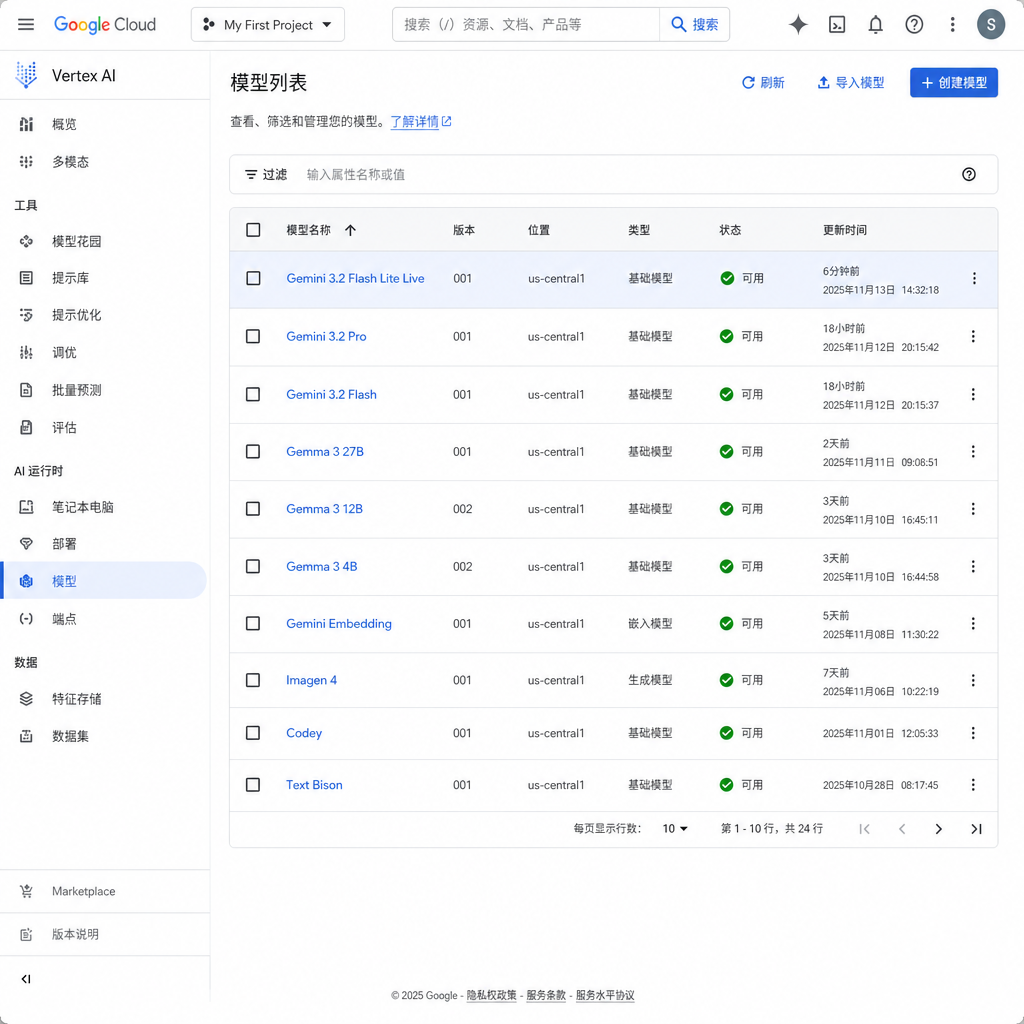
Gemini 3.2 Flash Lite Live 现身 Google Cloud,谷歌在 I/O 前夜泄了底
距离 Google I/O 2026 开幕还有不到 48 小时,谷歌又一次"提前剧透"了自己。5 月 17 日,开发者社区 linux.do 上有人贴出截图,Gemini 3.2 Flash Lite Live 这个模型条目已经出现在 Google Cloud 的后台模型列表中。条目随后被悄悄撤下,但截图已经在 X 和 Reddit 上跑了一圈。
这不是孤立事件。5 月初就有 iOS 端 Gemini App 的模型选择器泄出过 "Gemini 3.2 Flash" 字样,AI Studio 也短暂出现过相关条目,加上 LM Arena 上那个匿名跑分凶猛的神秘模型——谷歌在 I/O 2026 前的小范围灰度测试,基本已经盖戳。
名字拆开看,信息量很大
先别急着讨论"到底是 3.2 还是 3.5"。光"Gemini 3.2 Flash Lite Live"这一串后缀,就把谷歌的产品策略写得明明白白:
- 3.2:代次号。Gemini 3 Pro / 3 Flash 已经在去年底到今年初陆续上线,3.1 Pro 在 iOS 端被瞥见过,3.2 是顺理成章的小版本迭代,不是架构大换代。
- Flash Lite:体量定位。Flash 之下还有 Lite,对标的是 GPT-5 nano、Claude Haiku 这一档,主打极低延迟、极低单价、面向高 QPS 的轻量任务。
- Live:这是最关键的一个词。在谷歌的产品语境里,Live 几乎专指实时双向多模态流式接口,也就是 Gemini Live API 那一套——音频流入、音频流出、视频帧实时理解、低于一秒级延迟。
把三个标签合起来读:一个便宜、轻、专为实时多模态交互优化的 Gemini 3.2 衍生型号。这不是用来跑长文档总结的模型,是用来塞进 AR 眼镜、客服机器人、车载语音、实时翻译耳机里的那种东西。
谷歌在补哪个洞
看看现在的实时多模态市场:OpenAI 有 Realtime API + GPT-4o/GPT-5 Realtime;谷歌自己有 Gemini Live;但真正能打到"廉价、规模化部署"这档的,目前没有。GPT-5 Realtime 单价依然在 $32/1M 音频输入这个量级,跑客服中心每分钟成本算下来肉疼。
Gemini 3.2 Flash Lite Live 卡的就是这个位置。参考 Gemini 2.5 Flash Lite 的定价(输入 $0.10/1M,输出 $0.40/1M),3.2 这一代即便价格略涨,也大概率压在 GPT-5 mini Realtime 的一半以下。对于"语音 agent、实时翻译、视频流监控、语音外呼"这类场景,单价直接决定项目能不能上量。
谷歌这两年的产品打法已经很清晰了——Pro 用来打榜,Flash 用来铺量,Lite 用来抢 API 调用市场份额。3 Flash 上线时官方明说"取代 2.5 Flash 成为 Gemini App 默认模型",把全球免费用户的 token 流量一口气接过来;现在 3.2 Flash Lite Live 顶上来,承接的是开发者市场里那块"既要实时又要便宜"的硬需求。
为什么是 3.2,不是 3.5
linux.do 上有人在问,谷歌的版本号到底怎么数。我的判断是:3.5 短期不会来。
原因很简单——Gemini 3 Pro 去年底才发,Gemini 3 Flash 今年 Q1 才全量。一个新世代模型从训练完成到产品矩阵铺齐,谷歌内部大概需要两到三个季度。3.2 在时间点上更合理,它是在 3 系基座模型之上做后训练优化和能力裁剪,而不是重新预训练。
这也解释了为什么会有 3.2 Flash、3.2 Flash Lite、3.2 Flash Lite Live 这种分叉。同一个 backbone,蒸馏出不同的体量版本,再针对实时流式场景做专门的 RLHF 和延迟优化——谷歌 DeepMind 这套流水线在 Gemini 2 时代就已经跑得很熟了。
GPT-5.5 据说会在 6 月出,谷歌在 I/O 提前两周放出 3.2 系列,舆论窗口的算计味儿很重。
