蚂蚁开源万亿级思考模型 Ring-2.6-1T:把"思考多深"变成一个可调旋钮
5 月 15 日,蚂蚁集团旗下百灵大模型团队(inclusionAI)正式把 Ring-2.6-1T 推上了 Hugging Face 和 ModelScope。这是一个万亿参数级别的思考模型,从 5 月 9 日先在 OpenRouter 上线限时免费体验,到昨天正式开源权重,前后只隔了一周。
比参数规模更值得说的,是它的设计思路:Ring-2.6-1T 把"模型该思考多深"做成了一个可调旋钮,提供 high 和 xhigh 两档推理强度,开发者按任务难度自己选。这不是把 reasoning 当作一个开关那么简单,背后涉及的是对真实生产场景中"思考成本"的重新理解。
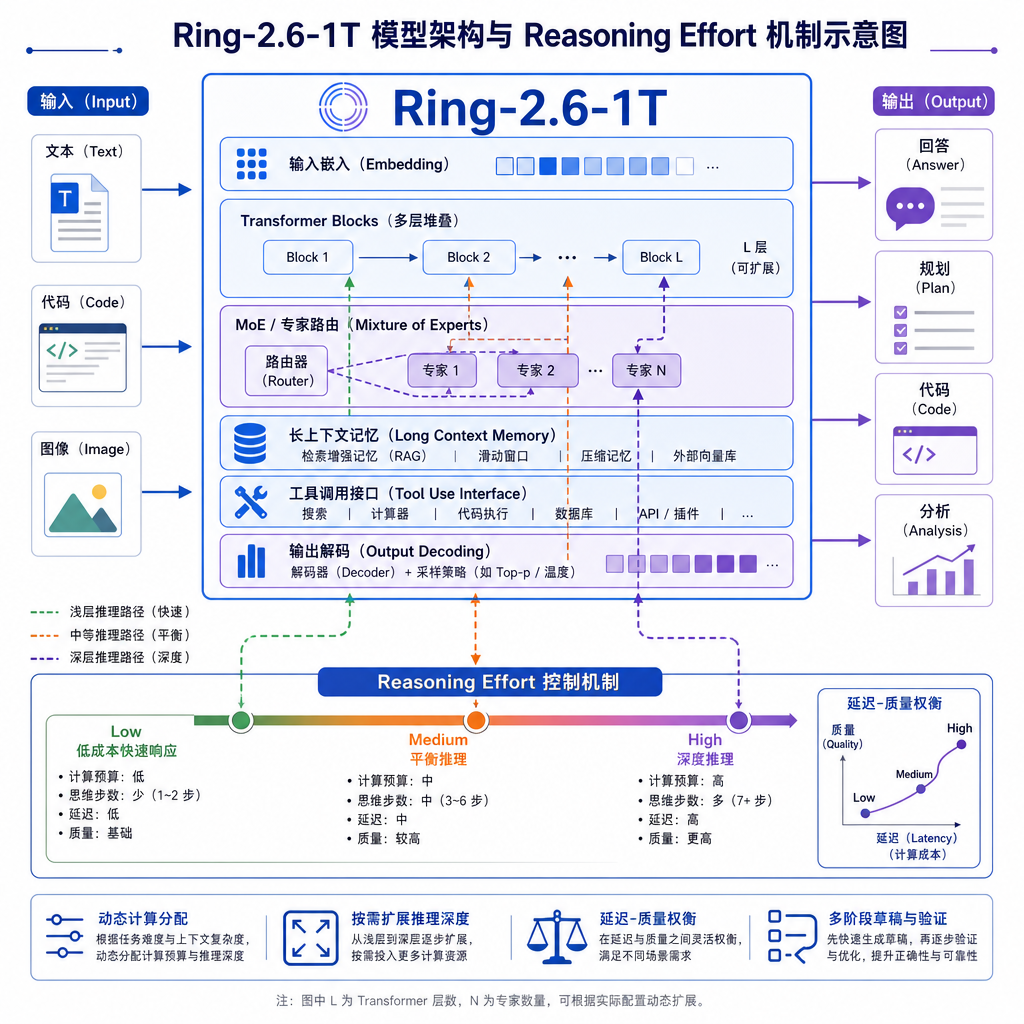
不是一个新模型,是一种新做法
过去一年,思考模型(reasoning model)几乎成了头部厂商的标配。OpenAI 的 o 系列、Anthropic 的 extended thinking、Google 的 Gemini Thinking、DeepSeek-R1,路子都是让模型先"想一会儿"再答。但这个范式有个共同的痛点:思考是有代价的。
一次复杂推理可能产生上万 token 的思维链,对应的是真金白银的延迟和费用。在 Agent 场景下问题更严重,一个任务可能要调几十次模型,每次都让它"深度思考",整个工作流就会被拖垮。开发者要么忍受高成本和高延迟,要么干脆不用思考模型——这是个不该出现的二选一。
Ring-2.6-1T 的解法是把思考强度参数化。官方给的定位很清楚:
- high 档:面向高频 Agent 工作流,token 开销低、多步执行更快,适合多轮交互、工具协作、任务拆解,是"生产级默认值"。
- xhigh 档:面向数学证明、科研分析、复杂逻辑、多路径搜索这类高难度任务,给模型留出更充分的思考空间。
这种分档思路其实和 OpenAI 的 reasoning_effort 参数(low/medium/high)是同一脉络,但 Ring-2.6-1T 把档位定位做得更具体——high 不是"中等思考",而是明确为 Agent 工作流优化过的低开销模式。这是个有意思的产品判断:在真实的开发场景里,多数调用其实不需要顶配思考,需要的是稳定且廉价的多步执行能力。
跑分:xhigh 进了头部梯队,high 在 Agent 场景上有惊喜
光说设计还不够,得看数据。蚂蚁这次披露的评测覆盖了真实任务执行和高难推理两条线。
xhigh 档(高难推理):
| 评测集 | 得分 | 备注 |
|---|---|---|
| ARC-AGI-V2 | 77.78 | 抽象推理基准 |
| AIME 26 | 95.83 | 数学奥赛级 |
| GPQA Diamond | 88.27 | 研究生级科学问答 |
