商汤开源 U1:扔掉 VAE,像素直出
商汤刚发布了 SenseNova U1 的技术报告,这次动静不小。模型已经在 4 月 28 日开源,Apache 2.0 协议,两个版本(8B-MoT 和 A3B-MoT)都能商用。发布后直接冲上 Hugging Face Trending 榜,在最近扎堆发布的开源多模态模型里,这个热度确实少见。
配合模型发布,商汤还推出了 SenseNova Token Plan,首月每 5 小时送 1500 次免费调用,Token 消耗比同行低 60%。同时上线的还有 SenseNova 6.7 Flash-Lite 多模态智能体模型和 SenseNova-Skills 办公技能套件。
架构革新:不要 VAE,直接像素
过去的文生图模型都是先把像素的 RGB 值转成向量,扔进潜空间(VAE 层)处理。这个做法已经用了好几年,大家都习惯了。U1 的 NEO-Unify 架构直接把这套扔了,改成像素输入、像素输出,让模型直接理解图片本身,而不是潜空间里的抽象表征。
这不是为了炫技。传统架构更像"多人协作、层层转述":视觉编码器看图,翻译成语言,语言模型理解推理,再翻译成设计指令,最后画出来。每次信息传递都有损耗,只能靠堆参数弥补。NEO-Unify 是"一个全能大脑,直接理解、直接表达",少了中间转译,信息密度更高,效率也更高。
数据说话:2B 参数的 NEO-Unify 模型在 MS COCO 2017 图像重建基准上跑出 31.56 PSNR、0.85 SSIM,跟业界标杆 Flux VAE(32.65 PSNR、0.91 SSIM)差距不到 1 个百分点。关键是 Flux VAE 是专门为生成优化的独立组件,U1 是用统一架构顺带完成的。跟同类统一模型 BAGEL 比,NEO-Unify 用更少的训练 token 拿到更好的效果,数据效率优势明显。
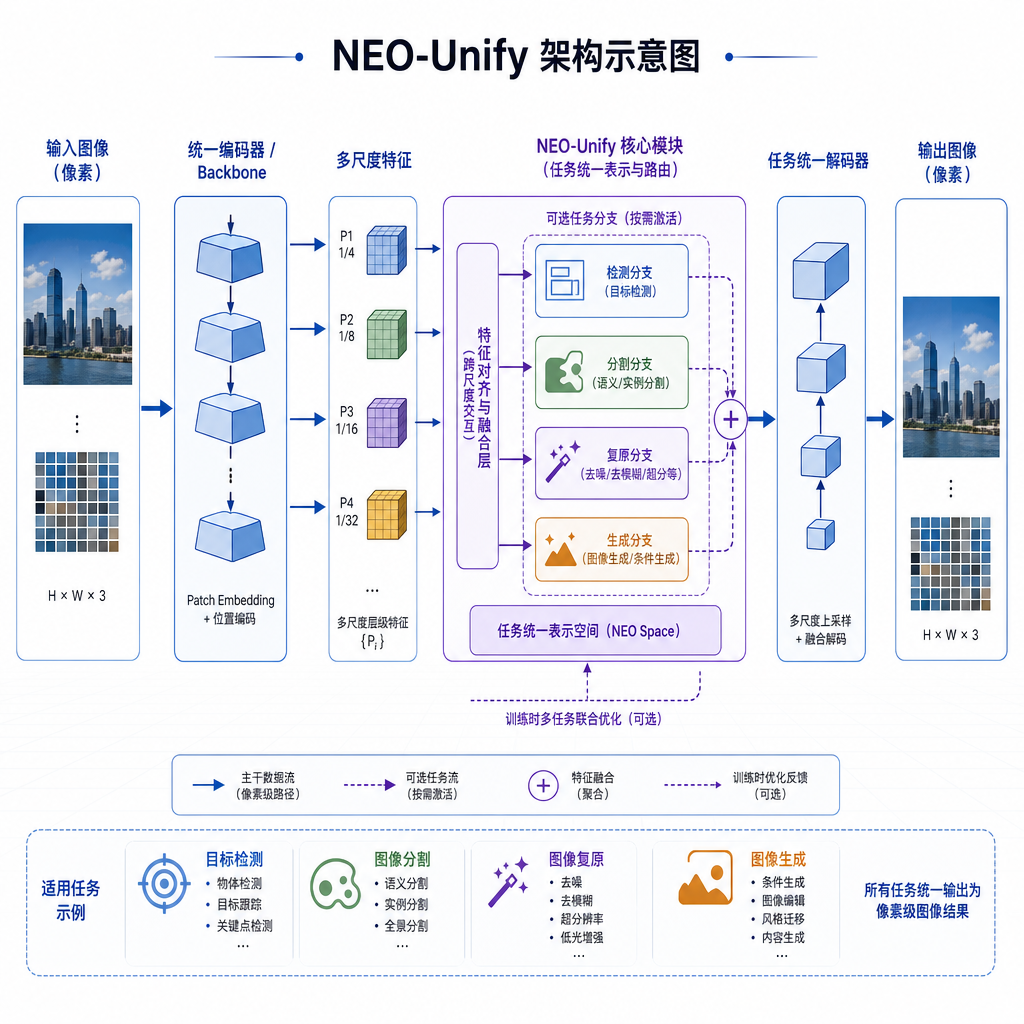
技术细节上,NEO-Unify 用 2 层卷积实现 32 倍图像压缩编码,MLP 头部直接预测像素。引入动态噪声缩放(DNS)技术,保证从 512px 到 2048px 分辨率下信噪比(SNR)一致。原生 MoT(Mixture-of-Transformers)架构让理解和生成流共享自注意力层,但用解耦的 FFN 和 Norm 层,根据 Token 类型动态路由。
训练方法也跟传统扩散模型不一样。结合自回归和流匹配损失函数优化,经历预热、指令微调到 8 步蒸馏的 6 阶段训练流水线。
训练数据:理解和生成分开喂
数据配比很讲究。理解类数据预训练混合比例:图文对 32%、纯文本 37%、详细描述 17%、信息图表 14%。中期训练用 SenseNova V6.5 数据集,通过采样平衡、提示词增强、模型自动化评分做多维度过滤。
生成类数据全部走 VLM 重标注流水线。所有图像(自然、设计、人像、合成)都去重和重标注,确保文本和像素语义对齐。数据分布:生活方式 44%、信息图表 29%、推理 8%。
