Orthrus:冻结主干+扩散注意力,推理提速7.8倍
越南研究团队刚发了篇论文,提出一个叫 Orthrus 的新架构,核心思路是在冻结的自回归 Transformer 里塞进一个可训练的扩散注意力模块,让模型能并行生成 32 个 token,推理速度直接拉到 7.8 倍,精度还跟基座模型完全一样。这个方案最大的亮点是训练成本极低——只训练 16% 的参数,用不到 10 亿 token,8 张 H100 跑 24 小时就能搞定。
扩散注意力怎么塞进 Transformer
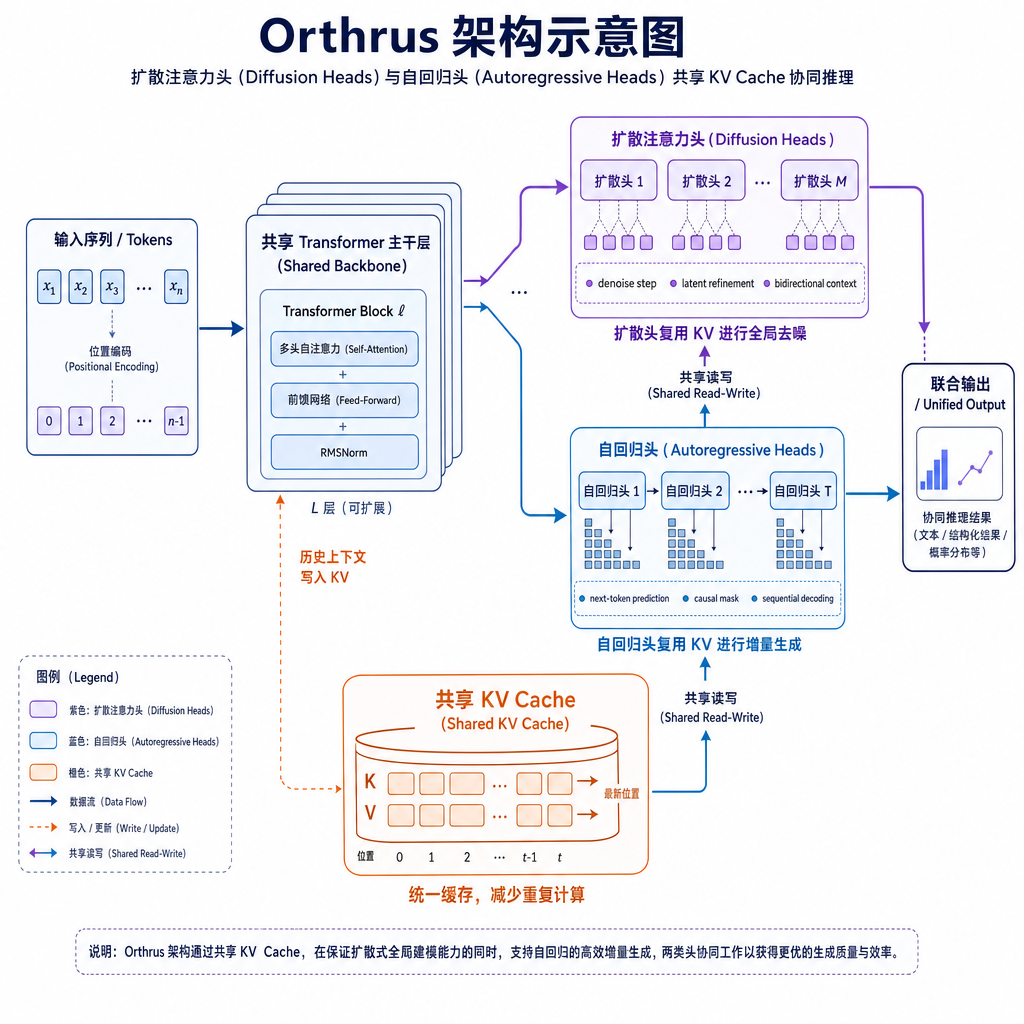
Orthrus 的设计很直接:在每一层 Transformer 里插入一个扩散注意力头(Diffusion Head),跟原来的自回归头(AR Head)共享同一个 KV Cache。扩散头负责并行预测接下来的 K=32 个 token,AR 头再做第二遍验证,接受最长的匹配前缀。整个过程的输出分布在数学上可证明跟基座模型完全一致。
这个设计的关键在于"双视角"(Dual-View):扩散头用的是去噪扩散概率模型(DDPM)的思路,把 token 生成看作从噪声到清晰文本的逐步去噪过程;AR 头还是经典的自回归生成,一个 token 接一个 token 往后推。两个头共享 KV Cache,意味着内存开销是 O(1) 的——实测只增加约 4.5 MiB,跟传统的投机解码(Speculative Decoding)需要维护两套独立缓存完全不是一个量级。
跟现有方案比,优势在哪
对比扩散语言模型
市面上已经有不少扩散语言模型的尝试,比如 Dream、Fast-dLLM-v2、SDAR、Mercury、Gemini Diffusion。这些方案的共同问题是需要修改基座模型的权重,导致精度下降——Fast-dLLM-v2 在 MATH-500 数据集上直接掉了 11 个点。
Orthrus 的做法是冻结基座模型的所有权重,只训练新增的扩散注意力模块。这样做的好处是精度完全不受影响,在 MATH-500 上的表现跟 Qwen3-8B 基座模型一模一样。而且因为只训练 16% 的参数,训练成本极低——用不到 10 亿 token,8 张 H200 跑 24 小时就能收敛。
对比投机解码
投机解码(Speculative Decoding)是另一个主流的加速方案,代表性工作包括 EAGLE-3 和 DFlash。这类方法的核心是用一个小的 drafter 模型先生成候选 token,再用大模型验证。问题在于:
- 需要额外的 drafter 模型:要么从头训练一个小模型,要么用现成的小模型,但无论哪种都需要维护两套模型。
- KV Cache 开销翻倍:drafter 和 verifier 各需要一套 KV Cache,内存占用直接翻倍。
- TTFT(Time-To-First-Token)有惩罚:因为需要先初始化 drafter 模型并同步状态,第一个 token 的生成时间会变长。
