LangChain 发布 SmithDB:专为 Agent 观测设计的分布式数据库

LangChain 在 Interrupt 2026 大会上推出 SmithDB,这是一个用 Rust 构建的分布式数据库,专门解决智能体追踪数据过大、查询过慢的问题。P50 延迟降至 92ms,性能提升最高 12 倍。
LangChain 发布 SmithDB:专为 Agent 观测设计的分布式数据库
LangChain 刚在 Interrupt 2026 大会第一天宣布了 SmithDB——一个专门为智能体可观测性构建的分布式数据库。这不是又一个通用数据库的包装,而是针对 Agent 追踪场景从零设计的基础设施。
为什么需要专门的数据库?
问题很直接:Agent 的 trace 数据太大了,传统数据库扛不住。
一个典型的 Agent 执行过程可能包含几十次工具调用、多轮推理、大量的上下文切换,每个步骤都会产生结构化数据、非结构化文本、甚至多模态内容(图片、音频)。这些数据不仅体量大,而且关系复杂——你需要追踪整个调用链路,理解每一步的输入输出,定位性能瓶颈或错误节点。
用 Postgres 或 MongoDB 这类通用数据库存储 Agent traces,会遇到几个硬伤:
- 查询慢:加载一个完整的 trace tree 可能需要几秒钟,因为需要递归查询、拼接大量 JSON 数据
- 全文搜索更慢:在海量非结构化文本中搜索特定内容,传统数据库的全文索引力不从心
- 多模态内容存储低效:图片、音频这类 blob 数据塞进关系型数据库,既浪费空间又影响性能
- 扩展性差:随着 Agent 使用量增长,数据库很快成为瓶颈
LangChain 之前用的就是传统方案,LangSmith 用户抱怨最多的就是 trace 加载慢、搜索慢。SmithDB 就是为了解决这些问题而生的。
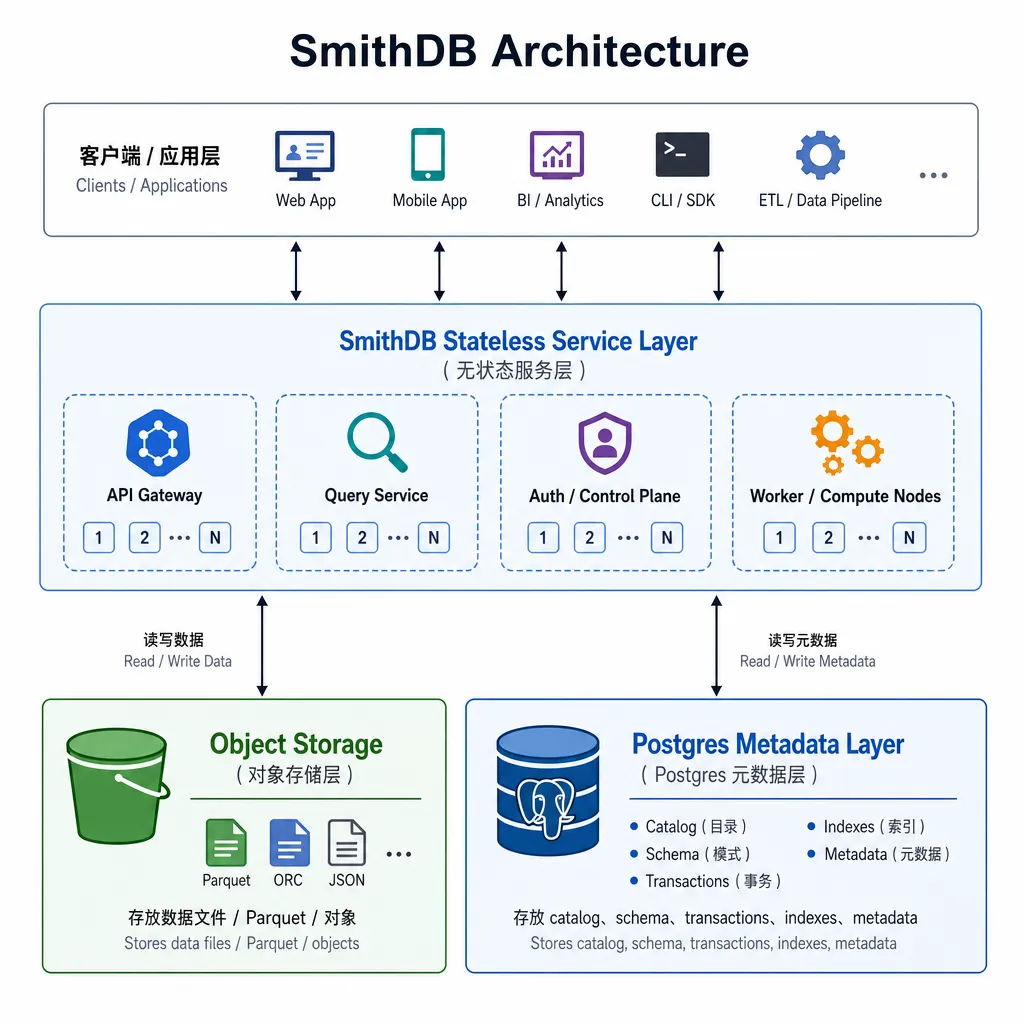
SmithDB 的技术选型
SmithDB 的技术栈很有意思,体现了对性能和可扩展性的极致追求:
Rust + Apache DataFusion + Vortex
核心用 Rust 写,这是性能敏感型基础设施的标配选择。Rust 的零成本抽象和内存安全特性,让 SmithDB 能在保证高性能的同时避免内存泄漏和并发问题。
Apache DataFusion 是一个用 Rust 写的查询引擎,专门用于构建高性能的分析型数据库。它提供了 SQL 查询优化、向量化执行、并行处理等能力。选择 DataFusion 而不是从零实现查询引擎,让 LangChain 能快速构建出生产级的数据库,同时享受 Apache 社区的持续优化。
