Gemini 3.5 Flash 曝光:900 TPS 推理速度,大参数模型进入速度新时代
谷歌还没官宣,Gemini 3.5 Flash 就已经在反重力(Antigravity)平台上跑起来了。
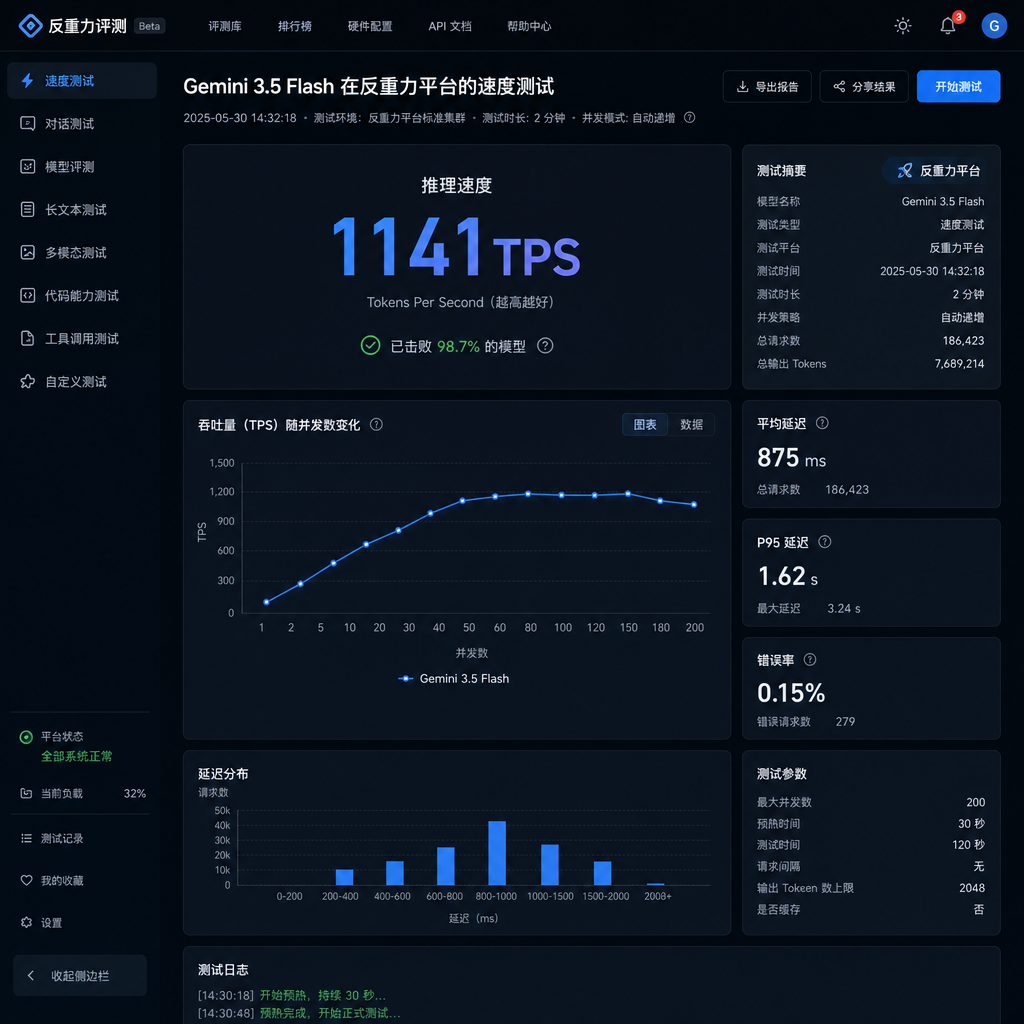
根据多位开发者在 Linux.do 社区的实测,这个新模型的推理速度达到了 600-900 TPS(tokens per second),写代码时甚至能飙到 1141 TPS。作为对比,目前 Google AI Studio 官网的 Gemini 3 Flash 速度只有 100 TPS 左右。速度提升 3-9 倍,但能力没退步——这才是真正值得关注的地方。
速度提升的背后:大参数模型的工程突破
Gemini 3.5 Flash 的参数量估计和 Gemini 3 Pro 在一个级别,甚至可能更多。按照业内推测,这个量级至少在千亿参数以上。在这个规模下还能跑出 900 TPS,意味着谷歌在模型推理优化上有了实质性突破。
开发者测试显示,在 44k 上下文的实际编码场景中,Gemini 3.5 Flash 稳定输出 1141 TPS。这个速度是什么概念?一个完整的 Vue 前端组件,从需求描述到代码生成,整个过程可能只需要几秒钟。
更关键的是首字延迟(time to first token)极低。在 5k 输出的测试中,去除思考时间后,模型几乎是"秒回"。这种体验对于需要实时交互的应用场景——比如代码补全、实时翻译、对话系统——是质的飞跃。
能力没退步,该对的题还是对
速度快了,能力有没有缩水?这是所有人关心的问题。
开发者用几个经典测试题验证了 Gemini 3.5 Flash 的推理能力:
- 糖果题:Gemini 3 Flash 需要思考 70 秒以上才能给出正确答案,Gemini 3.5 Flash 只需要不到 20 秒
- 色盲题和洗车题:都能正确回答
- SimpleBench:稳定 9/10 分,概率全对
前端能力测试中,Gemini 3.5 Flash 能够生成完整的 Minecraft 沙盒游戏界面和高级天气卡片组件,代码质量和前代持平。写文档、知识库问答等任务也没有明显退步。
这说明谷歌在优化推理速度时,并没有通过降低模型能力来换取性能。更可能的情况是:通过更激进的量化策略、更高效的注意力机制(比如 FlashAttention 的进一步优化)、以及专用硬件加速(TPU v6 或更新版本)来实现速度提升。

反重力平台的灰度测试
目前 Gemini 3.5 Flash 还没有在 Google AI Studio 正式上线,但已经在反重力平台开始灰度测试。用户选择 "3f" 模型时,有概率会被分配到新版本。
反重力是谷歌内部使用频繁的 AI 编程平台,推出 4 个月就拿下了约 6% 的开发者采用率。虽然和 Anthropic 的 Claude Code、OpenAI 的 Codex 相比还有差距,但作为谷歌的 AI Agent 战略载体,反重力的定位更像是一个实验场——新模型、新功能都会先在这里测试,收集真实使用数据后再推向更广泛的市场。
Gemini 3.5 Flash 选择在反重力平台灰度,说明谷歌对这个模型的定位很明确:面向开发者,主打编码和 Agent 场景。
大参数模型的速度焦虑
过去一年,AI 行业有个共识:大模型的能力天花板在提升,但推理速度成了瓶颈。
