英伟达开源 2.6B 世界模型,RTX 5090 上 29 秒生成 1 分钟 720p 视频
英伟达 NVLabs 刚发布了 SANA-WM(SANA World Model),一个 26 亿参数的开源世界模型,专门用于生成分钟级 720p 视频。这个模型最大的亮点是效率:在 RTX 5090 上用 FP4 精度推理,生成 5 秒 720p 视频只需 29 秒,比之前快了 2.4 倍。更关键的是,它的训练成本只有 Meta MovieGen 的 1%。
这不是英伟达第一次在视频生成上做文章。SANA 系列之前已经有了图像生成模型,这次的 SANA-WM 和 SANA-Video 是视频方向的延伸。但跟市面上那些动辄几十亿参数、需要数据中心级算力的模型不同,SANA-WM 的设计目标就是「能在消费级硬件上跑」。
技术架构:Block Linear Attention 是核心
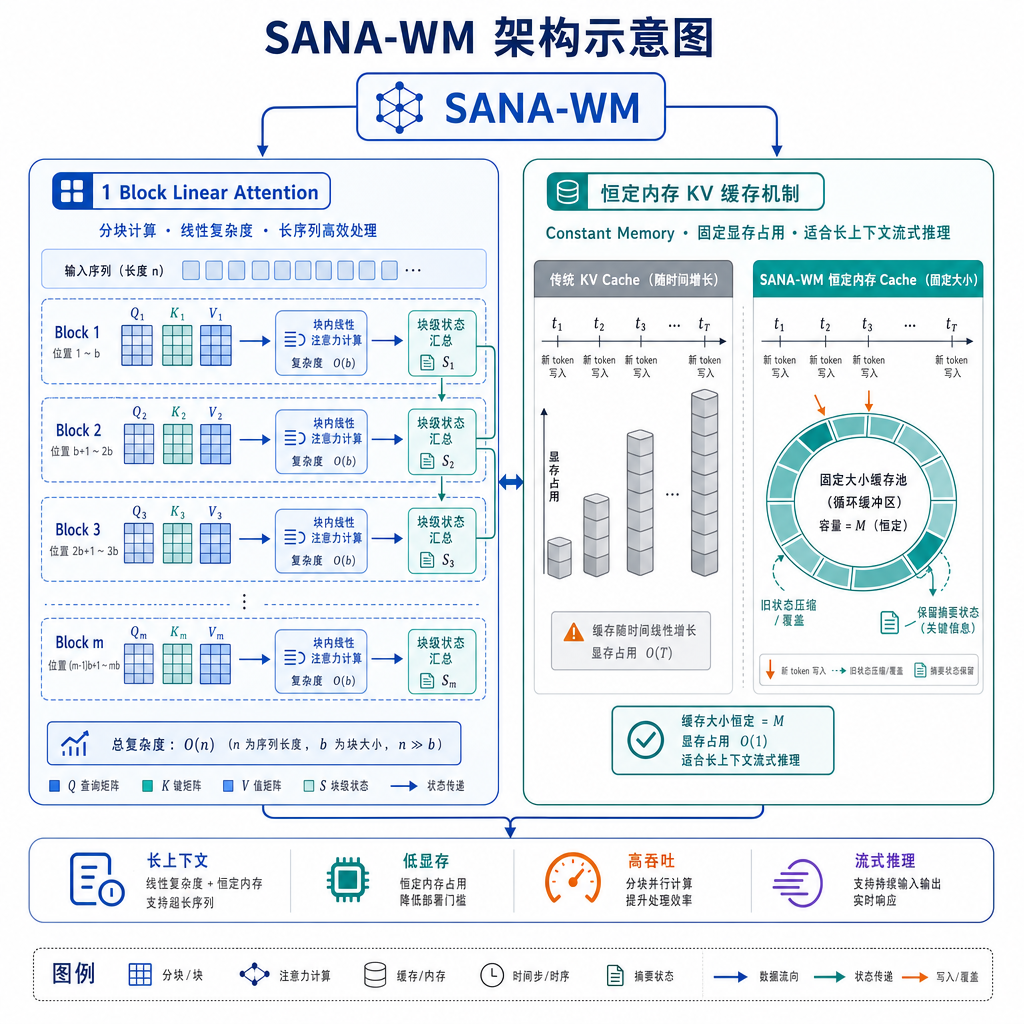
SANA-WM 基于 Block Linear Diffusion Transformer 架构,这是它能做到高效的关键。传统的 Transformer 在处理长序列时,注意力机制的计算复杂度是 O(n²),视频帧数一多就扛不住。SANA-WM 用的是线性注意力(Linear Attention),把复杂度降到 O(n),同时通过分块(Block-wise)的方式处理长视频。
具体来说,它设计了一个「恒定内存 KV 缓存」机制。传统的自回归生成需要存储所有历史帧的 Key-Value 对,内存占用随帧数线性增长。SANA-WM 利用线性注意力的累积特性,把历史信息压缩成一个固定大小的状态向量,内存占用不随视频长度增加。这让它能在有限显存下生成分钟级视频。
训练成本:12 天 64 张 H100,MovieGen 的 1%
英伟达在论文里直接对比了训练成本。SANA-Video 系列模型(包括 SANA-WM)只用了 64 张 H100 训练 12 天,总算力消耗大约是 18,432 GPU-hours。作为对比,Meta 的 MovieGen 用了数千张 GPU 训练数月,保守估计超过 100 万 GPU-hours。SANA 的训练成本确实只有 MovieGen 的 1% 左右。
这个成本差异不只是硬件堆砌的问题,更多是工程优化。SANA 团队在数据过滤和训练策略上做了很多工作。他们用了更激进的数据筛选,只保留高质量、高分辨率的视频样本,同时在训练过程中动态调整分辨率和帧率,避免在低质量数据上浪费算力。
这种「小模型 + 高效训练」的路线,跟 OpenAI 的 Sora、Runway 的 Gen-3 这些闭源大模型形成了鲜明对比。后者追求的是「不计成本堆性能」,SANA 要的是「在有限资源下做到够用」。对开发者和小团队来说,SANA 的路线显然更现实。
性能表现:对标 Wan 2.1 和 SkyReel-V2
英伟达把 SANA-Video 跟两个同量级的开源模型做了对比:Wan 2.1-1.3B 和 SkyReel-V2-1.3B。这两个模型参数量都在 13 亿左右,比 SANA-WM 的 26 亿还小一半,但生成速度慢得多。
