一个被「Key 池」逼出来的开源工具
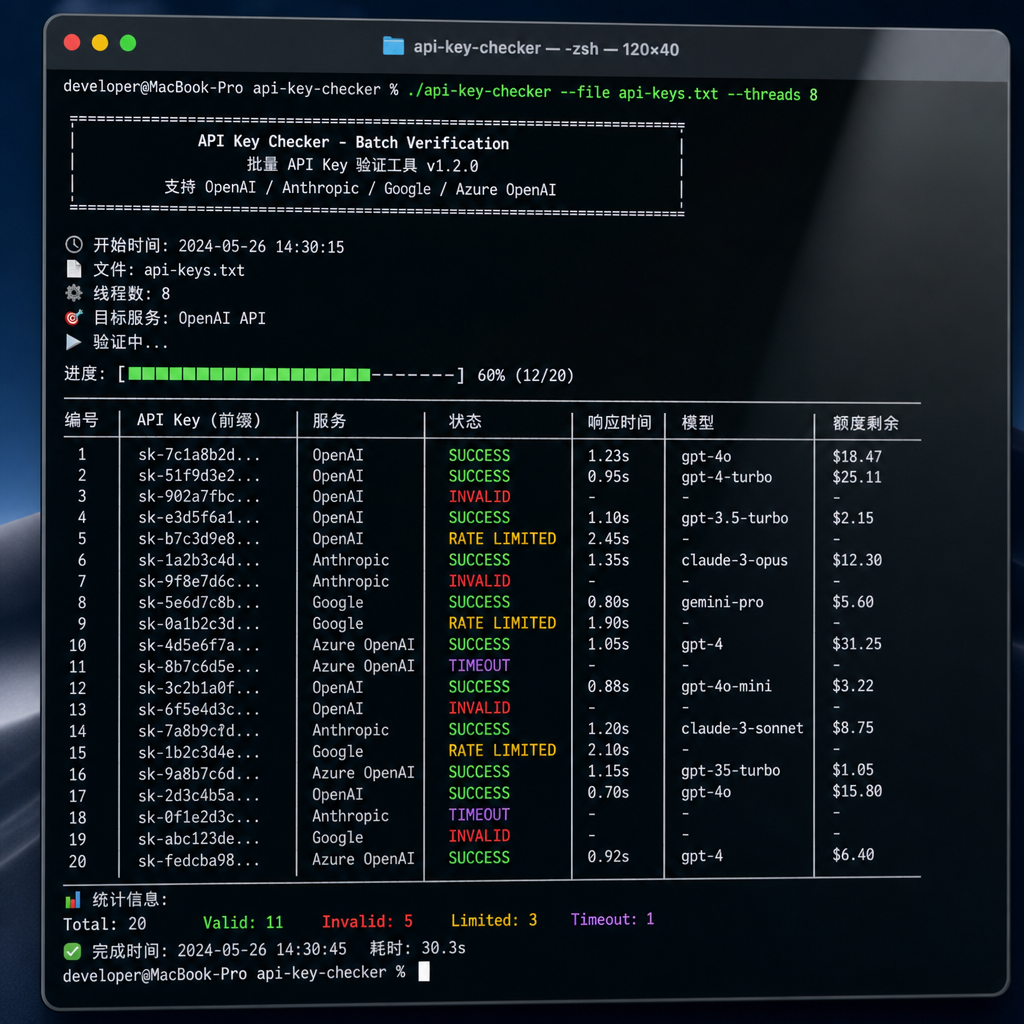
5 月中旬,一个叫 api-key-checker 的小工具悄悄在 Linux.do 上火了起来。作者 purainity 在帖子里没绕弯子,直接说出了大多数 AI 重度用户的真实处境:手里攒了几十上百个来路各异的 API Key,有的是注册赠金、有的是别人分享、有的是从 GitHub 上扫来的「打野」战利品,但没有一个统一的办法搞清楚——这些 Key 现在到底还能不能用,余额还剩多少,能调哪些模型。
这个项目目前覆盖四个主流平台:OpenRouter、SiliconFlow(硅基流动)、DeepSeek 三家做余额查询,Gemini 则提供基础检测、深度检测和模型方法可用性校验三种模式。代码完全用 AI 写出来的,作者本人在帖子里坦承,这事儿听起来轻松,实际上「写详细而具体的提示词、不断与它交互提要求修改也是非常耗费精力的一件事」——这句吐槽倒是挺真实,做过 Vibe Coding 的人都懂。
为什么这类工具今年突然多起来了
如果只看 api-key-checker 一个项目,可能觉得是个小众玩具。但把视角拉远一点会发现,最近半年类似的工具在 GitHub 上密集冒头:weiruchenai1 的 api-key-tester 做的是 Web 界面的批量测活,覆盖 OpenAI、Claude、Gemini;qixing-jk 的 all-api-hub 干脆做成了浏览器扩展,把 one-api、new-api、Veloera 这些「中转站」的余额、签到、密钥导出、模型验证全部聚合到一个面板里。
这不是巧合。背后的逻辑是 AI API 的供给侧在过去一年发生了几个变化:
- 免费额度成了营销手段:硅基流动、OpenRouter、Gemini 都在不同时期发过大额赠金或免费 Tier,社区里自然就形成了 Key 的流通和分享文化。
- 中转站爆发式增长:one-api、new-api 这类自建网关的普及,让「一个开发者同时持有十几个上游渠道」从极端情况变成了常态。
- 模型路由失败率不低:同一个 Key 在 A 模型上能调通、B 模型直接 404 的情况太常见,尤其是 Gemini 这种被 Google 频繁调政策的家伙。
手动一个一个测,curl 加 jq,敲到第十个就想砸键盘。所以工具自然要长出来。
四个平台分别怎么测
看下 api-key-checker 的具体设计,能感受到作者是真踩过坑的。
OpenRouter / SiliconFlow / DeepSeek 这三家比较省心,因为官方都提供了余额查询接口,脚本直接打 /user 或者 /balance 这类端点,拿回 JSON 解析剩余额度就行。这种检测属于「冷检测」,不消耗 Token,不触发限流,可以放心大胆批量跑。OpenRouter 还能顺带拿到这个 Key 是不是 BYOK、有没有被限速等元信息。
Gemini 那边就麻烦得多。 Google Cloud 的 API Key 设计本身就不是为了「方便检测」服务的——它没有统一的余额接口,因为 Gemini 走的是 GCP 计费体系,配额和项目绑定。所以作者拆出了三档检测:
- 基础检测:调用
models.list这类轻量端点,验证 Key 至少是有效的、没被吊销。 - 深度检测:实际发一次小的
generateContent请求,看是不是真能跑出 token 来——这一步是必要的,因为有不少 Key 通过基础检测但一调模型就报PERMISSION_DENIED,这种 Key 拿到手就是个废号。 - 模型方法可用性检测:分模型分方法去试,比如
gemini-2.5-pro的generateContent能用,但gemini-2.5-pro-vision可能就不行;或者streamGenerateContent被某些项目禁用。这一层在调试 Gemini 应用的时候特别有用。
这种分层设计其实暴露了 Gemini API 的一个老问题:单一 Key 在不同模型、不同方法上的可用性是离散的,不能用「Key 是否有效」这种二元判断来概括。早期社区里流行的「打野」(也就是扫 GitHub 上无意泄露的 AIzaSy 开头的 Key)之所以需要专门的工具,就是因为扫到的 Key 良莠不齐,必须挨个细测才知道值不值得入池。
跟同类工具比,定位有点不一样
把 api-key-checker 和前面提到的几个项目放一起看,会发现各自打的是不同的位置。
| 项目 | 形态 | 主打场景 | 覆盖平台 |
|---|---|---|---|
| api-key-checker | Bash 脚本 | 纯检测、自动化跑批 | OpenRouter / SiliconFlow / DeepSeek / Gemini |
| api-key-tester | Web 应用(可 Docker) | 图形界面、面向多人共享 | OpenAI / Claude / Gemini 等 |
| all-api-hub | 浏览器扩展 | 中转站资产管理、签到、导出 | 所有兼容 New API 标准的站点 |
api-key-checker 的优势在于「轻」——它就是一堆 shell 脚本配合 curl 和 jq,没有前端、没有数据库、没有依赖一堆 npm 包。要塞进 CI 里跑、要写到 cron 里每天扫一遍 Key 池、要和现有 Bash 工具链拼起来用,都很顺手。
劣势也很明显:交互体验跟图形化工具没法比,给非技术用户用基本是劝退。但作者的目标读者本来就是 Linux.do 社区里那帮天天敲终端的人,所以这个取舍没毛病。
# 典型用法(参考 README)
./check_openrouter.sh keys.txt
./check_gemini.sh --mode=deep keys.txt
几行命令就能把一个 Key 列表跑完,结果按可用、失效、限额等状态分类输出。
一些值得注意的细节
用这类工具有几件事得记在脑子里:
第一,批量检测本身是会消耗配额的。尤其是深度检测那一档,每个 Key 都会真实发一次推理请求。如果你扫的是别人分享的免费 Key,这个成本不归你;但如果你检测的是自己付费的 Key,记得把检测频率压低一点,别为了知道余额反而把余额给烧了。