Vortex 是一个列式存储格式,专门为分析型工作负载优化。Agent traces 的查询模式很适合列式存储:你经常需要扫描大量记录的某几个字段(比如所有 traces 的执行时间、错误信息),而不是读取单条记录的所有字段。列式存储能大幅减少 I/O,提升查询速度。
分层架构:对象存储 + 元数据 + 无状态服务
SmithDB 的架构设计很聪明:
- 对象存储层:真正的 trace 数据(包括多模态内容)存在对象存储里,比如 S3、GCS 或 MinIO。对象存储便宜、可靠、无限扩展,非常适合存储大量非结构化数据
- Postgres 元数据层:只存储轻量级的元数据,比如 trace ID、时间戳、索引信息。Postgres 处理这些小数据游刃有余,而且提供了事务保证
- 无状态服务层:查询服务本身是无状态的,可以水平扩展。需要更多查询能力?加机器就行,不需要复杂的分片或主从配置
这种架构的好处是弹性扩展和成本优化。存储和计算分离,你可以根据实际负载独立扩展。而且因为服务层无状态,可以很容易地部署在 Kubernetes 这类容器编排平台上,实现自动伸缩。
对于想要自托管的企业,这个架构也很友好。你只需要准备对象存储(可以用 MinIO 这类开源方案)和一个 Postgres 实例,就能跑起来。
性能数据:12 倍提升不是吹的
LangChain 给出的性能数据很有说服力:
- 加载 trace tree 的 P50 延迟:92ms。这意味着一半的查询能在不到 100 毫秒内返回完整的调用链路,这对于交互式调试来说已经足够快了
- 全文搜索延迟:400ms。在海量 trace 数据中搜索特定文本,400 毫秒的响应时间已经接近实时体验
- 相比之前的 LangSmith,最高 12 倍的性能提升
这个 12 倍的提升是怎么来的?主要是几个方面的优化:
- 列式存储 + 向量化查询:扫描大量数据时,列式存储能减少 I/O,向量化执行能充分利用 CPU 的 SIMD 指令
- 专门的索引结构:针对 trace 数据的查询模式(按时间范围、按 Agent ID、按错误类型等)设计的索引,比通用数据库的 B-tree 索引更高效
- 多模态内容的分离存储:大的 blob 数据不再拖累查询性能
- Rust 的零成本抽象:相比 Python 或 Java 写的数据库,Rust 实现的查询引擎能减少很多运行时开销
对于 LangSmith 的用户来说,这意味着更流畅的调试体验。你可以快速定位问题 trace、搜索特定的错误信息、分析 Agent 的行为模式,而不用等待漫长的查询时间。
Context Hub:Agent 记忆的中央仓库
除了 SmithDB,LangChain 还宣布了 Context Hub——一个集中管理 Agent 上下文的系统。
什么是 Agent 上下文?
