腾讯开源 Agent Memory:让长任务 Token 消耗降 61%
腾讯云今天正式开源 TencentDB Agent Memory,这是一套面向 Agent 长任务场景的记忆管理系统。在多任务连续 Session 实验中,该方案最高降低 61% Token 消耗,同时提升长任务场景下的任务成功率。
这不是又一个"摘要压缩"工具。腾讯云数据库团队用"上下文卸载 + Mermaid 任务画布"的组合拳,解决了 Agent 长任务中最棘手的问题:如何在保持轻量上下文的同时,让 Agent 知道自己在哪、做过什么、接下来该干什么。
项目已在 GitHub 开源:https://github.com/Tencent/TencentDB-Agent-Memory
Agent 长任务的真实困境
让 Agent 做一份竞品分析报告。它需要分别搜索竞品 A、B、C 的产品信息,再查各家的融资动态和技术方案,最后汇总成对比表。每一步搜索返回约 2000 字原文,其中真正有用的可能只是"竞品 A 最新融资 2400 万美元、主打向量检索"这样一句结论。
到汇总步骤时,上下文里已经堆了上万字的搜索引擎原文,绝大部分是广告、无关链接和重复信息——它们占着宝贵的 Token 额度,却对完成任务毫无帮助。更要命的是,20 次工具调用之后,上下文里堆着一长串线性历史。Agent 能看到"做过什么",但不容易判断哪些是并行分支、哪些步骤有前置依赖、当前处于哪个阶段。
这就是 Agent 在代码开发、网页搜索、研究分析等场景中面临的现实:任务链路持续变长,大量工具调用、网页内容和中间结果快速占满上下文窗口,导致 Token 成本上升、任务状态丢失以及推理稳定性下降。
Mermaid 任务画布:给 Agent 一张作战地图
长任务里最危险的事,不是信息丢了,是 Agent 不知道自己走到哪。
流水账适合记录,地图适合导航。腾讯云数据库团队用 Mermaid Flowchart 把任务执行过程组织成一张可导航的任务画布。
Mermaid 是 GitHub 和技术文档中广泛使用的图描述语言,主流大模型天然具备读写能力,纯文本格式,可持续更新,人也能直接渲染查看。通过这张画布,Agent 不需要记住所有内容,只需要知道哪些信息重要、它们被组织在哪里,以及必要时如何一步步展开。
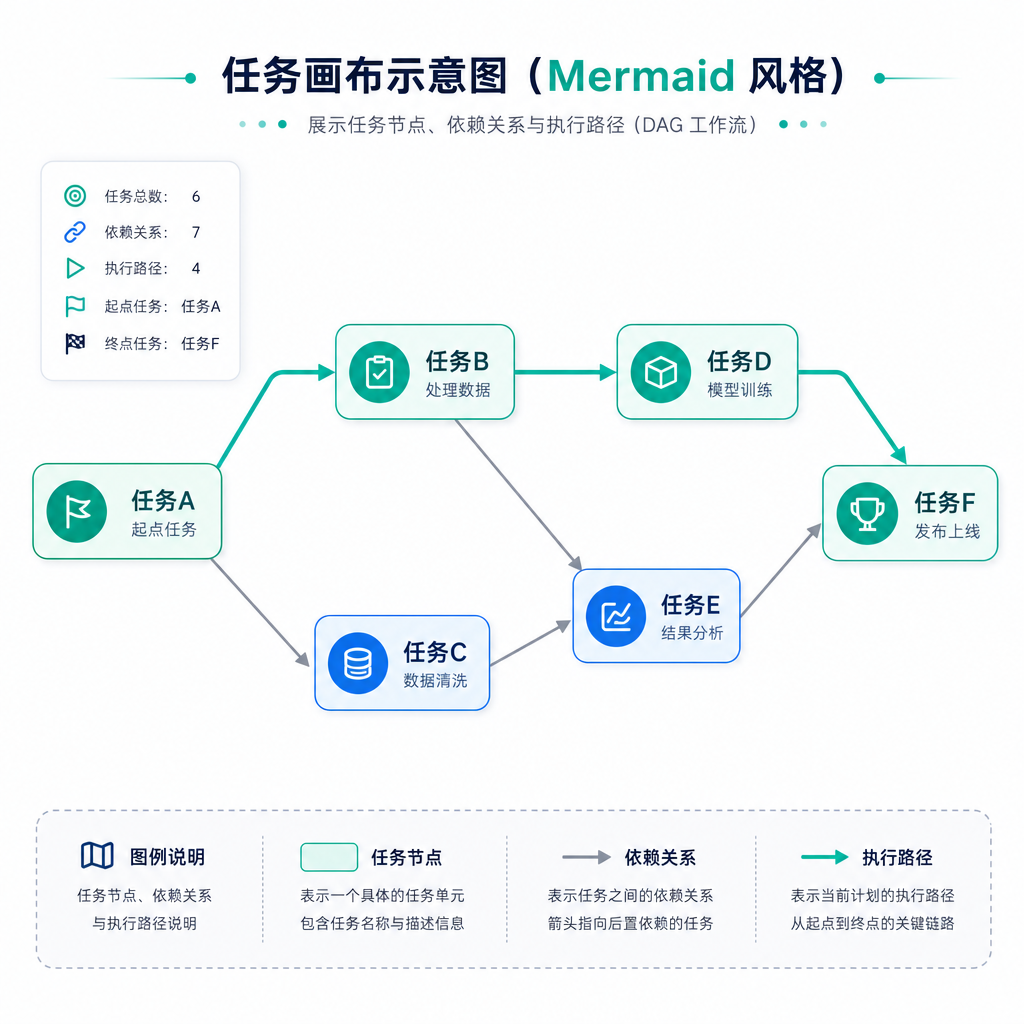
系统为每个任务维护一张独立的 Flowchart,并通过"折叠/展开/复活"策略管理它们在上下文中的存在:
- 当前任务的地图完整展开,Agent 随时能看到全貌
- 已完成任务被折叠为一行摘要,需要时可以展开
- 并行分支在地图上清晰标注,避免执行混乱
历史没有被压成一段不可恢复的摘要。它变成了一张可以继续执行的地图——能折叠,也能展开。
上下文卸载:省 Token,没丢证据
画布解决"结构不能丢",但长任务中工具返回、搜索结果、日志输出等原始信息往往非常长,全部留在上下文里窗口很快被填满。