第二,Gemini 的检测结果有时效性。Google 这一年对 Gemini API 的调整非常频繁,免费 Tier 的额度今年初被砍了一大波,地区限制、模型下线、配额政策几乎每个月都在变。今天测出来能用的 Key,明天可能就因为政策变化而失效,所以这类工具更适合做「当前状态快照」,不要把检测结果当成静态资产管理。
第三,法律和道德边界要心里有数。扫 GitHub 上别人无意泄露的 Key 这种事,社区里讨论得很热闹,但严格说来这是别人的资产。工具本身没问题,但怎么用是另一回事。
工具化之后,下一步是什么
从 api-key-checker、api-key-tester 到 all-api-hub,能看出一条清晰的演化路径:从「单点测活」到「批量检测」再到「资产管理面板」,开发者对 AI API 的管理方式正在从 IDE 里敲个 curl 的散兵游勇,变成需要专门工具链的工程化场景。
这背后其实反映了一个更大的趋势——多模型混合调用已经是默认形态。一个稍微像样的 AI 应用,后端往往挂着 GPT-4o 兜底、Claude 处理长文本、Gemini 跑多模态、DeepSeek 或 Qwen 跑成本敏感的任务,再加上一两个开源模型做本地 fallback。每多接一家,账号、Key、计费、限流的复杂度就翻一倍。
这也是为什么聚合型 API 服务在过去一年起来得很快。像 OpenAI Hub 这类平台做的事情,本质上是把上面这套「多 Key 多平台」的复杂度收敛到单一接口里——一个 Key 走通 GPT、Claude、Gemini、DeepSeek,国内直连,统一计费,兼容 OpenAI 格式。对于不想自己维护 Key 池、不想写检测脚本、也不想纠结某家政策又变了的团队来说,这条路省事不少。
但对于喜欢自己折腾、追求成本极致的开发者,api-key-checker 这种小而美的工具仍然有它的位置。开源社区的好处就是这样——你既可以选择把脏活累活外包给聚合平台,也可以选择自己拼一套适合自己工作流的工具链,两条路都走得通。
写在最后
看到这种「作者就是为了挠自己的痒而做」的项目,比看那些大厂正经发布的产品其实更舒服。purainity 在帖子里说得很实在:起初是手动测 Key,后来 Key 多了就让 AI 写脚本,再后来索性把脚本整理成项目开源出去。整个过程没有融资、没有 Roadmap、没有产品经理拍脑袋决定要不要做某个功能——就是一个开发者面对自己工作流里的痛点,顺手把它解决了。
AI 工具生态里这种「微项目」的密度今年明显在变高,好处是社区的供给越来越丰富,坏处是质量和维护周期参差不齐。挑工具的时候建议看几个信号:作者自己用不用、Issue 响应快不快、代码是不是还在更新。这三条比 Star 数靠谱得多。
参考来源
- Linux.do:多 AI 平台 API Key 批量检测脚本介绍帖 - 作者 purainity 关于项目动机和实现细节的原始说明
- GitHub:weiruchenai1/api-key-tester - 同类的 Web 形态批量测活工具,支持 OpenAI、Claude、Gemini
- GitHub:qixing-jk/all-api-hub - 浏览器扩展形态的多中转站聚合管理工具,主打资产看板和密钥导出