Agent 要想表现得智能,需要记住很多东西:
- AGENTS.md 文件:描述 Agent 的能力、使用方式、限制条件的文档
- 技能(Skills):Agent 学会的可复用能力,比如"如何解析 PDF"、"如何调用某个 API"
- 策略(Policies):Agent 应该遵守的规则,比如"不要泄露用户隐私"、"遇到不确定的情况要询问用户"
- 记忆(Memory):Agent 在交互过程中积累的信息,包括:
- 情景记忆(Episodic Memory):具体的交互历史,比如"用户上次问了什么"
- 语义记忆(Semantic Memory):抽象的知识,比如"用户偏好用 Python 而不是 JavaScript"
- 程序记忆(Procedural Memory):如何执行任务的知识,比如"处理这类问题的标准流程是什么"
这些上下文信息散落在各处——有的在代码里,有的在配置文件里,有的在向量数据库里,有的在关系型数据库里。管理起来很混乱,版本控制也是个问题。
Context Hub 的价值
Context Hub 提供了一个统一的界面来管理所有这些上下文信息。更重要的是,LangChain 正在和 MongoDB、Pinecone、Elastic、Redis 这些主流数据存储厂商合作,制定一个开放标准。
这个标准会定义:
- 不同类型记忆的数据模型(情景、语义、程序)
- 记忆的版本控制机制
- 记忆的检索和更新接口
如果这个标准能推广开,意味着你可以:
- 在不同的存储后端之间迁移:今天用 Pinecone,明天想换成 Elastic?不用重写代码
- 混合使用多个存储:情景记忆用 Redis(快速读写),语义记忆用 Pinecone(向量搜索),程序记忆用 MongoDB(灵活的文档存储)
- 版本控制和回滚:Agent 的记忆也可以像代码一样做版本管理,出问题了可以回滚到之前的状态
这对于企业级 Agent 应用来说很关键。你不希望 Agent 的记忆是个黑盒,也不希望被某个特定的存储方案锁定。
对 Agent 开发者意味着什么?
SmithDB 和 Context Hub 的发布,反映了 Agent 应用正在从实验阶段走向生产阶段。
可观测性成为刚需
当你的 Agent 只是个 demo,出了问题大不了重启。但当 Agent 开始处理真实业务,可观测性就成了生死攸关的问题:
- 调试:Agent 为什么做出这个决策?哪一步出错了?
- 性能优化:哪个工具调用最慢?能不能并行化?
- 成本控制:这个 Agent 调用了多少次 LLM?花了多少钱?
- 合规审计:Agent 访问了哪些数据?有没有违反策略?
SmithDB 提供的高性能 trace 存储和查询能力,让这些问题变得可解。你可以实时监控 Agent 的行为,快速定位问题,持续优化性能。
记忆管理的标准化
Agent 的记忆管理一直是个混乱的领域。每个框架、每个项目都有自己的实现方式,没有统一的最佳实践。
Context Hub 和正在制定的开放标准,有可能改变这个局面。如果主流的存储厂商都支持这个标准,Agent 开发者就不用再为"用什么存储记忆"、"怎么设计记忆的数据结构"这些问题纠结了。
这类似于当年 OpenAI 的 API 格式成为事实标准,让不同的 LLM 提供商可以互相替换。记忆管理的标准化,会让 Agent 的开发和部署变得更简单、更可靠。
自托管的可能性
SmithDB 的架构设计考虑了自托管场景。对于有数据隐私要求的企业(金融、医疗、政府等),能够在自己的基础设施上运行完整的 Agent 可观测性栈,是采用 Agent 技术的前提条件。
LangChain 提供的不是一个只能用云服务的黑盒,而是一套可以自己部署的开放架构。这降低了企业采用的门槛。
竞争格局:LangChain 的护城河
Agent 框架的竞争很激烈。除了 LangChain,还有 LlamaIndex、Semantic Kernel、AutoGPT、CrewAI 等一堆选择。LangChain 的优势在哪?