Orthrus 没有这些问题。它不需要外部 drafter,扩散头和 AR 头共享同一个 KV Cache,KV 开销是 O(1) 的常数级别。而且因为扩散头是直接嵌入在主模型里的,不存在 TTFT 惩罚——第一个 token 的生成时间跟基座模型完全一样。
实测数据:速度和精度都在线
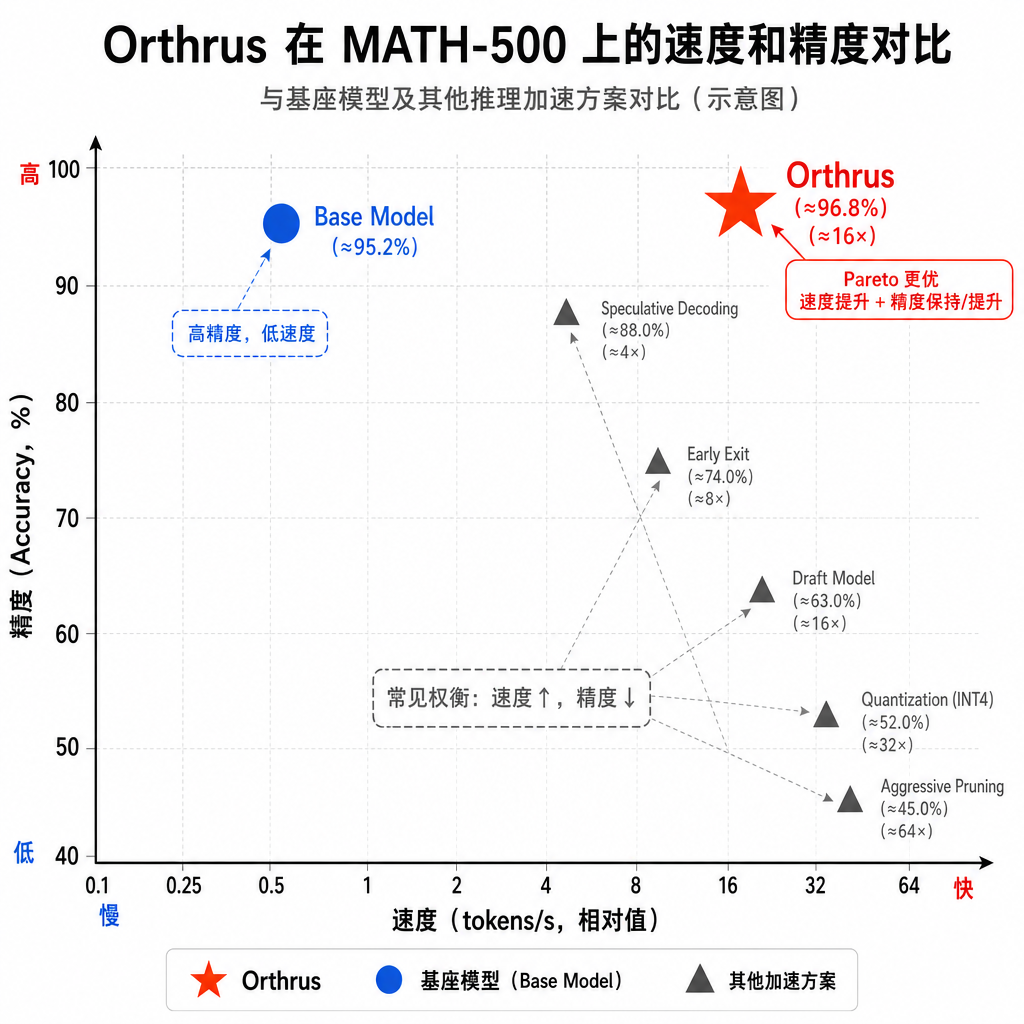
论文在 MATH-500 数据集上做了详细测试,基座模型是 Qwen3-8B。结果很亮眼:
- TPF(Tokens Per Forward)提升 7.8 倍:传统自回归生成每次前向传播只能生成 1 个 token,Orthrus 能并行生成 32 个 token,实际接受率让 TPF 达到 7.8。
- 端到端速度提升约 6 倍:考虑到验证开销和接受率,实际墙上时钟时间(wall-clock time)提升约 6 倍。
- 精度完全一致:在 MATH-500 上的准确率跟 Qwen3-8B 基座模型完全相同,没有任何精度损失。
接受率(Acceptance Rate)是衡量并行生成效果的关键指标。Orthrus 的接受率在不同任务上有所差异,但平均能达到 24%(即 32 个候选 token 中平均接受 7-8 个)。这个数字看起来不高,但考虑到扩散头只用了 16% 的参数量,而且训练数据不到 10 亿 token,已经相当不错了。
训练成本:24 小时 8 卡 H200
训练成本是 Orthrus 最大的卖点之一。整个训练过程只需要:
- 参数量:只训练 16% 的参数(扩散注意力模块),基座模型的权重完全冻结。
- 数据量:不到 10 亿 token,远低于从头训练一个语言模型的数据需求。
- 算力:8 张 H200 GPU,训练 24 小时。
这个成本对于大部分研究团队和公司来说都是可以接受的。相比之下,从头训练一个 8B 参数的语言模型通常需要几千张 GPU 跑几周甚至几个月,数据量也要几万亿 token 起步。
训练过程的核心是让扩散头学会预测接下来的 K 个 token。具体来说,训练目标是最小化扩散头预测的 token 序列与真实 token 序列之间的交叉熵损失。因为基座模型的权重是冻结的,扩散头需要学会"适应"基座模型的表示空间,而不是反过来让基座模型适应扩散头。
技术细节:双视角扩散的数学保证
Orthrus 的理论基础是"双视角扩散"(Dual-View Diffusion)。这个概念的核心是证明扩散头和 AR 头的联合输出分布与基座模型的输出分布在数学上是等价的。
具体来说,扩散头生成的 K 个候选 token 可以看作是从一个条件分布 p(x_{t+1:t+K} | x_{1:t}) 中采样得到的。AR 头的验证过程则是计算每个候选 token 在基座模型下的条件概率 p(x_{t+i} | x_{1:t+i-1}),并接受最长的匹配前缀。
