Odyssey 在今天放出了 Agora-1,定位很直接:第一个把"多智能体"当成核心命题来做的世界模型。一句话概括它做了什么——以前的世界模型基本只能让一个"你"在生成出来的世界里走来走去,Agora-1 让多个独立的智能体可以同时存在于同一个世界里,互相看到对方、互相影响对方的下一步。
这件事听起来好像没那么炸裂,但放到当前的世界模型版图里看,它补的恰恰是最关键的一块短板。
为什么"多智能体"是世界模型躲不开的坎
过去 18 个月,世界模型几乎是 AI 圈密度最高的新战场。DeepMind 的 Genie 2、英伟达的 Cosmos、World Labs 上个月刚更新的 Marble 1.1、华为盘古 5.5 里的世界模型、再加上小鹏 X-World、智元、智象未来 HiDream-O1 这一票国内玩家,路线五花八门:有的押空间智能,有的押全模态生成,有的押具身控制底座。
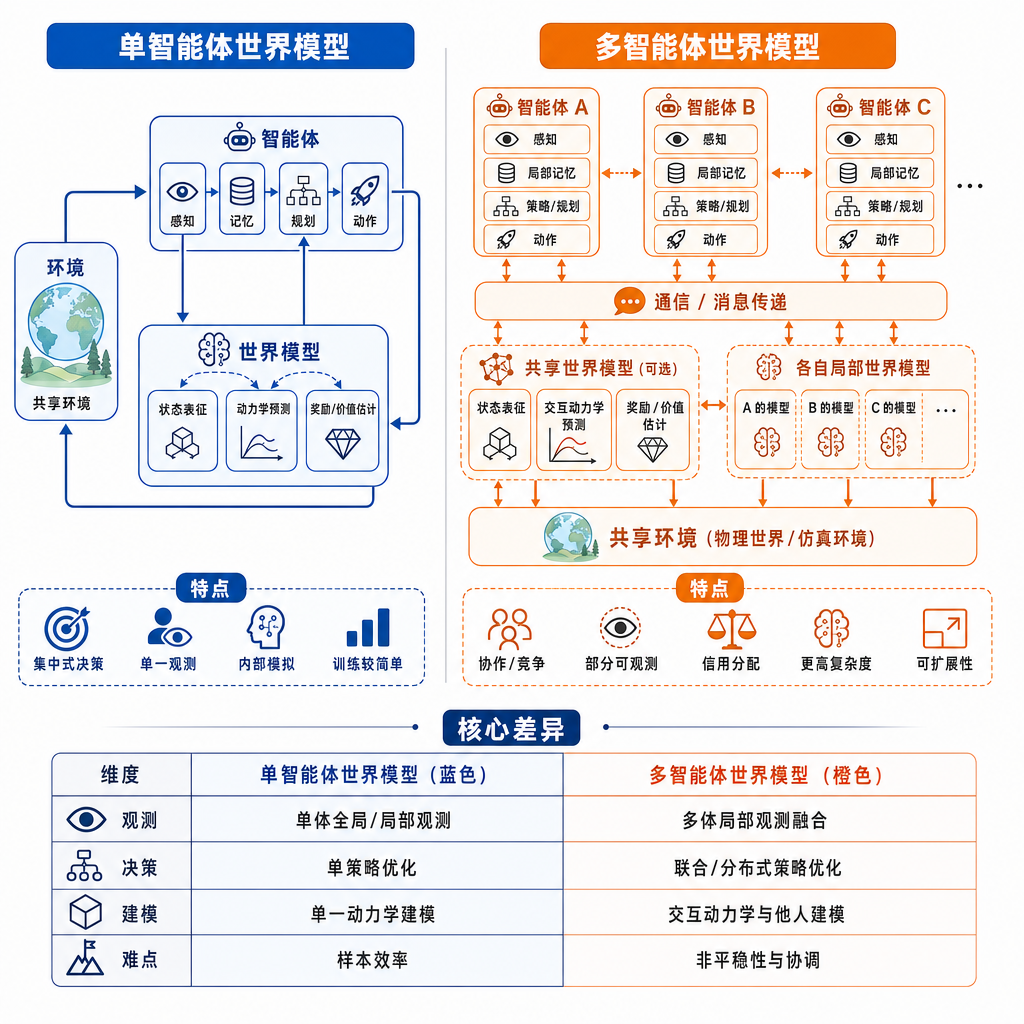
但你把这些模型拉到一起比,会发现一个共同的"假设"——世界里基本只有一个观察者/行动者。Marble 那种几分钟搬一个房间进 3D 空间的能力很惊艳,可那是个"静态可漫游"的世界;Genie 2 是单玩家在生成帧里推进;Cosmos 也主要服务自动驾驶里"自车视角 + 周围交通参与者作为环境一部分"的设定。
这套范式做内容生成、做游戏 demo、做单体机器人训练都没问题。可一旦要解决下面这几类场景,单智能体的世界模型立马显得不够用:
- 多机器人协作:仓储里两台 AGV 同时进同一个货道,谁让谁,看到对方的下一步动作怎么改自己的计划
- 自动驾驶里的博弈:变道时旁车司机的反应不是环境,是另一个会盘算的智能体
- 多人游戏 / 仿真训练:NPC 之间要有合理的互动,不能各自活在自己的世界里
- 群体具身智能:人形机器人和人、和别的机器人共处一室,行为要相互一致
世界模型如果不能让多个智能体在同一份"物理"和"事件"里共存,那它建模的就不是真实世界,是单人副本。Agora-1 想解决的就是这个。
Agora-1 到底做了什么不一样的事
从 Odyssey 放出来的内容看,Agora-1 的核心改动不是把单智能体世界模型"复制几份"那么简单——那种做法在工程上太脆弱,每个智能体看到的世界状态会很快漂移到不一致,物理也对不齐。
Agora-1 的思路是把多智能体当成模型的一等公民来训练:
- 共享的世界状态。所有智能体共用同一份底层世界表征,而不是各自维护一套幻觉。一个智能体推开门,另一个智能体看过去,门是一样的状态。
- 以智能体为单位的观察生成。世界状态是统一的,但每个智能体拿到的观察是从它自己视角渲染出来的——位置、朝向、可见性都各算各的。
- 动作的并行解算。多个智能体在同一时间步给出动作,模型要联合解算这些动作之间的因果与冲突,而不是串行假装其他智能体不存在。
说白了,它在世界模型这一层上做了一件以前主要靠仿真引擎硬写规则才能做的事——让"世界"对所有人是一致的。区别在于,以前的物理仿真器靠的是手写动力学和碰撞检测,Agora-1 走的是从数据里学出来的生成式路径,理论上可以泛化到那些没法手写规则的开放场景。