生态完整性
LangChain 不只是一个框架,而是一个完整的生态:
- LangChain 框架:构建 Agent 的工具库
- LangSmith:可观测性和评估平台
- LangGraph:复杂 Agent 工作流的编排工具
- LangServe:Agent 的部署和服务化
现在加上 SmithDB 和 Context Hub,LangChain 覆盖了从开发、测试、部署到运维的完整生命周期。这种端到端的能力,是其他框架很难短期内复制的。
企业级能力
SmithDB 的性能优化、自托管支持、开放标准的推动,都体现了 LangChain 对企业市场的重视。
很多 Agent 框架是为了研究或个人项目设计的,缺乏生产环境需要的可靠性、可扩展性、安全性。LangChain 在这些方面的投入,让它更适合企业级应用。
开放 vs 封闭
LangChain 的策略是开放的。框架本身开源,SmithDB 可以自托管,Context Hub 推动开放标准。这和某些厂商的封闭生态形成对比。
开放策略的好处是降低用户的锁定风险,吸引更多开发者和企业采用。但挑战是如何在开放的同时保持商业化能力。LangChain 的答案似乎是:提供托管服务(LangSmith 云版)和企业支持来变现,而不是靠技术锁定。
技术细节:值得关注的点
DataFusion 的查询优化
Apache DataFusion 提供了强大的查询优化能力,包括:
- 谓词下推(Predicate Pushdown):把过滤条件尽可能推到数据源层面,减少需要处理的数据量
- 投影下推(Projection Pushdown):只读取需要的列,而不是读取整行数据
- 并行执行:自动把查询分解成可以并行执行的子任务
这些优化对于 trace 查询场景很有用。比如你想找"过去一小时内所有执行时间超过 5 秒的 traces",DataFusion 可以:
- 先根据时间范围过滤(谓词下推)
- 只读取时间戳和执行时间这两列(投影下推)
- 并行扫描多个数据分区
最终只需要处理很小一部分数据,查询速度自然快。
Vortex 的压缩和编码
Vortex 作为列式存储格式,使用了多种压缩和编码技术:
- 字典编码(Dictionary Encoding):对于重复值多的列(比如 Agent ID、工具名称),用整数索引代替原始字符串
- 游程编码(Run-Length Encoding):对于连续重复的值,只存储值和重复次数
- 位打包(Bit Packing):对于取值范围小的整数,用更少的位数存储
这些技术能大幅减少存储空间,同时提升查询速度(因为需要读取的数据量更少)。
对象存储的分层
对象存储虽然便宜,但访问延迟比本地磁盘高。SmithDB 可能使用了分层存储策略:
- 热数据:最近的 traces 存在高性能的对象存储层(比如 S3 Standard)
- 温数据:几天前的 traces 转移到低成本的存储层(比如 S3 Infrequent Access)
- 冷数据:很久以前的 traces 归档到最便宜的存储层(比如 S3 Glacier)
这样既能保证常用数据的访问速度,又能控制存储成本。
未来展望
实时分析
目前 SmithDB 主要用于事后分析——Agent 执行完了,你去查看 trace。未来可能会支持实时分析:
- 实时监控:Agent 正在执行时,就能看到当前的状态和性能指标
- 实时告警:检测到异常(比如执行时间过长、错误率飙升)立即通知
- 实时干预:发现 Agent 行为不对,可以暂停或修正
这需要 SmithDB 支持流式数据处理,可能会集成 Apache Flink 或 Kafka Streams 这类流处理引擎。
AI 驱动的分析
有了大量的 trace 数据,可以用 AI 来做更智能的分析:
- 异常检测:自动发现不正常的 Agent 行为
- 性能优化建议:分析 trace 数据,给出优化建议(比如"这两个工具调用可以并行")
- 根因分析:Agent 出错时,自动定位根本原因
这些功能可以大幅降低 Agent 运维的人力成本。
跨 Agent 的协作分析
现在的 trace 主要是单个 Agent 的执行过程。未来可能需要分析多个 Agent 的协作:
- Agent 之间的调用关系:Agent A 调用了 Agent B,B 又调用了 C
- 协作性能分析:整个协作链路的瓶颈在哪?
- 协作模式挖掘:哪些 Agent 组合效果最好?
SmithDB 的分布式架构为这种跨 Agent 分析提供了基础。
结语
SmithDB 的发布标志着 Agent 基础设施进入了一个新阶段。从"能跑起来"到"跑得好、看得清、管得住",这是 Agent 技术走向成熟的必经之路。
LangChain 在可观测性和记忆管理上的投入,体现了对企业级 Agent 应用的深刻理解。这不是炫技,而是解决真实痛点。
对于开发者来说,现在是个好时机。基础设施越来越完善,开发 Agent 应用的门槛在降低,但市场还远未饱和。抓住这个窗口期,用好 SmithDB 这类工具,可能会有不错的机会。
当然,工具只是工具。真正决定 Agent 应用成败的,还是对业务场景的理解、对用户需求的把握、对技术边界的认知。SmithDB 能让你看清 Agent 在做什么,但做什么、为什么做,还是要靠你自己想清楚。
参考来源
- LangChain Interrupt 2026 announcements - Reddit - LangChain Interrupt 2026 大会第一天的官方公告,包含 SmithDB 和 Context Hub 的详细信息
- LangChain GitHub - LangChain 开源框架的代码仓库
