Ganglia:用调用图解决 AI 编程智能体的「盲改」难题
AI 编程智能体正在成为开发者的日常工具,但一个老问题始终没解决好:它们看不清代码之间的依赖关系。你让它改个函数,结果三个调用方一起挂了,因为智能体根本不知道这些调用方的存在。
Ganglia 是一个专门为 AI 编程智能体设计的代码智能框架,核心能力是给智能体提供完整的调用图(call graph)。简单说,就是让智能体在动手改代码之前,先搞清楚「这个函数被谁调用了」「改了会影响哪些地方」。
智能体为什么会「盲改」代码
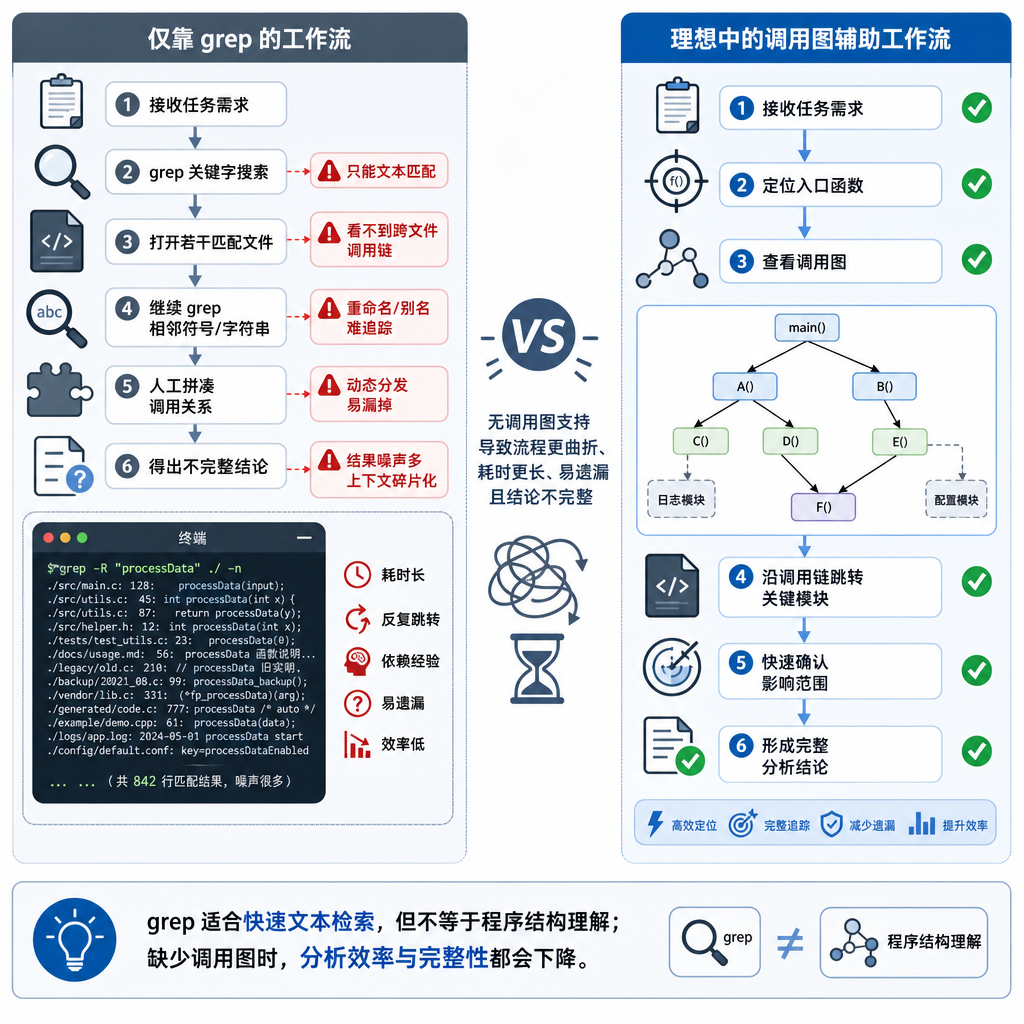
现在的 AI 编程智能体,无论是 Claude Code、Cursor 还是 Windsurf,工作方式基本一致:用户提需求,智能体用 grep、正则或语义搜索找相关代码,然后开始修改。问题出在「找相关代码」这一步。
Grep 只能找到直接的文本匹配。如果函数 A 调用了函数 B,但调用方式是通过接口、回调或者动态派发,grep 根本找不到这层关系。智能体看到的是一个孤立的函数 B,改完之后才发现函数 A 炸了。
语义搜索稍微好一点,但它解决的是「找相似代码」的问题,不是「找依赖关系」的问题。你问它「哪些地方用了这个函数」,它可能给你返回一堆看起来相关但实际上没调用关系的代码片段。
更麻烦的是间接调用。函数 A 调用 B,B 调用 C,C 调用 D。你改了 D,智能体只看到 C 在用它,完全不知道 A 和 B 也会受影响。这种多层依赖在真实项目里太常见了,尤其是框架代码和业务逻辑混在一起的时候。
Ganglia 做了什么
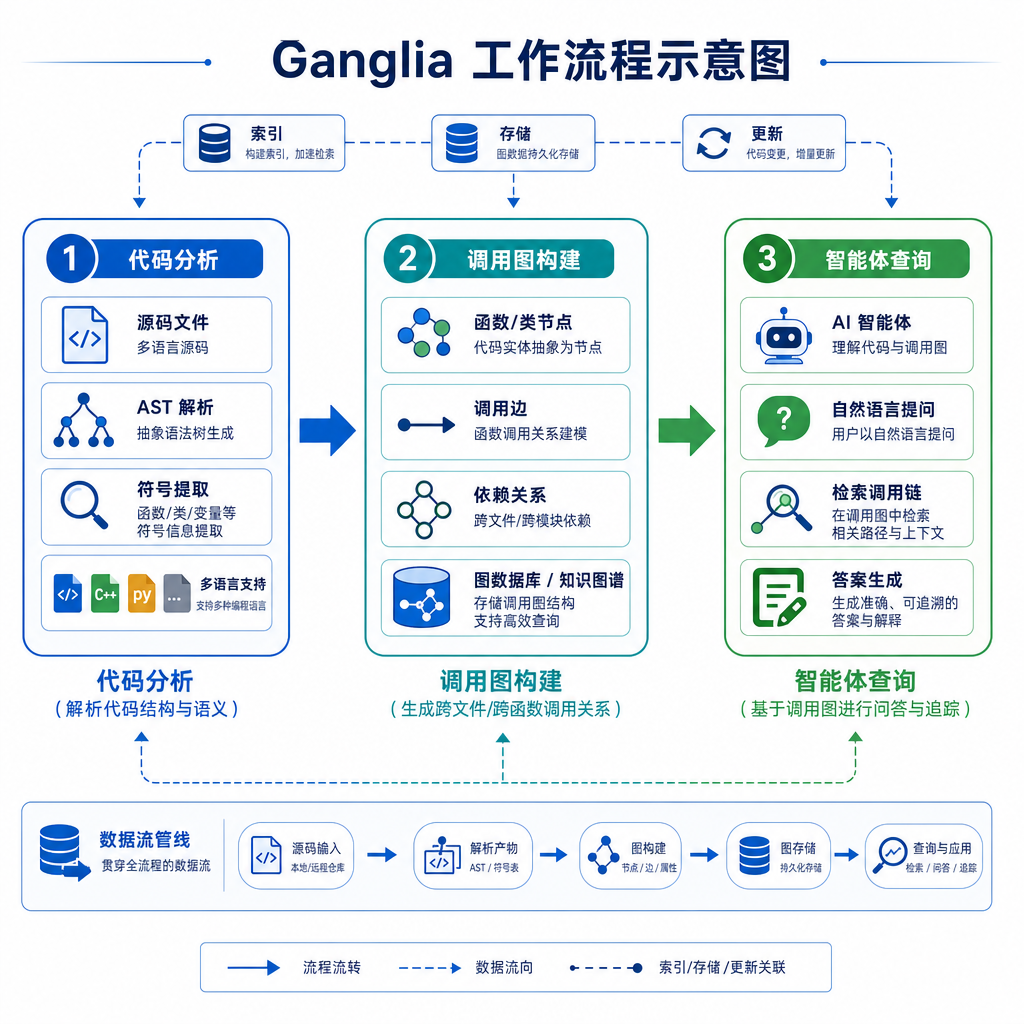
Ganglia 的核心是一个静态分析引擎,它会扫描你的代码库,构建出完整的调用图。这个调用图不是简单的「谁调用了谁」,而是包含了更多上下文信息:
- 完整的调用链:不只是直接调用方,还包括间接调用方。改一个底层函数,能追溯到所有可能受影响的上层代码。