AIME 26 接近 96 分、GPQA Diamond 88 分,这个水平已经能和 GPT-5、Claude Opus 4.7、Gemini 3.1 Pro 这一档掰掰手腕。ARC-AGI-V2 上 77.78 也是个相当扎实的成绩——这套基准是专门用来卡"模型不会真正抽象推理"软肋的。
high 档(Agent 与真实任务执行):
| 评测集 | 得分 | 对比 |
|---|---|---|
| PinchBench | 87.60 | 高于 GPT-5.4 xHigh、Gemini-3.1-Pro high、Claude-Opus-4.7 xhigh |
| ClawEval | 63.82 | 复杂业务流程评估 |
| Tau2-Bench Telecom | 95.32 | 工具协作与多轮交互 |
注意 PinchBench 这一行:Ring-2.6-1T 的 high 档,超过了几个竞品的 xhigh/最高档。Tau2-Bench Telecom 95.32 也是个很硬的数字,这个基准模拟的是电信客服场景下的多轮工具调用,对模型的指令跟随、状态保持、工具使用稳定性都是综合考验。
这组数据说明一件事:在 Agent 这种"思考不需要太深,但执行要足够稳"的场景里,Ring-2.6-1T 的 high 档把成本压下来的同时没有牺牲能力。这是它最有商用价值的那一面。
万亿参数怎么落地:MoE 是隐含的前提
虽然官方没在通稿里大谈架构,但"万亿级"这个词在今天的语境下基本意味着 MoE(混合专家)。Ring 系列此前的版本就是 MoE 路线,1T 总参数量配合稀疏激活,推理时实际激活的参数量远小于总量,这是它在 high 档能做到"低 token 开销 + 快多步执行"的工程基础。
这里有一个对比值得留意:DeepSeek-V3/R1 是 671B 总参、37B 激活;Kimi K2 是 1T 总参;Qwen3-Max 也在万亿区间。Ring-2.6-1T 进的是这个量级的牌桌,但它的差异化点不在参数堆叠,而在 Reasoning Effort 这层产品化抽象——把模型能力和工程开销解耦给开发者控制。
对企业部署来说,开源万亿模型的现实门槛不算低,单机肯定跑不起来,需要多卡甚至多机推理。但开源的意义本来就不只是"自己部署",更是允许研究者拆开看、做蒸馏、做对齐、做领域微调。Hugging Face 和 ModelScope 双平台同步放权重,国内外开发者都能直接拉。
调用方式:先在 OpenRouter,再开源
蚂蚁这次的发布节奏挺克制:5 月 9 日上线 OpenRouter 给一周免费试用,让开发者先用起来;5 月 15 日开源权重,把后续的部署、微调、二次开发交给社区。这个顺序比直接砸权重要更聪明——先让 high/xhigh 这两档的差异在真实流量里被验证过。
