小米开源 OneVL:把 VLA 和世界模型塞进一个框架
5 月 13 日,小米技术正式开源了自动驾驶大模型 Xiaomi OneVL,全称是"一步式潜空间语言视觉推理框架"。这事之所以值得单独讲一下,不是因为又多了一个开源模型,而是它把过去两年自动驾驶圈子里最热的两条路线——VLA 和世界模型——用一套架构搅到了一起。
这是一个长期被看作是"你选一边站"的问题,小米说不用选了。
先说为什么这件事不无聊
过去两年,做端到端自动驾驶的基本上分成两派。
一派是 VLA(Vision-Language-Action):把大语言模型那套认知能力引进来,模型看到路况后先用语言把场景"想一遍",再输出方向盘和油门。优点是有解释性、能泛化到长尾场景;缺点是慢,显式的 Chain-of-Thought 一跑起来,推理延迟就上去了,对实时性要求苛刻的车端是个硬伤。
另一派是 世界模型(World Model):不直接出动作,而是预测"接下来这条路、这些车、这些人会变成什么样",然后基于预测结果做规划。优点是对物理世界有建模,能处理动态交互;缺点是它本身不直接产生驾驶决策,得再接一层。
这两条路线长期是分开走的。你去看行业里的论文和产品,要么 VLA 做主线,世界模型当辅助训练信号;要么反过来。OneVL 的做法是:把推理过程挪到潜空间(latent space)里跑,让 VLA 的决策链和世界模型的未来预测共享同一套中间表征。
换句话说,模型在脑子里想"我该怎么开"的时候,同时也在想"前面那辆车会怎么动",两件事不是串行的两步,而是同一个潜变量序列的两个投影。
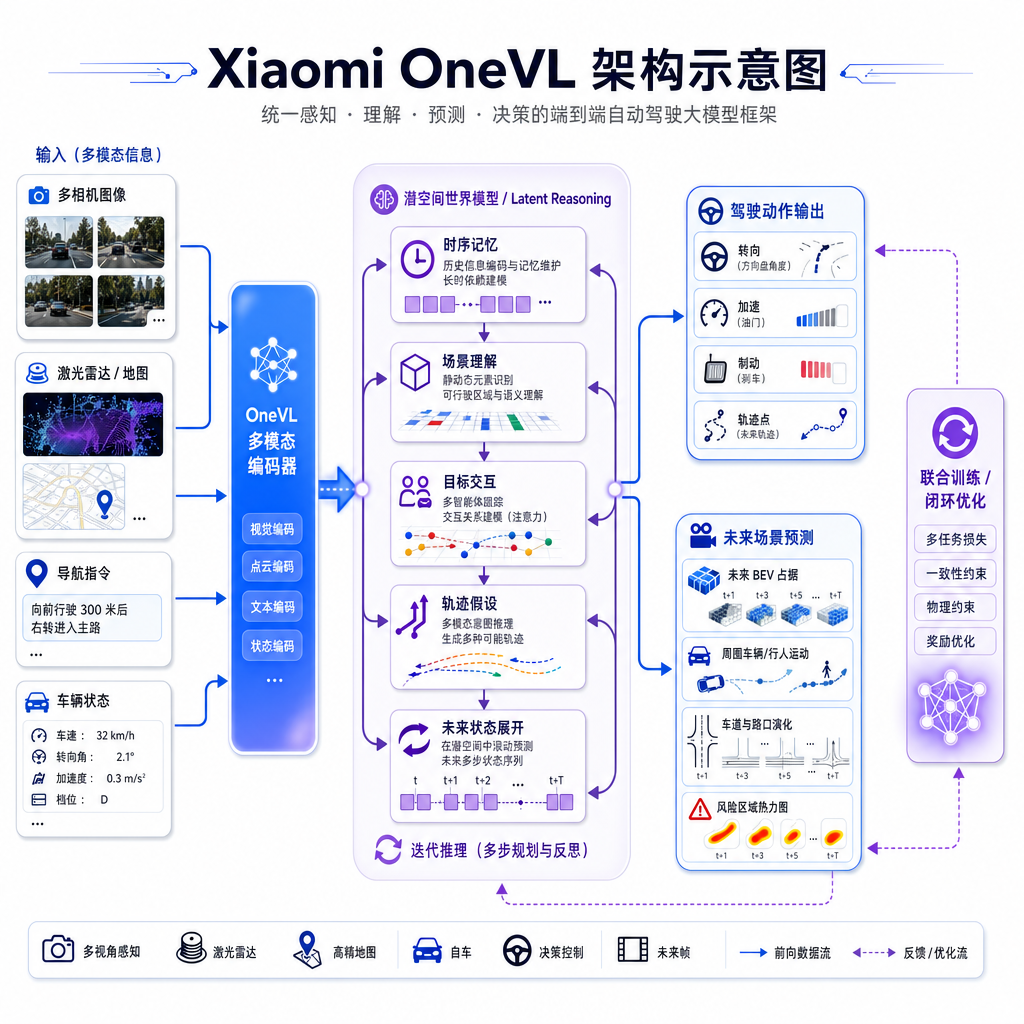
潜空间 CoT 解决了什么
要理解 OneVL 的技术创新,得先搞清楚"显式 CoT"和"潜空间 CoT"的区别。