- 爆炸半径评分:在修改之前,Ganglia 会给出一个「blast radius」分数,告诉智能体这次改动的影响范围有多大。分数高意味着改动会波及很多地方,智能体可以更谨慎地处理。
- 跨会话记忆:调用图会持久化存储,不需要每次对话都重新分析代码库。这对大型项目尤其重要,重新构建调用图可能要花几分钟甚至更久。
从技术实现上看,Ganglia 应该是基于抽象语法树(AST)或者字节码分析来构建调用图的。这比简单的文本匹配要重得多,但也更准确。它能识别出通过接口、继承、闭包、回调等方式建立的调用关系,这些都是 grep 做不到的。
和现有工具的集成方式
Ganglia 不是一个独立的编程智能体,而是一个可以集成到现有工具里的框架。目前它已经支持 Claude Code、Cursor 和 Windsurf 这三个主流 AI 编程工具。
集成方式应该是通过插件或者 API。智能体在需要了解代码依赖关系时,向 Ganglia 发起查询,Ganglia 返回调用图数据,智能体根据这些数据做决策。这种设计的好处是不需要改动智能体本身的架构,只是给它增加了一个「外部知识源」。
从用户角度看,使用体验应该是无感的。你还是像以前一样跟智能体对话,但智能体在背后会先问 Ganglia「这个改动安全吗」「会影响哪些地方」,然后再动手。如果影响范围太大,智能体可能会主动提醒你,或者建议一个更保守的改法。
这个方案的价值在哪
对开发者来说,最直接的价值是减少智能体引入的 bug。AI 编程智能体最大的问题不是写不出代码,而是写出的代码会破坏现有功能。有了调用图,智能体至少知道自己在改什么,改了会影响什么,出错的概率会大幅下降。
另一个价值是提高智能体的自主性。现在用 AI 编程工具,你得时刻盯着它,生怕它改错东西。有了 Ganglia,智能体可以更放心地做大范围重构,因为它能提前评估风险。这意味着你可以把更复杂的任务交给智能体,而不只是让它写写简单的工具函数。