对于想直接调 API 的开发者,OpenRouter 上的接口已经支持通过 reasoning_effort 参数选择档位。如果是开源部署,vLLM、SGLang 这类推理框架对 MoE 的支持已经比较成熟,主要工程量在多机张量并行的配置上。
值得一提的是,OpenAI Hub 这类聚合平台目前已经在跟进国产开源模型的接入,对于不想自己折腾百卡集群、又想在统一接口下对比 GPT、Claude、Gemini 和 Ring-2.6-1T 这类国产模型的开发者,是条更省事的路径。
这个开源放在当下意味着什么
2026 年开年到现在,国内开源大模型的节奏明显在加速。从 DeepSeek 系列到 Qwen3,再到现在蚂蚁的 Ring-2.6-1T,万亿级、思考型、可工程化部署的开源模型已经不是稀缺品。但每一家的差异化点不一样:DeepSeek 主打极致性价比,Qwen 主打多模态全栈,Ring 这次主打的是 "思考强度可调" 这个工程语义。
这背后其实反映了行业对 reasoning model 的态度变化。一年前,大家在拼"思考链能不能更长更深";现在拼的是"思考能不能按需付费"。蚂蚁把这一层做成了显式的 API 参数和模型档位,是个比较务实的产品决策。
几个值得关注的点:
- PinchBench 上 high 超过竞品 xhigh——如果这个结果在第三方复测中能稳住,那 Ring-2.6-1T 在 Agent 工作流上的性价比会非常突出。
- xhigh 在 ARC-AGI-V2 上 77.78——这个分数说明它的高难推理不是只能做"标准题型",对真正需要抽象的任务也能扛。
- 开源 + OpenRouter 双轨——蚂蚁明显想同时拿到"开发者社区影响力"和"商业部署落地"两块,这个打法和 Mistral 早期路线相似。
一个具体的小判断
如果你正在做 Agent 类产品、需要一个稳定的多步执行模型,Ring-2.6-1T 的 high 档值得严肃测一测——尤其是 Tau2-Bench Telecom 95.32 这个数字,对真实业务场景里的工具调用稳定性是个强信号。如果你做的是科研、数学、复杂代码生成,xhigh 档可以放进 GPT-5、Claude Opus 4.7 的 A/B 对比里。
但如果你只是想跑个 chatbot,万亿模型大概率是过度设计——这一点蚂蚁自己也清楚,所以才把 high 档定位成"生产级默认",让大模型能力下沉到日常调用,而不是只服务于刁钻 benchmark。
开源权重已经放出,剩下的就看社区怎么玩了。
参考来源
- IT之家:蚂蚁集团百灵开源万亿级思考模型 Ring-2.6-1T,支持 high 与 xhigh 两种推理强度 — 开源公告与官方说明
- Hugging Face:inclusionAI/Ring-2.6-1T — 模型权重与卡片信息