开发者该关心什么
如果你已经在用 Gemini API,几个实际建议:
- 别在 3 Flash 上做强耦合。5 月 19 日的 keynote 之后,3.2 系列大概率会很快开放预览,default 模型也会跟着切换。任何写死 model name 的代码要么走配置化,要么准备一周内改一遍。
- Live 接口的 SDK 改动可能不小。Gemini Live 现在用的是 WebSocket + 自定义协议,3.2 Flash Lite Live 如果要进一步压延迟,端到端协议可能会动。看 release note 时重点关注
BidiGenerateContent这块。 - 关注上下文窗口。LM Arena 那个候选模型在 80 万 token 上下文里没明显掉质量,这意味着 3.2 系列可能把长上下文能力下放到 Flash Lite。对 RAG 场景是利好。
OpenAI Hub 这边已经在跟进 3.2 系列的接入,3 Flash 目前可以直接通过兼容 OpenAI 格式的接口调用,3.2 Flash Lite Live 一旦开放预览会同步上线。对于不想折腾 Vertex AI 鉴权和区域限制的开发者,一个 Key 切 GPT-5、Claude、Gemini 的方式确实省事——尤其是做模型对比测试的时候。
基础调用示例(待 3.2 Flash Lite Live 正式开放后替换 model 名即可):
from openai import OpenAI
client = OpenAI(
api_key=\"your-openai-hub-key\",
base_url=\"https://api.openai-hub.com/v1\"
)
resp = client.chat.completions.create(
model=\"gemini-3-flash\", # 待替换为 gemini-3.2-flash-lite-live
messages=[
{\"role\": \"system\", \"content\": \"你是一个实时语音助手。\"},
{\"role\": \"user\", \"content\": \"用一句话解释 Gemini Live 和 Realtime API 的区别。\"}
],
temperature=0.3,
)
print(resp.choices[0].message.content)
实时流式(Live)接口形态目前在各家都还没有完全统一的 OpenAI 兼容标准,3.2 Flash Lite Live 正式发布后,预计会同时提供原生 Gemini Live 协议和 Realtime 兼容协议两条路径。
还有一个变量:定价分层
谷歌从 2.5 这一代起,开始在输出 token 上做差异化定价——同样是 Flash,长输出场景比短输出场景贵得多。这套打法的好处是:把"长上下文短回答"的 RAG/搜索类客户和"短上下文长生成"的内容创作类客户区分开收费。
3.2 Flash Lite Live 如果延续这套定价逻辑,对实时音频场景反而是利好——语音回答天然短,输出 token 用量低,单分钟成本可能比表面上的 per-token 价格看起来更低。
5 月 19 日见
Google I/O 2026 在加州山景城的 Shoreline Amphitheater,5 月 19 日和 20 日两天。按谷歌这两年的节奏,开场 keynote 大概率会一口气放出:
- Gemini 3.2 系列(Pro / Flash / Flash Lite / Flash Lite Live)的完整阵容
- 价格表更新
- 新版 AI Studio 和 Antigravity 的集成
- 至少一个面向 Android 的端侧 Gemini Nano 更新
至于 3.2 到底能不能在跑分上压过 GPT-5 mini、能不能在 Live 场景里把 OpenAI Realtime 的成本拉下马,48 小时后见分晓。
参考来源
- linux.do:新模型 Gemini 3.2 Flash Lite Live 已经出现在 Google 云端平台 —— 国内开发者社区首发爆料,附后台截图