在生成 5 秒 720p 视频的测试中,SANA-Video 在 H100 上用 FP16 精度需要 71 秒,切换到 RTX 5090 的 FP4 精度后降到 29 秒。Wan 2.1 和 SkyReel-V2 在同样硬件上需要 400-500 秒,SANA 快了 16 倍左右。
质量方面,SANA-WM 在文本对齐和时间一致性上跟这两个模型差不多,但在细节保真度上稍弱一些。这是小模型的通病——参数量摆在那,很难在所有维度上都做到完美。不过考虑到速度优势,这个取舍是合理的。
更重要的是,SANA-WM 支持「图像 + 文本 + 相机轨迹」的输入方式。你可以给它一张起始图片,加上文字描述和 6 自由度(6-DoF)的相机运动参数,它会生成符合这个轨迹的视频。这种可控性是很多纯文本生成模型做不到的。

部署门槛:RTX 5090 就能跑
消费级硬件部署是 SANA-WM 的一大卖点。英伟达专门测试了在 RTX 5090 上的表现,用的是 NVFP4 精度(4-bit 浮点)。这是英伟达在 Blackwell 架构上新推的低精度格式,专门为生成式 AI 优化。
RTX 5090 有 32GB GDDR7 显存,理论带宽 1.8 TB/s。SANA-WM 在这个配置下,生成 5 秒 720p 视频的显存占用在 24GB 左右,还有余量。如果你想生成更长的视频,可以用分块生成的方式,每次生成 5-10 秒,然后拼接起来。
这个部署门槛对个人开发者来说已经很友好了。RTX 5090 的价格在 2000 美元左右,虽然不便宜,但比租云端 H100 实例便宜多了。而且本地部署没有 API 调用成本,适合需要大量生成的场景。
当然,FP4 精度会带来一定的质量损失。英伟达在论文里提到,FP4 相比 FP16 会有轻微的细节模糊和色彩偏移,但在大多数场景下肉眼难以察觉。如果你对质量要求极高,还是得用 FP16 或 BF16,那就需要更高端的硬件了。
开源策略:代码和权重都放出来了
SANA-WM 的代码和模型权重都在 GitHub 上开源了,仓库地址是 NVlabs/Sana。这个仓库不只有 SANA-WM,还包括之前的 SANA 图像生成模型和 SANA-Video 的其他变体。
代码库提供了完整的训练和推理流程,包括数据预处理、模型训练、推理加速等。推理部分支持多种精度(FP32/FP16/BF16/FP4),也支持多 GPU 并行生成。文档写得比较详细,上手难度不高。
模型权重托管在 Hugging Face 上,有几个不同的版本:
- SANA-WM-2.6B:完整版,26 亿参数,支持 1 分钟 720p 视频生成
- SANA-Video-1.6B:轻量版,16 亿参数,支持 30 秒 720p 视频生成
- SANA-Video-0.6B:超轻量版,6 亿参数,支持 10 秒 480p 视频生成
这几个版本的架构基本一致,主要是层数和隐藏维度不同。你可以根据自己的硬件条件选择合适的版本。
数据和训练细节:高质量数据是关键
