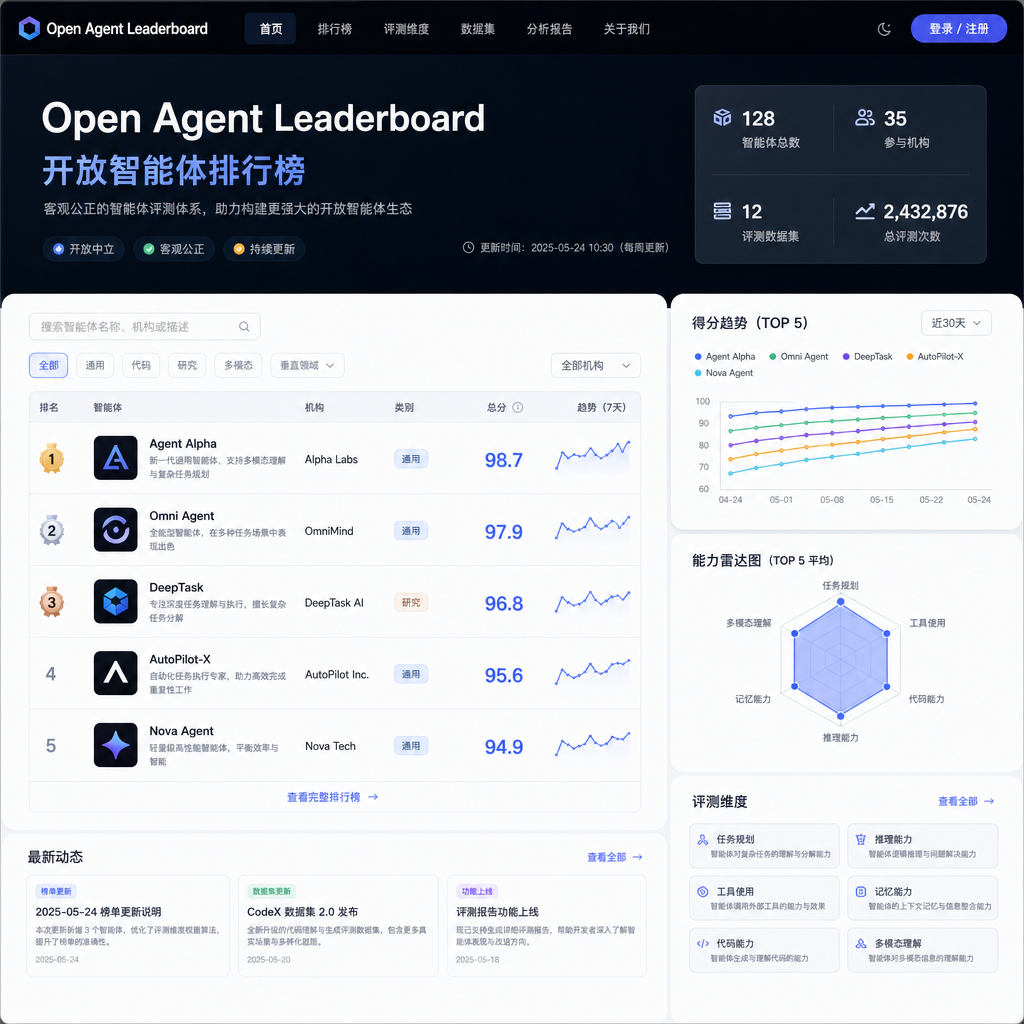
HuggingFace 上线首个智能体榜单,智能体评测进入标准化时代
HuggingFace 联合 IBM Research 推出了 Open Agent Leaderboard,这是业内首个专门针对智能体(Agent)性能的公开评测榜单。与此前聚焦于单轮对话能力的 Open LLM Leaderboard 不同,这个新榜单把评测重心放在了智能体的多步推理、工具调用和任务规划能力上。
这件事的意义在于,智能体评测终于有了一个相对统一的参照系。过去一年里,各家都在做 Agent,但评测标准五花八门,有的看数学题正确率,有的看 API 调用成功率,有的看多轮对话连贯性,根本没法横向比较。现在 HuggingFace 把这些维度整合到一个榜单里,至少让开发者知道自己的 Agent 在行业里处于什么水平。
评测什么:不只是答题,更看重推理链路
Open Agent Leaderboard 目前主要聚焦数学推理任务,这是个聪明的切入点。数学题有明确的对错标准,推理过程可追溯,而且对智能体的核心能力——多步规划和中间结果验证——要求很高。
榜单收录了几种主流智能体实现方式:
- Chain-of-Thought (CoT):最基础的思维链提示,让模型一步步写出推理过程
- Self-Consistency CoT (SC-CoT):多次采样取一致性最高的答案,用投票机制提升准确率
- ReAct:推理与行动交替进行,模型可以调用外部工具验证中间结果
- Reflexion:带反思机制的智能体,能从错误中学习并调整策略
这几种方法代表了当前 Agent 设计的主要思路。CoT 是最轻量的,基本不增加推理成本;SC-CoT 用多次采样换准确率,成本高但效果稳定;ReAct 和 Reflexion 则需要模型具备更强的自我监控能力,对底层 LLM 的要求更高。
从已公布的结果看,闭源模型在复杂推理任务上仍然领先,但开源模型的差距在缩小。特别是在配合 SC-CoT 这类工程化方法后,一些 70B 参数的开源模型已经能接近 GPT-4 早期版本的表现。这说明智能体能力不完全取决于模型规模,推理框架的设计同样关键。
评测怎么做:统一环境,可复现
HuggingFace 这次做得比较扎实的一点是,所有评测都在统一的环境下跑,代码开源,数据集公开。这避免了各家自说自话的问题——以前经常看到某个模型声称在某任务上达到 SOTA,但换个测试集或者调整下 prompt 模板,结果就完全不一样。
榜单使用的数据集包括 GSM8K、MATH 等经典数学推理基准,以及一些多模态任务。评测指标不只看最终答案的准确率,还会记录推理步数、工具调用次数、错误恢复能力等中间过程指标。这些细节对实际应用很重要——一个答对了但用了 50 步推理的 Agent,在生产环境里可能还不如一个答错了但只用 5 步的 Agent 实用。