OpenAI 的 GPT-5.5、Anthropic 的 Opus 4.7,这些顶级模型的推理速度通常在 50-150 TPS 之间。对于需要实时响应的应用——比如代码补全、实时对话、游戏 NPC——这个速度还是太慢了。
业内的解决方案主要有两个方向:
小模型路线:用蒸馏、剪枝等技术把大模型压缩到几十亿参数,速度能上去,但能力会打折扣。典型代表是各家的 "Lite" 或 "Mini" 版本。
工程优化路线:保持模型规模,通过推理引擎优化、硬件加速、量化技术来提速。这条路更难,但收益更大——能力不降,速度还能上去。
Gemini 3.5 Flash 显然走的是第二条路。900 TPS 的速度,配合千亿级参数的能力,这个组合在当前市场上几乎没有对手。
阶跃星辰的 Step 3.5 Flash 也主打推理速度,最高 350 TPS,但那是通过稀疏 MoE 架构实现的——每个 token 只激活约 110 亿参数。Gemini 3.5 Flash 的参数量明显更大,速度还能做到 900 TPS,技术难度不在一个量级。
和 GPT-5.5、Opus 4.7 的竞争
谷歌这次的节奏很有意思。Gemini 3 Pro 发布后,ChatGPT 的流量两周内掉了 6%。OpenAI 被迫把原定 12 月底发布的 GPT-5.2 提前到 12 月 11 日。谷歌紧接着在 6 天后推出 Gemini 3 Flash,趁 GPT-5.2 还没站稳脚跟就抢占市场。
现在 Gemini 3.5 Flash 又在灰度测试,这个节奏明显是在对标 OpenAI 即将推出的 GPT-5.5 和 Anthropic 的 Mythos。
从能力上看,Gemini 3.5 Flash 可能还达不到 GPT-5.5 或 Mythos 的水平。英国 AI 安全研究所(AISI)的测试显示,Mythos 是首个同时通过两项高强度网络安全测试的模型,GPT-5.5 只通过了一项。Gemini 3 Pro 在这些测试中的表现还没有公开数据。
但速度是 Gemini 3.5 Flash 的杀手锏。900 TPS 的推理速度,意味着它可以覆盖更多实时交互场景。对于需要快速响应的应用——客服机器人、代码补全、实时翻译——速度优势可能比绝对能力更重要。
而且,Gemini 3.5 Flash 的定价策略很激进。输入成本只有 Pro 版本的四分之一,而且不会随上下文长度涨价。Pro 版本在上下文超过 200k 后价格翻倍,Flash 则保持不变。这对需要处理长文本的企业用户来说,成本优势是压倒性的。
Flash 和 Pro:不是替代,是互补
Gemini 3.5 Flash 不是来取代 Gemini 3 Pro 的,两者的定位完全不同。
Pro 版本适合处理极复杂的逻辑推理任务,比如多步骤的数学证明、复杂的代码重构、需要深度思考的战略分析。它的"深度思考"模式在这些场景下还是有优势的。
Flash 版本则是"多面手":速度快、成本低,能覆盖 80% 的日常任务。对于大多数企业应用——客服、文档处理、代码生成、数据分析——Flash 的性价比更高。
在 SWE-bench Verified(AI 编程助手测试标准)中,Flash 的得分是 78.0%,略高于 Pro 的 76.2%。这说明谷歌在 Flash 上强化了代码生成和跨模态解析能力,让它更适合作为 AI Agent 的核心引擎。
这个策略很聪明:Pro 版本守住能力天花板,Flash 版本打性价比和速度,两者配合覆盖不同场景。用户可以根据任务复杂度动态选择模型,而不是被锁定在一个模型上。
AI 竞争的新阶段:从"拼肌肉"到"比内功"