SANA 团队在论文里透露了一些训练细节。他们用的数据集主要来自公开的视频数据集,包括 WebVid、Panda-70M 等,总共大约 1000 万条视频片段。但他们没有直接用原始数据,而是做了严格的过滤。
过滤标准包括:
- 分辨率至少 720p,帧率至少 24fps
- 视频长度在 5-60 秒之间
- 运动幅度适中,避免静态画面和剧烈抖动
- 文本描述质量高,避免机器生成的低质量标注
经过过滤后,实际用于训练的数据只有 200 万条左右,是原始数据的 20%。这种「少而精」的策略在小模型训练中很常见——与其让模型在低质量数据上学一堆噪声,不如集中火力在高质量数据上。
训练过程分两个阶段:
- 预训练阶段:用 256x256 分辨率训练 10 天,学习基本的视频生成能力
- 微调阶段:用 720p 分辨率训练 2 天,提升细节和分辨率
这种「先低分辨率再高分辨率」的训练方式也是标准操作,可以大幅降低训练成本。
局限性:还不能跟 Sora 正面刚
虽然 SANA-WM 在效率上做得很好,但跟 OpenAI Sora、Runway Gen-3 这些顶级模型比,差距还是明显的。
首先是生成质量。Sora 能生成 1080p 甚至更高分辨率的视频,细节保真度和物理真实感都更强。SANA-WM 在 720p 下已经有些吃力,放大到 1080p 会出现明显的模糊和伪影。
其次是时长。Sora 官方演示过 1 分钟的视频,而且时间一致性很好。SANA-WM 虽然理论上也能生成 1 分钟,但实际测试中,超过 30 秒后容易出现画面漂移和逻辑断裂。
第三是可控性。Sora 支持复杂的文本提示,能理解物理规律、空间关系、因果逻辑等。SANA-WM 的文本理解能力弱一些,对复杂场景的描述容易出错。
但这些差距是预期之内的。Sora 的参数量可能在百亿级别,训练成本是 SANA 的几百倍。SANA 的定位本来就不是「做最好的视频生成模型」,而是「做最高效的开源视频生成模型」。
应用场景:适合快速原型和低成本生产
SANA-WM 的效率优势让它在一些特定场景下很有用:
游戏开发:用于生成游戏过场动画、环境预览、角色动作参考等。游戏开发中需要大量快速迭代,SANA-WM 的速度优势能显著提升效率。
广告和营销:生成产品展示视频、社交媒体短视频等。这类内容对质量要求不像电影那么高,但需要快速产出,SANA-WM 很合适。
教育和培训:生成教学演示视频、模拟场景等。教育内容更注重清晰度和可理解性,不需要电影级的视觉效果。
原型验证:在正式投入大模型生成之前,用 SANA-WM 快速验证创意和脚本。这能大幅降低试错成本。
对于需要高质量、长时长、复杂场景的专业制作,SANA-WM 还不够格。但对于大量的中低端需求,它已经足够好用了。
与其他开源模型的对比
开源视频生成领域现在有几个主要玩家:
ModelScope(阿里):参数量未公开,生成速度较慢,但质量不错。主要问题是文档和社区支持不够完善。
Zeroscope:基于 Stable Diffusion 改造,参数量在 10 亿左右。生成速度比 SANA 慢,但在某些艺术风格上表现更好。
