谷歌 Gemini Intelligence 登场:安卓原生 Agent 体系来了
谷歌在 2026 年 The Android Show | I/O Edition 上正式推出 Gemini Intelligence,这是安卓生态迄今为止最激进的 AI 助手升级方案。核心变化是把 Gemini 从「回答问题的聊天机器人」改造成「能代你干活的系统级 Agent」,不只能跨应用调度,还能直接操控 Chrome 浏览器完成网页任务。
这次升级的野心很明确:让 Gemini 成为安卓系统的「第二操作系统」,用户说一句话,它能串联起多个应用和网页把事情办完。从产品定位看,谷歌不再满足于做语音助手的增强版,而是要在移动端建立完整的 Agent 执行框架。
任务自动化:从聊天到执行的跨越
Gemini Intelligence 的核心能力是任务自动化。谷歌的逻辑是,既然用户能在手机上手动完成某件事,Gemini 就应该能代劳。这个「代劳」不是简单的语音指令触发预设流程,而是 Agent 真正理解任务目标、规划执行步骤、跨应用调度资源。
最直接的落地场景是表单填写。Chrome 以前的自动填充主要针对重复性表单(姓名、地址、信用卡号),遇到复杂表单就歇菜。Gemini Intelligence 的目标是处理各种非标准表单——比如保险理赔申请、签证材料提交、医疗问卷——这些表单字段不固定、逻辑分支复杂,传统自动填充根本搞不定。
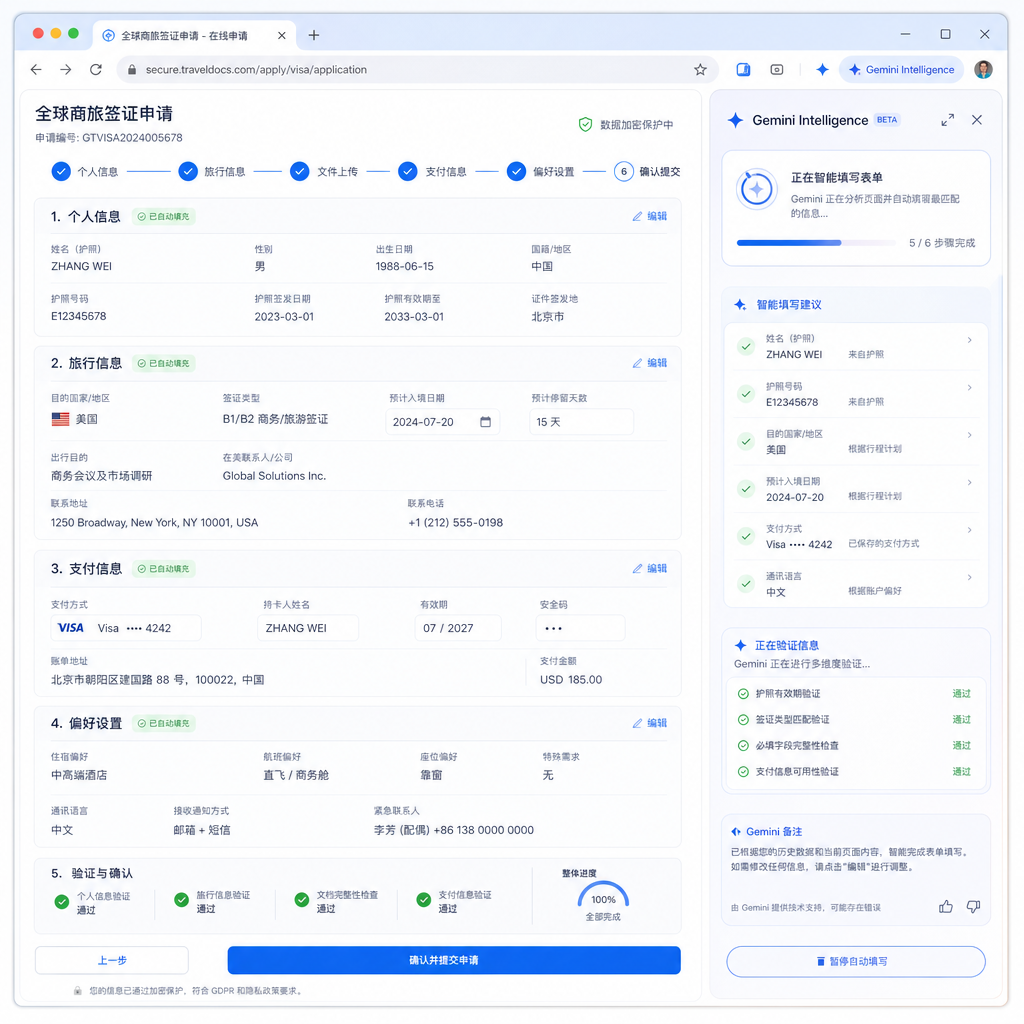
谷歌在演示视频里展示了一个场景:用户对 Gemini 说「帮我填完这个租房申请」,Gemini 会读取表单结构、从用户的 Google 账户和历史数据中提取信息(收入证明、雇主信息、紧急联系人),然后逐字段填写。遇到需要上传文件的地方,它会调用 Google Drive;遇到需要签名的地方,会提示用户确认。
这套能力的技术基础是 Gemini 的多模态理解和工具调用能力。它需要同时处理网页 DOM 结构、表单字段语义、用户数据权限、应用间通信协议。从实现难度看,这比 OpenAI 的 Operator 或 Anthropic 的 Computer Use 更复杂,因为移动端的应用沙盒机制比桌面浏览器严格得多。
Chrome 自动浏览:Agent 的真正战场
更激进的是 Chrome 自动浏览功能。谷歌明确表示,只要一项任务能在网页上完成,Gemini 就应该能代用户执行。这意味着 Gemini 不只是填表单,还能点击按钮、导航页面、处理多步骤流程。
举个例子:用户说「帮我在亚马逊上找一个 50 美元以内、评分 4 星以上的蓝牙耳机,加入购物车但别结账」。Gemini 需要打开亚马逊、输入搜索词、应用筛选条件、浏览商品列表、对比评价、选择商品、加入购物车。这是典型的多步骤、多决策任务,传统语音助手完全做不到。
谷歌计划从 6 月开始推送 Chrome 自动浏览功能,首批支持 Pixel 和部分三星 Galaxy 设备。这个时间点很微妙——OpenAI 的 Operator 今年 1 月发布,Anthropic 的 Computer Use 去年 10 月就开放了 API,谷歌算是后发。但谷歌的优势在于系统级集成:Gemini Intelligence 是安卓原生能力,不需要额外安装应用,权限管理也更细粒度。
从技术实现看,Chrome 自动浏览依赖 Gemini 的视觉理解和推理能力。它需要把网页渲染结果转成视觉输入,理解页面布局和交互元素,然后生成操作序列。这跟 Anthropic 的 Computer Use 思路类似,但谷歌强调了「边界」——Gemini 只在用户授权的应用中工作,只处理用户明确指派的任务。这是对隐私和安全的妥协,也是移动端 Agent 必须面对的约束。
端云协同:算力分配的务实选择