推理样本全部包含思维链(CoT)过程,在渲染像素前先让模型理解场景逻辑。这个设计在复杂信息图生成上效果明显,模型能更好地控制排版和文字。
性能:8B 打平商业闭源
多模态理解上,A3B-MoT 在 MMMU 达 80.55、MMMU-Pro 达 72.83、OCRBench 达 91.90。文本密集图像和通用视觉理解没因为统一生成被削弱。
生成方面,GenEval 总分 0.91-0.92,组合、计数、颜色、位置、属性绑定都稳定。OneIG 英/中文文本维度最高 0.969/0.977,LongText-Bench 英/中文 0.979/0.962,长文本渲染能力突出。
在图文交错生成(OneIG 中英文、LongText 中英文、CVTG)和信息图专项(BizGenEval Easy/Hard、IGenBench)的延迟-性能综合对比里,U1 在同等延迟区间内综合表现领先 Nano-Banana、Gemma-4 等主流开源模型,是目前开源模型的 SOTA。
跟商业闭源模型横向对比,U1 Lite 在通用图像生成上的输出质量已经跟 Qwen-Image 2.0 Pro、Seedream 4.5 持平。在信息图这个开源模型历来做不好的领域,同样达到商业级水准。推理响应速度还有明显优势。

首创连续图文创作
基于 NEO-Unify 架构,U1 在业内首个实现连续性图文创作输出。单次单模型调用就能输出高质量作品,效率比传统范式大幅提升。
原生图文理解生成能力能把图像和文本底层融合信号完整保留在上下文中。区别于过去只能用多模型串联勉强实现,U1 的图像间风格一致性明显更高,能在统一表征空间进行高效连贯思考。
实际例子:
任务一:五分熟牛排做法。U1 通过思考和规划产生分步过程,给每一步输出对应图像展示。各步骤图示表现出极高一致性。
任务二:绘制钢铁侠图案。从扫描草稿出发,逐步连续创作,最终做出完成度很高的图像。每一步创作对前一步的结构和细节都做了精准保持,统一表征的共享上下文在其中发挥关键作用。
这个能力在信息图生成、教程制作、连续故事创作等场景里很实用。过去要多次调用不同模型,现在一次搞定,风格还能保持一致。
6.7 Flash-Lite:看懂文档的智能体
同步发布的 SenseNova 6.7 Flash-Lite 是新一代多模态智能体模型。如果说 U1 是多才多艺的创作者,Flash-Lite 更像能管理全局的项目经理。
传统智能体模型常用"文本+视觉"拼接设计,视觉只是补充,信息损耗大、Token 成本高。Flash-Lite 采用原生多模态架构,取消视觉转文本中间层,直接理解网页、文档、图表等复杂内容,实现"看、想、做"一体化。
核心优势是成本大幅下降。信息搜索等场景 Token 消耗较纯文本智能体直降 60%,支持毫秒级响应,适配高频互动的生产环境。多项权威测试达同级别领先水平。
能力覆盖:
- 90 万行销售数据深度分析,自动识别数据异常并给出经营优化建议
- 自主撰写 8 章节行业调研报告,整合市场数据、生成可视化图表
- 为医院生成适老化就诊指引 PPT,风格统一、内容清晰