论文证明了,当扩散头的训练目标是最小化与基座模型输出分布的 KL 散度时,最终的联合输出分布 p(x_{t+1:t+K} | x_{1:t}) 会收敛到基座模型的真实分布。这个证明保证了 Orthrus 不会改变模型的生成行为,精度损失为零。
这个数学保证是 Orthrus 相比其他扩散语言模型的核心优势。很多扩散语言模型在训练时会修改基座模型的权重,导致输出分布发生偏移,精度下降。Orthrus 通过冻结基座模型并只训练扩散头,从根本上避免了这个问题。
KV Cache 开销:O(1) 的常数级别
KV Cache 是 Transformer 推理的内存瓶颈。传统的自回归生成需要为每个 token 存储 Key 和 Value 向量,内存占用随序列长度线性增长。投机解码因为需要维护两套模型(drafter 和 verifier),KV Cache 开销直接翻倍。
Orthrus 的设计巧妙地避免了这个问题。扩散头和 AR 头共享同一个 KV Cache,意味着无论并行生成多少个 token,KV Cache 的大小都不会增加。实测显示,Orthrus 相比基座模型只增加了约 4.5 MiB 的固定开销,这个开销是 O(1) 的常数级别,跟序列长度和并行生成的 token 数量无关。
这个设计的关键在于扩散头和 AR 头的协同工作方式。扩散头在生成候选 token 时,使用的是当前时刻的 KV Cache;AR 头在验证时,会逐步更新 KV Cache,但更新的是同一个缓存。这样一来,整个推理过程只需要维护一套 KV Cache,内存开销最小化。
适用场景:长文本生成和推理任务
Orthrus 的加速效果在不同任务上有所差异。论文主要在 MATH-500 数据集上做了测试,这是一个数学推理任务,需要模型生成较长的推理步骤。在这类任务上,Orthrus 的加速效果最明显,TPF 能达到 7.8 倍。
对于其他类型的任务,加速效果可能会有所不同:
- 长文本生成(如文章写作、代码生成):因为生成的 token 数量多,并行生成的优势能充分发挥,预计加速效果接近 MATH-500 的水平。
- 短文本生成(如对话、问答):因为生成的 token 数量少,并行生成的优势不明显,加速效果可能会打折扣。
- 高度随机的生成任务(如创意写作):因为候选 token 的接受率可能较低,加速效果也会受影响。
总的来说,Orthrus 更适合需要生成较长序列、且生成过程相对确定性较高的任务。对于这类任务,Orthrus 能在不损失精度的前提下显著提升推理速度。
开源代码和复现
论文作者已经在 GitHub 上开源了 Orthrus 的实现代码,仓库地址是 https://github.com/chiennv2000/orthrus。代码基于 PyTorch 实现,支持 Hugging Face Transformers 库,可以直接加载预训练的 Transformer 模型并注入扩散注意力模块。