更重要的是,榜单提供了标准化的评测脚本。开发者可以直接把自己的 Agent 实现提交上去跑分,不需要自己搭环境。这大幅降低了参与门槛,也让榜单的更新速度能跟上模型迭代的节奏。
为什么现在做这件事
时机选得不错。2024 年下半年开始,Agent 从实验室概念变成了实际产品形态。OpenAI 的 GPTs、Anthropic 的 Claude Projects、Google 的 Gemini Extensions,都在往「让模型自己规划任务、调用工具」的方向走。开源社区也跟进很快,LangChain、AutoGPT、MetaGPT 这些框架把 Agent 开发的门槛降到了普通开发者也能上手的程度。
但问题是,大家都在做 Agent,却没人说清楚什么样的 Agent 算好。有的团队追求推理步数少,有的追求准确率高,有的追求成本低,各有各的优化目标。Open Agent Leaderboard 的出现,相当于给这个野蛮生长的领域立了一根标杆。
从商业角度看,这个榜单对模型厂商和应用开发者都有价值。模型厂商可以用它来证明自己的模型适合做 Agent 底座,应用开发者可以用它来选型——不用自己花时间测一遍,直接看榜单就知道哪个模型在哪类任务上表现好。
当前榜单的局限性
不过这个榜单现在还处于早期阶段,有几个明显的短板:
任务覆盖面窄。目前主要是数学推理,多模态任务只是试验性质。实际应用中,Agent 要处理的任务类型远比这复杂——代码生成、数据分析、多轮对话、长文档理解,每一类都有自己的评测难点。数学题做得好,不代表写代码也行。
缺少成本维度。榜单只看效果,不看成本。但在生产环境里,一个需要调用 10 次 API 才能完成任务的 Agent,和一个只需要 2 次的 Agent,成本差了 5 倍。对于高频调用的场景,这个差异是致命的。
工具调用能力没有充分体现。现在的评测主要还是在测模型的推理能力,对于 Agent 最核心的「什么时候该调用什么工具」这个判断能力,评测得不够深入。真实场景里,Agent 面对的是几十上百个可用工具,如何选择、如何组合、如何处理工具返回的异常结果,这些都是硬骨头。
开源模型的部署细节被忽略了。榜单上的开源模型都是在理想环境下跑的,但实际部署时,量化、推理优化、并发控制这些工程问题都会影响最终表现。一个在榜单上排第三的模型,部署到生产环境后可能还不如排第五的好用。
对开发者的实际影响
如果你在做 Agent 相关的产品,这个榜单值得关注,但不要盲目追榜。
选模型时,先看任务类型。如果你的 Agent 主要处理数学或逻辑推理任务,榜单的参考价值很高。但如果是做客服、内容生成、数据分析这类任务,榜单的指导意义就弱很多。
关注推理框架,不只是模型本身。榜单上同一个模型配不同的 Agent 框架,得分差异很大。这说明框架设计的重要性不亚于模型选择。如果你用的是开源模型,花时间优化 prompt 模板、调整推理策略,可能比换个更大的模型更有效。