AnimateDiff:专注于动画风格视频生成,参数量较小(3-5 亿)。速度很快,但只适合特定风格,通用性差。
CogVideoX(智谱):参数量在 50 亿左右,质量接近商业模型,但训练和推理成本都很高。
SANA-WM 在这些模型中的定位是「效率和质量的平衡点」。它不是最快的(AnimateDiff 更快),也不是质量最好的(CogVideoX 更好),但综合来看性价比最高。
未来方向:更长、更高清、更可控
英伟达在论文里提到了几个未来改进方向:
更长的视频:目前 1 分钟是极限,目标是做到 5 分钟甚至更长。这需要进一步优化内存管理和时间一致性。
更高的分辨率:从 720p 提升到 1080p 甚至 4K。这需要更大的模型和更多的训练数据。
更强的可控性:支持更复杂的输入条件,比如多个关键帧、详细的物体轨迹、风格参考图等。
多模态融合:结合音频生成,做到视频和音效同步。这对游戏和影视制作很有用。
实时生成:目前 29 秒生成 5 秒视频,还达不到实时。如果能做到实时或接近实时,应用场景会更广。
这些方向都很有挑战性,但考虑到 SANA 团队在效率优化上的能力,还是值得期待的。
对行业的影响:降低视频生成门槛
SANA-WM 的发布对整个视频生成行业有几个重要影响:
降低技术门槛:之前想做视频生成,要么用闭源 API(贵),要么自己训练大模型(更贵)。SANA-WM 提供了第三条路:用开源小模型在本地跑。这让更多开发者和小团队能参与进来。
推动硬件普及:SANA-WM 能在 RTX 5090 上跑,证明了消费级硬件做视频生成的可行性。这会刺激更多人购买高端显卡,反过来推动硬件厂商继续优化。
加速应用落地:效率提升意味着成本下降,成本下降意味着更多应用场景变得可行。我们可能会看到更多基于视频生成的产品和服务出现。
倒逼闭源模型降价:开源模型的性能越来越好,闭源模型的价格优势会被削弱。OpenAI、Runway 这些公司要么降价,要么在质量上拉开更大差距。
当然,开源模型也有自己的问题,比如缺乏商业支持、文档不完善、社区碎片化等。但总体来说,SANA-WM 这样的项目对行业是利好的。
总结
SANA-WM 是一个务实的项目。它没有追求「世界最强」,而是在有限资源下做到「够用且高效」。26 亿参数、12 天训练、RTX 5090 可部署,这些数字背后是英伟达在工程优化上的深厚积累。
对开发者来说,SANA-WM 提供了一个可行的视频生成方案。你不需要数据中心级的算力,不需要天价的 API 费用,一张高端显卡就能开始实验。虽然它还不能跟 Sora 正面竞争,但对于大量的中低端需求,它已经足够好了。
更重要的是,SANA-WM 证明了「小模型 + 高效训练」这条路是走得通的。在大模型军备竞赛愈演愈烈的今天,这种务实的路线反而可能更有生命力。毕竟,不是所有人都需要用大炮打蚊子。
参考来源
- SANA-WM 官方项目页面 - 英伟达 NVLabs 发布的 SANA-WM 官方介绍和技术细节
- NVlabs/Sana GitHub 仓库 - SANA 系列模型的开源代码和模型权重