仓库里包含了完整的训练和推理脚本,以及在 MATH-500 数据集上的复现结果。如果你想在自己的模型上尝试 Orthrus,可以参考仓库里的示例代码,主要步骤包括:
- 加载预训练的 Transformer 模型(如 Qwen3-8B)。
- 在每一层插入扩散注意力模块。
- 冻结基座模型的权重,只训练扩散注意力模块。
- 在目标任务的数据集上微调。
- 推理时使用双视角生成:扩散头并行生成候选 token,AR 头验证并接受最长前缀。
作者在 README 里提到,训练过程对超参数不太敏感,默认配置在大部分任务上都能取得不错的效果。如果你的任务跟 MATH-500 差异较大,可能需要调整一下学习率和训练步数。
未来方向:更大的 K 和更高的接受率
论文里用的并行生成数量 K=32,这个数字是在速度和接受率之间权衡的结果。K 越大,理论上能并行生成的 token 越多,但接受率可能会下降,因为扩散头预测的准确性会随着预测长度的增加而降低。
未来的改进方向可能包括:
- 动态调整 K:根据当前生成的确定性动态调整并行生成的数量。对于高确定性的生成(如代码补全),可以用更大的 K;对于低确定性的生成(如创意写作),可以用更小的 K。
- 提升接受率:通过更好的训练策略或更大的扩散头参数量,提升候选 token 的接受率。目前 24% 的接受率还有很大提升空间。
- 多层级并行生成:在不同的 Transformer 层使用不同的并行生成策略,浅层用小 K,深层用大 K,进一步优化速度和精度的平衡。
- 扩展到更大的模型:论文目前只在 8B 参数的模型上做了测试,未来可以尝试在更大的模型(如 70B、405B)上验证效果。
对行业的影响
Orthrus 的出现对 LLM 推理加速领域是个不小的冲击。它证明了一个重要的观点:不需要修改基座模型的权重,也不需要额外的 drafter 模型,就能实现显著的推理加速。
这个思路对于已经部署了大规模 LLM 服务的公司来说特别有吸引力。因为基座模型的权重是冻结的,可以直接在现有的模型上叠加 Orthrus,不需要重新训练或微调整个模型。而且训练成本极低,24 小时 8 卡 H200 就能搞定,对于大部分公司来说都是可以接受的。
另一个值得关注的点是 Orthrus 的内存效率。KV Cache 是 LLM 推理的主要内存瓶颈,尤其是在长上下文场景下。Orthrus 的 O(1) KV 开销意味着它在长上下文推理上有天然优势,不会因为并行生成而增加内存压力。
当然,Orthrus 也不是银弹。它的加速效果依赖于接受率,而接受率又跟任务的确定性高度相关。对于高度随机的生成任务,Orthrus 的优势可能不明显。但对于推理、代码生成、长文本写作这类确定性较高的任务,Orthrus 已经展现出了很强的竞争力。
参考来源
- Orthrus 论文 - arXiv 预印本,详细介绍了双视角扩散的理论基础和实验结果
- Orthrus GitHub 仓库 - 开源代码和复现脚本
- Reddit 讨论 - 作者在 r/MachineLearning 发起的讨论帖