Agent Memory 的另一个核心技术是上下文卸载(Context Offloading)——将完整信息卸载到外部存储,同时以结构化任务图保留关键状态与执行路径,使 Agent 在长任务中保持轻量上下文,同时支持原始信息的逐层追溯与恢复。
符号化压缩:用更少的 Token 表达等量信息
短期记忆压缩的第一个核心能力是符号化压缩(Symbolic Compaction)——用更少的 Token 表达等量的信息。这里的"压缩"分两层:
第一层:摘要压缩——去掉废话,留下事实。
一次搜索返回 2000 字原文,真正有信息量的可能只是"竞品 A 最新融资 2400 万美元..."这一句话。系统将它提炼为一行结构化摘要,例如:
[搜索 done] 竞品A: 融资$24M, 客户200+ | ref: refs/001-N1.md
80 字表达 2000 字的核心信息,压缩比 25:1。同时末尾的 ref 指针指向磁盘上的原始全文,需要时随时回查。
第二层:结构化存储——原始信息不是丢了,是搬家了。
所有被压缩的原始内容都存入外部存储(虚拟文件系统),并通过引用指针关联到任务画布上的对应节点。Agent 需要时可以通过指针一步步展开,恢复完整上下文。
三级水位自动触发
Agent Memory 采用三级水位机制,根据上下文占用情况自动触发不同级别的压缩:
- L0 原文(默认):工具返回的原始结果直接保留在上下文中
- L1 摘要(实时):当上下文占比达到 60% 时,自动用摘要替换原文——这是"温和压缩",信息损失最小
- L2 地图(异步):系统定期根据已积累的摘要,自动绘制或更新 Mermaid 任务地图,并注入到上下文中。完成的任务会被"折叠"为一行摘要,当前任务的地图则完整展开
这套机制的巧妙之处在于:压缩是渐进的、可逆的、自动的。Agent 不需要手动管理记忆,系统会根据上下文压力自动调整粒度。
实测数据:Token 消耗降 61%,准确率提升 28%
在多任务连续 Session 实验中,TencentDB Agent Memory 最高降低 61% Token 消耗,同时提升长任务场景下的任务成功率。
在 Free 版中,TencentDB Agent Memory 已通过四层记忆架构实现长期记忆增强,并在 PersonaMem 评测集上将总准确率从 47.85% 提升到 76.10%——提升幅度达 28 个百分点。
这个数据的含金量在于:它不是通过牺牲信息完整性换来的。Agent 依然能访问所有原始信息,只是访问路径从"全部塞在上下文里"变成了"按需从外部存储加载"。
对比其他方案:不只是压缩,是导航
市面上不乏记忆管理方案,但大多数要么只做摘要压缩(信息损失大),要么只做外部存储(Agent 不知道存了什么)。
以 MemMachine 为例,它采用虚拟文件系统 + L0/L1/L2 三层按需加载的方案,解决了外部知识的存储问题,但缺少结构化任务拓扑。Agent 知道"有哪些文件",但不知道"这些文件之间是什么关系、当前任务处于什么阶段"。
TencentDB Agent Memory 的差异化在于:
| 维度 | MemMachine | TencentDB Agent Memory |
|---|---|---|
| 压缩方式 | 分层存储 | 符号化压缩 + Mermaid 任务地图 |
| 信息组织 | 虚拟文件系统 | 结构化任务拓扑 |
| 触发机制 | 手动/规则 | 三级水位自动触发 |
| 可追溯性 | 文件级 | 节点级 + 引用指针 |
简单说:MemMachine 给 Agent 装了一个硬盘,TencentDB Agent Memory 给 Agent 装了一个硬盘 + 一张地图 + 一套自动整理系统。
长期记忆已上线,短期记忆刚开源
值得注意的是,腾讯云在上月已经上线了 TencentDB Agent Memory 的长期记忆能力,并提供免费使用。这次开源的重点是短期记忆压缩。
长期记忆解决的是"Agent 如何记住用户偏好、历史交互、领域知识"的问题,短期记忆压缩解决的是"Agent 如何在单次长任务中保持轻量上下文"的问题。两者结合,才能让 Agent 既有"长期积累的智慧",又有"当下任务的清醒"。
目前 TencentDB Agent Memory Pro 版已上线至 ClawPro 最新版本中,用户可以前往 ClawPro 的管控端,点击左侧的"记忆管理"后快速开启。
Agent 记忆系统正在成为标配
2025 年下半年,AI Agent 集体落地的一个显著趋势是:记忆系统正在成为标配。
最新研究表明,高效记忆机制可使复杂任务成功率提升 30-50%,Token 消耗降低 60-90%,并显著增强个性化与上下文连贯性。这一转变不仅关乎用户体验,更直接决定 Agent 在企业级场景中的可用性。
以通用自进化 Agent 为例,仅需 30k 上下文,token 消耗降近 9 成。在任务完成率、工具使用效率、记忆有效性、自进化能力和网页浏览等维度上,性能超过主流 Agent 系统的同时,所消耗 token 数和交互轮数也更少。
腾讯云这次开源 TencentDB Agent Memory,某种程度上是在为行业提供一个"记忆系统的参考实现"。它不是最复杂的方案,但可能是最实用的方案——开发者可以直接集成,也可以基于它的思路改造自己的 Agent 架构。
写在最后
Agent 的记忆问题,本质上是一个工程问题:如何在有限的上下文窗口里,让 Agent 既能看到全局,又能聚焦当下。
腾讯云的答案是:不要试图把所有信息都塞进上下文,而是给 Agent 一张地图,让它知道信息在哪、如何获取、何时需要。这个思路不新鲜,但实现得很扎实。
61% 的 Token 消耗降低,不是靠牺牲信息完整性换来的,而是靠更聪明的信息组织方式。这才是这个开源项目最值得关注的地方。
参考来源
- 腾讯开源 TencentDB Agent Memory - IT之家 - 官方发布消息
- 腾讯云发布企业级 Agent Memory 服务 - 知乎 - 技术细节解读
- TencentDB Agent Memory GitHub 仓库 - 开源代码