成本和效果要平衡。榜单上排名靠前的方案,往往是多次采样或者多步验证,推理成本很高。如果你的应用对延迟敏感或者调用量大,可能需要在准确率和成本之间做取舍。
把榜单当起点,不是终点。榜单提供的是通用场景下的表现,但每个应用都有自己的特殊需求。最靠谱的做法是,先用榜单筛选出几个候选方案,然后在自己的数据集上做针对性测试。
智能体评测的下一步
Open Agent Leaderboard 只是个开始。智能体评测要真正成熟,还需要解决几个问题:
多模态任务的标准化。现在的 Agent 越来越多地需要处理图像、音频、视频,但这些模态的评测标准还很模糊。什么叫「理解了一张图」?是能描述出图里有什么,还是能根据图做推理?不同的定义会导致完全不同的评测结果。
长周期任务的评测。真实场景里的 Agent 往往需要执行跨越几小时甚至几天的任务,中间可能要处理各种异常、调整计划、与用户交互。现在的评测都是短平快的单次任务,没法反映这种长周期能力。
安全性和可控性。Agent 的自主性越强,失控的风险就越大。评测体系里需要加入安全维度——Agent 会不会执行危险操作、会不会泄露敏感信息、会不会被恶意 prompt 诱导。这些在生产环境里都是硬性要求。
人机协作能力。最实用的 Agent 不是完全自主的,而是能在关键节点请求人类确认、能理解人类的模糊指令、能从人类反馈中快速调整。这种协作能力很难用自动化指标衡量,但对实际应用至关重要。
HuggingFace 这次迈出了第一步,但智能体评测这条路还很长。好在有了这个榜单,至少行业有了一个共同的讨论基础。接下来看各家怎么跟进,以及榜单本身会不会根据社区反馈快速迭代。
从更大的视角看,Open Agent Leaderboard 的出现标志着 Agent 开发正在从「炼丹」阶段进入工程化阶段。有了标准化的评测,才能有标准化的优化方法,才能让更多开发者参与进来。这对整个 AI 应用生态是件好事。
对于国内开发者来说,如果想快速接入各类大模型来测试自己的 Agent 实现,可以考虑用 OpenAI Hub 这类聚合平台——一个 API Key 就能调用 GPT、Claude、Gemini、DeepSeek 等主流模型,省去了分别对接各家 API 的麻烦,而且国内直连,不用担心网络问题。
参考来源
- The Open Agent Leaderboard - Hugging Face Blog - HuggingFace 官方博客对榜单的详细介绍
- Open Agent Leaderboard - Hugging Face Space - 榜单实时查看页面
- Open Agent Leaderboard: 开源智能体评测榜单 - 知乎 - 中文社区对榜单的解读
- Open LLM 排行榜近况 - 博客园 - HuggingFace 此前推出的 LLM 榜单背景