显式 CoT 就是 DeepSeek-R1、o1 那种思考方式,模型把推理过程用自然语言一个 token 一个 token 吐出来,你能看到它在"思考"。好处是可解释、精度高,坏处是慢得离谱——车端场景下,你不可能让模型花两秒钟先写一段"前方有行人,我观察到他在看手机,可能要横穿,所以我决定减速"再去刹车。
"仅答案"预测是另一个极端,直接出结果,不思考过程,快但容易在复杂场景翻车。
潜空间 CoT 的思路是:让思考过程发生在连续的隐向量空间里,不强制把中间步骤翻译成语言 token。这样一来,一次前向推理就能完成多步思考,推理步数从几十步压到个位数甚至一步。这也是 OneVL 名字里"一步式(One-step)"的由来。
小米给出的对标是挺直接的:
- 精度上:超越显式 CoT 方案
- 速度上:对齐"仅答案"预测的潜空间 CoT 方案
如果数据为真,这相当于把慢的方案提了速,同时把快的方案提了精度。这是过去学术圈一直想做但做不稳的事。
基准成绩
OneVL 在四个主流基准上做了验证,覆盖了感知、推理、规划三个维度:
| 基准 | 场景 | OneVL 表现 |
|---|---|---|
| ROADWork | 施工区等长尾场景 | SOTA |
| Impromptu | 即兴驾驶推理 | SOTA |
| Alpamayo-R1 | 复杂推理规划 | SOTA |
| NAVSIM | 常规闭环仿真 | 优越性能 |
值得留意的是 ROADWork 和 Impromptu 这两个——它们都是针对"非标准路况"设计的基准。自动驾驶里最难啃的从来不是高速巡航,是施工区临时改道、突发障碍、交警手势这种需要"想一下"的场景。OneVL 在这两个上拿 SOTA,说明潜空间推理在长尾场景里确实扛得住。
NAVSIM 那一项用词是"优越性能"而不是 SOTA,说明在常规场景下没有拉开压倒性优势,这倒也符合直觉——常规场景本来就是"仅答案"方案的舒适区。
可解释性没丢
潜空间推理最容易被质疑的一点是"黑盒"——你把思考过程藏到隐向量里了,那出了事怎么追责?
