伴随着文本描述、图像、时间序列等其他模态。如何把 TabPFN 与其他模态的模型结合起来,是一个有意思的研究方向。
领域适配:通用模型在特定领域可能不如专门训练的模型。未来可能会出现针对金融、医疗、电商等垂直领域的 TabPFN 变体,通过领域数据的微调来提升精度。
自动化流程:TabPFN 已经省去了训练和调参,但数据清洗、特征工程等前置步骤还需要人工完成。如果能把这些步骤也自动化,就能实现真正的端到端自动机器学习。
对于开发者来说,TabPFN-3 提供了一个新的工具选项。它不会取代传统机器学习方法,但在特定场景下能够大幅提升效率。值得一试。
参考资料
- TabPFN-3 Reddit 讨论 - 官方发布公告及社区讨论
- TabPFN 表格数据基础大模型详解 - 知乎 - 技术原理和算法细节解析
- Nature 2025: TabPFN Transformer 表格型数据预测新神器 - 知乎 - TabPFNv2 Nature 论文解读