从技术演进的角度看,Ganglia 代表了一个方向:给 AI 智能体提供更结构化的代码知识,而不是让它从海量文本里自己学。调用图是一种非常精确的知识表示,比自然语言描述或者代码注释要可靠得多。未来可能还会有更多类似的工具,比如提供类型信息、数据流分析、测试覆盖率等等。
定价和商业模式
Ganglia 采用 freemium 模式。免费版永久可用,Pro 版 19 美元/月,Team 版 49 美元/月。目前还在 beta 阶段,所有功能都免费开放,beta 用户在付费版上线后会获得永久折扣。
这个定价在 AI 开发工具里算是中等偏下。对比一下,Cursor 的 Pro 版是 20 美元/月,GitHub Copilot 是 10 美元/月(个人版)或 19 美元/月(商业版)。考虑到 Ganglia 解决的是一个很具体的痛点,而且可以和现有工具叠加使用,这个价格应该是可以接受的。
免费版的具体限制没有公开,但按照常见做法,应该是在代码库规模、查询次数或者高级功能上有限制。对小型项目或者个人开发者来说,免费版可能就够用了。
技术挑战和局限性
构建调用图听起来简单,实际上有不少技术难点。
第一是动态语言的支持。Python、JavaScript 这类语言,函数调用关系在运行时才能确定,静态分析很难做到 100% 准确。Ganglia 应该是用了一些启发式规则或者类型推断技术,但肯定会有漏报或者误报的情况。
第二是增量更新。代码库在不断变化,调用图也要跟着更新。如果每次改动都要重新分析整个代码库,性能会很差。Ganglia 需要一个高效的增量更新机制,只重新分析受影响的部分。
第三是跨语言项目。现在的项目经常是多语言混合,前端 TypeScript,后端 Go,脚本用 Python。Ganglia 要支持这种场景,就得为每种语言实现一套分析器,工作量不小。
第四是第三方库的处理。你的代码可能调用了几十个外部库,这些库的代码你不一定有,或者有也不想分析(太大了)。Ganglia 需要一个机制来处理这种边界情况,可能是提供预构建的调用图,或者只分析到库的接口层。
和传统 IDE 功能的对比
IDE 早就有「查找引用」「调用层次」这些功能了,Ganglia 和它们有什么区别?