Gemini 3.5 Flash 的出现,标志着 AI 竞争进入了新阶段。
过去大家都在拼参数量、拼 benchmark 分数,比谁的"块头"大。现在开始比"巧劲"了:用更少的成本、更快的速度,实现更精准的效果。
这个转变背后是市场需求的变化。企业用户不再满足于"能用"的 AI,他们要的是"好用"的 AI——响应快、成本低、能落地。Gemini 3.5 Flash 的 900 TPS 速度和四分之一的成本,正是在回应这个需求。
另一个变化是赛道的转移。从"聊天机器人"跃迁到"AI Agent 时代"。Flash 的定位很明确:作为 Agent 的核心引擎,在终端、浏览器、编辑器之间快速切换,随时响应不同任务。
谷歌的 Antigravity 平台、即将推出的 Gemini Spark(全天候 AI 智能体),都是在为这个时代做准备。Flash 的速度优势,让它成为这些 Agent 系统的理想选择。
OpenAI Hub 已支持 Gemini 3.5 Flash
对于国内开发者来说,直接访问 Google AI Studio 还是有门槛的。OpenAI Hub 已经接入了 Gemini 3.5 Flash,可以通过统一的 API 调用,无需科学上网。
调用方式和 OpenAI 格式完全兼容,只需要切换 base_url 和 model 参数:
from openai import OpenAI
client = OpenAI(
api_key=\"your-openai-hub-key\",
base_url=\"https://api.openai-hub.com/v1\"
)
response = client.chat.completions.create(
model=\"gemini-3.5-flash\",
messages=[
{\"role\": \"user\", \"content\": \"用 Vue 3 写一个天气卡片组件\"}
],
stream=True
)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end=\"\")
对于需要高并发、低延迟的应用场景,Gemini 3.5 Flash 的 900 TPS 速度能显著提升用户体验。而且成本只有 Pro 版本的四分之一,对于需要大规模调用的企业来说,这个性价比很难拒绝。
写在最后
Gemini 3.5 Flash 还没正式发布,但它已经展示了大参数模型在速度优化上的可能性。900 TPS 的推理速度,配合千亿级参数的能力,这个组合在当前市场上几乎是独一份。
谷歌的策略很清晰:用 Pro 版本守住能力天花板,用 Flash 版本打性价比和速度,两者配合覆盖不同场景。这个打法比单纯堆参数、拼 benchmark 更务实,也更符合企业用户的实际需求。
AI 行业的竞争,正在从"拼肌肉"转向"比内功"。谁能在保持能力的同时把速度和成本做到极致,谁就能在下一阶段的竞争中占据优势。Gemini 3.5 Flash 的出现,给这个问题提供了一个很有说服力的答案。
参考来源
- 1141 TPS!谷歌新 gemini-3.5flash 简单测评 - Linux.do 社区开发者实测 Gemini 3.5 Flash 推理速度和能力
- gemini3 flash 新模型简单测试 - 糖果题、色盲题等经典测试题验证
- antigravity 新 3 Flash 速度约为 600-800 tok/s - 5K 输出场景下的速度测试数据