Gemini Intelligence 采用端侧和云端结合的架构。简单请求交给设备本地的 Gemini Nano 处理,复杂任务调用云端 Gemini。这个策略很务实——端侧模型延迟低、隐私好,但能力有限;云端模型能力强,但有网络开销和隐私顾虑。
Gemini Nano 是谷歌专门为移动设备优化的轻量模型,参数量在 10 亿级别,能在旗舰手机的 NPU 上实时运行。它主要处理文本改写、简单问答、本地数据检索这类任务。遇到需要复杂推理、多步规划、外部工具调用的任务,系统会自动切换到云端 Gemini(可能是 Gemini 1.5 Pro 或更新版本)。
这种端云协同不是新鲜事,苹果的 Apple Intelligence 也是类似架构。关键在于切换策略——什么任务在端侧做,什么任务上云,怎么在延迟、成本、隐私之间平衡。谷歌没有公开具体策略,但从演示看,表单填写、小组件生成这类任务应该是云端处理,因为需要理解复杂语义和生成代码。
从开发者角度看,端云协同意味着 Gemini Intelligence 的能力上限取决于云端模型。如果谷歌持续升级云端 Gemini(比如推出 Gemini 2.0),端侧体验会自动提升,不需要等系统更新。这是云原生 AI 的优势,也是谷歌相比苹果的差异化——苹果的端侧模型更新依赖 iOS 版本,谷歌可以随时升级云端能力。
Create My Widget:自然语言生成 UI
Gemini Intelligence 还包含两个新工具,其中 Create My Widget 很有意思。用户用自然语言描述需要的小组件功能,Gemini 生成对应代码并渲染出来。比如用户说「做一个显示今天步数和卡路里的小组件,背景用渐变色」,Gemini 会生成 Android Widget 代码,用户可以直接添加到主屏幕。
这个功能本质上是代码生成,但包装成了「vibe-coded widgets」(氛围感编程小组件)。谷歌的产品语言很有意思,不说「AI 生成代码」,而是强调「用自然语言表达你想要的感觉」。这种包装降低了技术门槛,让普通用户觉得自己在「设计」而不是「编程」。
从技术实现看,Create My Widget 依赖 Gemini 的代码生成能力和 Android Widget API 的标准化。Widget 的代码结构相对固定(布局、数据绑定、更新逻辑),适合用模板+填充的方式生成。难点在于理解用户的模糊描述——「渐变色」具体是什么颜色?「步数」数据从哪里取?Gemini 需要做语义理解、参数推断、API 调用,然后生成可执行代码。
这个功能的想象空间在于可扩展性。如果谷歌开放 Widget 生成的 API,第三方应用可以接入,用户就能用自然语言定制任何应用的小组件。更进一步,如果扩展到应用内 UI 生成,用户可以说「把这个按钮改成圆角、放到右上角」,Gemini 直接修改界面。这是 AI 原生交互的一种可能性。
Gboard Rambler:语音输入的润色层
Gboard 的 Rambler 模式针对语音输入场景。用户口述内容时经常会重复、修改、插入补充,最后的文本很乱。Rambler 会实时整理这些杂乱表达,输出流畅的文本。
这个功能看起来简单,但解决的是语音输入的核心痛点。传统语音转文字是「所见即所得」,用户说什么就转什么,包括口误、重复、语气词。Rambler 加了一层语义理解和文本重构,把口语化表达转成书面语。
从技术实现看,Rambler 需要实时处理语音流、理解语义、生成润色文本。这对延迟要求很高——用户不能等几秒才看到结果。谷歌应该是用端侧 Gemini Nano 处理,因为云端延迟太高。这也说明 Gemini Nano 的文本生成能力已经足够应对实时润色任务。
Rambler 的应用场景很广:写邮件、记笔记、发消息、写文档。对于不擅长打字或需要快速输入的用户,这是刚需。更重要的是,它降低了语音输入的心理门槛——用户不用担心说错话,反正 AI 会帮你整理好。
推送策略:分批灰度,旗舰先行