最大的区别是使用场景。IDE 的这些功能是给人用的,你点一下按钮,IDE 给你展示一个调用树,你自己判断要不要改。Ganglia 是给 AI 智能体用的,它需要把调用图转换成智能体能理解的格式,并且提供一些额外的元信息(比如爆炸半径评分)来辅助决策。
另一个区别是性能要求。IDE 的查找引用可以慢一点,用户等个几秒钟没关系。但智能体在工作流程中可能要频繁查询调用图,响应时间必须快,最好在毫秒级。这对索引结构和查询算法的要求更高。
还有一个区别是覆盖范围。IDE 通常只分析当前打开的项目,Ganglia 可能需要支持更大规模的代码库,甚至是跨仓库的依赖分析。这对存储和计算资源的要求都更高。
对 AI 编程工具生态的影响
Ganglia 的出现说明了一个趋势:AI 编程智能体正在从「写代码」向「理解代码」演进。
早期的 AI 编程工具,比如 GitHub Copilot,主要是代码补全。你写一半,它帮你写完。这个阶段智能体不需要理解整个项目,只要根据上下文生成合理的代码就行。
现在的工具,比如 Cursor、Claude Code,已经可以做跨文件的修改和重构。这个阶段智能体需要理解文件之间的关系,但还是主要依赖搜索和语义匹配。
Ganglia 代表的是下一个阶段:智能体需要理解代码的结构化知识。调用图只是一个开始,未来可能还会有数据流图、控制流图、依赖图等等。这些结构化知识可以让智能体做更复杂的推理,比如「这个改动会不会引入死锁」「这个优化会不会破坏线程安全」。
从这个角度看,Ganglia 不只是一个工具,更像是一个基础设施。它为 AI 编程智能体提供了一个「代码知识层」,让智能体可以站在更高的抽象层次上工作。这可能会催生出一批新的工具和服务,专门为智能体提供各种结构化的代码知识。
开发者该不该用
如果你正在用 Claude Code、Cursor 或 Windsurf,并且经常遇到智能体改错代码的情况,Ganglia 值得一试。尤其是在大型项目或者遗留代码库上,调用图的价值会更明显。
但也要有合理的预期。Ganglia 不能保证智能体永远不出错,它只是降低了出错的概率。而且对于动态语言或者高度抽象的代码,调用图的准确性可能会打折扣。
另外,Ganglia 目前还在 beta 阶段,功能和稳定性可能还不够完善。如果你的项目对稳定性要求很高,可以等它正式发布后再用。
从长远看,调用图这种结构化代码知识会成为 AI 编程工具的标配。Ganglia 作为早期探索者,即使最终没有成为主流方案,它的思路也会被其他工具借鉴和吸收。
参考来源
- Ganglia: code intelligence for AI coding agents - Reddit - 项目作者在 r/MachineLearning 的发布帖,介绍了 Ganglia 的核心功能和定价策略