OneVL 在这里做了个取巧的设计:语言和视觉双维度的可解释性。
- 语言侧:模型可以用文字说明"为什么这样开",比如"因为前车刹车灯亮了所以减速"
- 视觉侧:模型可以渲染出未来几秒的预测画面,让你看到"它以为接下来会发生什么"
这两条解释不是推理路径本身,更像是潜空间推理的"事后注释"。从工程角度说,这个妥协是合理的——车端实时跑的时候走潜空间快速通道,需要审查、调试、验证的时候把解释头打开看看。两者解耦,不互相拖累。

开源的诚意
这次小米放出来的东西挺齐的:
- 模型权重:完整可下载
- 训练代码:能复现
- 推理代码:能直接部署
- 技术报告:arXiv 上已挂出
项目主页和 GitHub 仓库一起开了:
项目主页:Xiaomi-Embodied-Intelligence.github.io/OneVL
GitHub:github.com/xiaomi-research/onevl
这和小米之前和华科合作的 UniDriveVLA 是一条线下来的。那个项目做的是解耦感知与推理,OneVL 在它的基础上又往前走了一步,把世界模型也吃进来。负责这条线的是小米智驾的陈龙团队,之前雷峰网报道过他们做的统一具身与自动驾驶的开源模型,在 17 项具身任务和 12 项自动驾驶任务上都拿了领先成绩。
陈龙在 21 财经的采访里讲了一句话我觉得挺到位:
"潜空间思考的优势,就是我不限制模型去想什么,也不限制你用什么方式思考,我们最终的目的是让模型学会驾驶。"
这其实回应了 VLA 派一直以来的一个隐疾——你用自然语言去约束模型的思考过程,本质上是把人类的推理范式强加给了模型。人看到一辆车冲过来会想"糟糕要撞了",但模型未必要走这条语言路径才能做出正确反应。潜空间推理把这个约束拿掉了。
对行业的影响
自动驾驶大模型这个赛道,过去一年的玩家基本分三类:
- 特斯拉路线:闭源、端到端、视觉为主,不公开技术细节
- 华为、蔚小理路线:工程化优先,模型能力和硬件深度绑定
- 开源研究路线:高校和部分厂商主导,论文多但落地少
小米这次的动作比较特别,它是一家真在量产车的厂商,把量产背后的技术路线直接开源了。这对第三类玩家的影响会比较直接——过去研究圈很多工作是在 NAVSIM 之类的仿真基准上刷点,现在有了一个来自量产方的开源基线,后续论文的对比对象估计要换一换了。
对第一、第二类玩家的影响不会立竿见影。工程化的自动驾驶不是把权重下下来就能用的,数据闭环、安全冗余、硬件适配每一项都是壁垒。但 OneVL 证明了"VLA + 世界模型统一"这条路在工程上是可走的,这个信号会传导到其他厂商的技术选型里。
开发者能拿它做什么
如果你是做自动驾驶研究或者具身智能的开发者,OneVL 现在可以:
- 直接拉权重在 NAVSIM 上跑 baseline
- 把潜空间推理模块拆出来移植到自己的 VLA 模型里
- 基于世界模型预测头做数据增强或者仿真训练
- 复现技术报告里的实验,验证 SOTA 声明
对做通用多模态模型的开发者,OneVL 的潜空间 CoT 设计也值得看一眼——它本质上是一种通用的推理加速思路,不止自动驾驶能用。
一点保留意见
说几个我还在观望的点。
第一,潜空间 CoT 的训练稳定性一直是个老问题。显式 CoT 有明确的 token 级监督信号,潜空间里没有,很容易训着训着塌陷成"仅答案"模式。OneVL 具体怎么稳住训练过程,技术报告里的细节得扒一扒。
第二,四个基准里有三个是近两年才出现的新基准,样本规模和评测协议还没经过大规模复现验证。SOTA 这个词在快速迭代的基准上含金量要打折。
第三,可解释性的"事后注释"设计,本质上没有回答"潜空间里到底在想什么"这个问题。如果未来模型出了决策事故,语言解释可能和实际决策路径对不上,这在安全认证层面是个麻烦。
不过这些都是技术深水区的问题,不影响 OneVL 作为一个开源贡献的价值。
小结
OneVL 干的事情用一句话总结:把自动驾驶里"怎么开"和"会发生什么"这两个一直分开建模的问题,放进同一个潜空间里一次性解决,快且准。
它不是第一个尝试统一 VLA 和世界模型的工作,但它是第一个量产厂商把这个方案完整开源出来的。对研究圈是好事,对工程圈是参考,对用户最终会不会变成更聪明的辅助驾驶,还得看各家怎么消化。
代码和权重已经挂在 GitHub 上,感兴趣的可以直接去拉。
参考来源
- 小米开源 Xiaomi OneVL 自动驾驶模型(IT之家) — IT之家对 OneVL 发布的首发报道,含基准测试结果
- 小米开源 Xiaomi OneVL 讨论帖(linux.do) — 开发者社区的讨论和原始链接汇总
- OneVL 开源代码仓库(GitHub) — 模型权重、训练和推理代码