谷歌计划从今年夏季开始分批推送 Gemini Intelligence 功能。首批支持 Pixel 和部分三星 Galaxy 旗舰机,Chrome 自动浏览从 6 月开始启动。这个推送策略很保守,说明谷歌对 Agent 能力的稳定性还不够自信。
从产品成熟度看,Gemini Intelligence 还处于早期阶段。表单填写、小组件生成这类任务相对可控,但 Chrome 自动浏览涉及复杂的多步骤操作,出错概率高。谷歌选择先在自家 Pixel 和三星旗舰上测试,收集反馈后再扩大范围,是稳妥的做法。
另一个考量是算力成本。Gemini Intelligence 的云端调用会产生大量推理请求,谷歌需要控制规模避免成本失控。分批推送可以平滑流量增长,也给基础设施扩容留出时间。
从竞争格局看,谷歌这次升级是对 OpenAI 和 Anthropic 的直接回应。OpenAI 的 Operator 已经在桌面端展示了 Agent 能力,Anthropic 的 Computer Use API 也在快速迭代。谷歌的优势在于移动端的系统级集成,但劣势是推送速度慢——安卓生态的碎片化意味着大部分用户要等很久才能用上新功能。
Android Auto 和车机集成
谷歌还提到,支持 Android Auto 的车机也会获得 Gemini Intelligence 能力。这是个有意思的扩展场景——车载环境下,用户的双手和视线都被占用,语音交互是刚需。Gemini 如果能在车机上代用户完成导航规划、音乐播放、消息回复,体验提升会很明显。
但车机场景的挑战也更大。首先是安全性——AI 操作不能干扰驾驶,必须有明确的确认机制。其次是网络依赖——车机的网络环境不稳定,云端调用可能失败。最后是权限管理——车机通常是多人共用,Gemini 需要区分不同用户的数据和权限。
谷歌没有公布车机功能的具体细节,但从产品逻辑看,车机版 Gemini Intelligence 应该会更保守,主要处理导航、通信、媒体控制这类低风险任务,不会开放 Chrome 自动浏览这种高风险能力。
与竞品对比:移动端 Agent 的差异化
把 Gemini Intelligence 和竞品对比,能看出几个关键差异:
vs OpenAI Operator:Operator 是桌面浏览器插件,依赖 Chrome 扩展 API,能力上限是浏览器内操作。Gemini Intelligence 是系统级能力,可以跨应用调度,但只在移动端可用。Operator 的优势是跨平台(Windows/Mac/Linux 都能用),Gemini Intelligence 的优势是深度集成(可以调用安卓系统 API)。
vs Anthropic Computer Use:Computer Use 是通过截图+鼠标键盘模拟实现的通用 Agent,理论上可以操作任何桌面应用。Gemini Intelligence 是通过系统 API 和应用集成实现的,更高效但依赖应用支持。Computer Use 的优势是通用性,Gemini Intelligence 的优势是性能和权限管理。
vs Apple Intelligence:苹果的 AI 策略更保守,主要做端侧推理和隐私保护,Agent 能力有限。Gemini Intelligence 更激进,直接做跨应用、跨网页的任务自动化。苹果的优势是隐私和生态控制,谷歌的优势是 AI 能力和云端资源。
从产品定位看,Gemini Intelligence 是谷歌在移动端建立 Agent 护城河的尝试。桌面端已经有 Operator 和 Computer Use,移动端还是空白。谷歌如果能在安卓上建立 Agent 标准,就能在下一代交互范式中占据主动。
开发者视角:API 和生态
谷歌没有公布 Gemini Intelligence 的开发者 API,但从产品逻辑看,未来应该会开放。如果第三方应用能接入 Gemini Intelligence,用户就能用自然语言操作任何应用——「帮我在美团上点一份外卖」「帮我在携程上订明天去上海的机票」。这是 Agent 生态的终极形态。