原生支持 OpenClaw、Hermes Agent 等智能体框架,配合开源的 SenseNova-Skills 办公技能套件,可以一键开启全自动办公。技能覆盖信息图生成、PPT 创作、数据分析、深度调研等高频场景,支持一键部署或灵活集成。
Token Plan:每 5 小时 1500 次免费
商汤推出 SenseNova Token Plan,开发者登录官网即可领取每 5 小时 1500 次免费调用额度,零成本体验 Flash-Lite 和 U1 Fast。后续还将推出 Lite、Pro 等付费档位。
Token 消耗比同行低 60%,加上首月免费额度,把试错成本压到最低。Apache 2.0 开源协议进一步消除开发者进入的心理门槛。
这个策略在大模型公司普遍想怎么收费的当下,算是反向操作。低成本 Token 输出让人不舍得走,开源协议降低技术门槛,配合完整的工具链(SenseNova-Skills),形成从架构创新到工具闭环再到成本优势的完整体系。
怎么看这次发布
U1 证明了一件事:VAE 导致的文字模糊和纹理丢失不是"必要代价"。只要架构选得对,原生像素生成比潜空间更强。8B 参数打平商业闭源模型,数据效率比同类统一模型高,这两点足够说明 NEO-Unify 架构的优势。
连续图文创作是个实用功能,不是噱头。过去要多次调用不同模型才能勉强实现,现在单次调用搞定,风格还能保持一致。在信息图生成、教程制作、连续故事创作等场景里,这个能力能直接提升工作效率。
Flash-Lite 的 Token 消耗直降 60% 也值得关注。原生多模态架构取消视觉转文本中间层,直接理解复杂内容,这个设计在信息搜索、数据分析等场景里能明显降低成本。配合每 5 小时 1500 次的免费额度,对开发者来说试错成本很低。
开源策略也很激进。Apache 2.0 协议,两个版本都能商用,配合完整的工具链和免费额度,这套组合拳在最近扎堆发布的开源多模态模型里算是诚意十足。
当然,U1 现在还是轻量版系列,商汤说正在沿着当前技术路径继续 Scale,计划推出体量更大的模型。基于高效的原生架构,能不能以更低计算成本达到国际顶尖模型水平,还得看后续大参数版本的表现。
但至少眼下,商汤给出了一个值得认真对待的答案:用一套从架构创新(NEO-Unify)到工具闭环(SenseNova-Skills)再到成本优势(Token Plan)的完整体系,把"原生统一多模态"从概念变成可交付的产品。
对开发者来说,U1 和 Flash-Lite 都值得试试。前者适合需要高质量图文创作的场景,后者适合需要处理复杂文档和数据分析的工作流。Apache 2.0 协议 + 免费额度 + 低 Token 消耗,这个组合在当前市场环境下确实有吸引力。
如果你在用 OpenAI Hub 调其他模型,可以关注一下商汤后续会不会接入。统一的 API 格式能让切换成本降到最低,多一个选择总是好事。
参考来源
- 商汤 SenseNova U1 GitHub 仓库 - 模型权重、技术文档和使用示例
- 商汤 SenseNova-Skills GitHub 仓库 - 开源办公技能套件
- Linux.do 社区讨论 - 开发者对 U1 技术报告的讨论和实测反馈