但开放 API 的挑战在于权限管理和安全审核。Gemini 需要访问应用数据、执行应用操作,这涉及敏感权限。谷歌需要建立一套审核机制,确保第三方应用不会滥用 Agent 能力。这跟微信小程序、iOS App Clips 的逻辑类似,但复杂度更高。
从商业模式看,Gemini Intelligence 可能会成为谷歌的新增长点。如果开发者需要付费接入 API,或者谷歌对 Agent 调用收费,这会是一笔可观的收入。更重要的是,Agent 能力会增强用户对安卓生态的依赖,提升谷歌在移动端的话语权。
对于国内开发者,Gemini Intelligence 的 API 可以通过 OpenAI Hub 这类聚合平台调用。OpenAI Hub 支持 Gemini 系列模型,兼容 OpenAI 格式,国内直连无需翻墙。如果谷歌未来开放 Gemini Intelligence 的 Agent API,通过聚合平台接入会是更便捷的选择。
隐私和安全:Agent 的阿喀琉斯之踵
谷歌反复强调 Gemini Intelligence 的边界:只在用户授权的应用中工作,只处理用户明确指派的任务。这是对隐私担忧的回应,也是 Agent 产品必须面对的核心问题。
Agent 的能力越强,隐私风险越大。Gemini 需要读取用户数据(邮件、日历、联系人、浏览历史)、访问第三方应用(银行、电商、社交)、执行敏感操作(转账、下单、发消息)。任何一个环节出问题,后果都很严重。
谷歌的应对策略是细粒度权限管理。用户可以控制 Gemini 访问哪些应用、读取哪些数据、执行哪些操作。每次执行敏感任务前,Gemini 会请求确认。这跟安卓的权限系统一脉相承,但粒度更细。
另一个风险是 Agent 被滥用。如果黑客能诱导 Gemini 执行恶意操作(比如转账、泄露数据),后果不堪设想。谷歌需要在模型层面做安全对齐,确保 Gemini 不会执行明显有害的指令。这是 AI 安全的经典问题,没有完美解决方案,只能持续迭代。
从用户角度看,Agent 的信任成本很高。用户需要相信 Gemini 不会误操作、不会泄露隐私、不会被黑客利用。这种信任需要时间建立,也很容易被一次事故摧毁。谷歌在推送策略上的保守,很大程度上是为了降低风险。
总结:移动端 Agent 的起点
Gemini Intelligence 是谷歌在移动端 Agent 领域的第一次系统性尝试。从产品能力看,它已经超越了传统语音助手,开始具备真正的任务自动化能力。但从成熟度看,它还处于早期阶段,很多功能需要在实际使用中验证。
这次升级的意义不在于功能本身,而在于方向。谷歌明确了 Gemini 的定位——不是聊天机器人,而是能代用户干活的 Agent。这个定位会影响后续所有产品决策:UI 设计、权限管理、API 开放、商业模式。
从竞争格局看,移动端 Agent 还是蓝海。OpenAI 和 Anthropic 专注桌面端,苹果的 AI 策略保守,谷歌有机会在安卓上建立先发优势。但挑战也很明显:安卓生态碎片化、隐私和安全风险、用户信任成本。
对开发者来说,Gemini Intelligence 是值得关注的方向。如果谷歌开放 API,移动应用的交互范式会发生根本变化——从「用户操作应用」变成「用户指挥 Agent 操作应用」。这是下一代移动互联网的可能形态。
最后,Gemini Intelligence 的推出也验证了一个趋势:AI 的下一个战场不是更强的模型,而是更好的 Agent。模型能力已经足够强,关键是怎么把能力转化成用户价值。谷歌这次升级,是在移动端探索这个问题的答案。
参考来源
- 谷歌今夏推进 Gemini Intelligence:重塑安卓手机 AI 交互,可操控浏览器填写表单等 - IT之家 - IT之家对 Gemini Intelligence 功能的详细报道