这一点是值得展开多说一句的。传统的多智能体仿真比如 Habitat、Isaac Sim、CARLA,都不是"生成"出来的,是搭出来的——你得有 3D 资产、有规则、有脚本。它们的天花板就是你能造出多少资产。Agora-1 这种生成式世界模型如果能把多智能体一致性做稳,意味着你可以让模型直接吐出训练环境,而且环境里有真正在"博弈"的其他智能体。这对具身智能和 RL 训练来说,是一种潜在的供给侧革命。
跟当下其他世界模型摆在一起看
横向对一下当下这条赛道上几个有代表性的位置:
- World Labs / Marble 系列:押"空间智能",强项是从一张图生成可漫游的高保真 3D 空间,4 月底刚把 Marble 1.1 和 1.1-Plus 推上去,画质和空间尺度做了取舍。但本质还是单观察者的可探索世界。
- DeepMind Genie 2:交互式视频生成,玩家可以推进世界,但也是单玩家场景。
- 英伟达 Cosmos:偏向自动驾驶和具身机器人的预训练基座,强调物理世界的"常识",多体行为通常被建模为环境噪声而不是另一个 agent。
- 华为盘古世界模型(去年 6 月 HDC 发布的那版):主打点云和视频双模态生成,用于智驾和机器人的数字物理空间。
- 智象未来 HiDream-O1:走原生全模态生成路线,UiT 架构试图把图像、视频、动作 token 拉到一个模型里。
- Odyssey Agora-1:多智能体一致性和交互行为是命题作文。
你会发现,这些团队其实在切蛋糕的不同面。World Labs 切空间,智象切全模态生成,Cosmos 切物理常识,Agora-1 切的是社会性和交互性——一个世界里有多个会想事儿的"人"。
这不是谁压倒谁的关系,更像是世界模型的不同侧面,最终大概率是要合在一起的。但谁先把自己那块做扎实,谁就在下一阶段更值钱。Agora-1 选的这块,恰好是落地到机器人协作、自动驾驶、群体仿真时绕不过去的环节。
一些克制的判断
说几个我觉得需要冷静看的点。
第一,多智能体一致性是个长期问题,不是一个版本能彻底解决的。视频生成这两年一致性问题大家都见过——同一个角色走两步换张脸是常事。让 N 个智能体在长时间序列里都对一份共享世界保持一致,难度只会更高。Agora-1 在 demo 里能做到几分钟级别的多体交互已经不容易,但工业级落地需要的是几十分钟、上小时不漂移,这条路还长。
第二,生成式世界模型 vs 传统仿真器的关系,短期内是互补不是替代。像 RL 训练、机器人测试这些场景,可重复、可控、可解析仍然是仿真器的优势。生成式世界模型的杀手锏在于覆盖那些"造不出来"的开放长尾场景。Agora-1 真正的价值落点,可能是当传统仿真器写不下去的时候,它能把训练数据的供给续上。
第三,多智能体世界模型对算力和数据的要求比单体高一个量级。共享状态、视角分发、动作联合解算,每一项都加成本。Odyssey 这次把 Agora-1 端出来意味着工程上跑通了,但商业化定价和可用性还要看后续披露。
对开发者意味着什么
如果你在做这几类东西,Agora-1 这条线值得关注:
- 多机器人调度和协作的仿真训练:以前要么硬写仿真,要么靠真实环境跑数据,现在多了一个"让模型生成训练环境"的选项
- 自动驾驶的交互场景挖掘:长尾的博弈型 corner case 一直缺数据,多智能体世界模型有可能批量造出来
- AI NPC 和游戏内容生成:从"会说话的 NPC"往"会跟其他 NPC 在世界里互动的 NPC"走,世界模型这一层就得撑得住
- 群体行为研究和社会仿真:经济学、社会学里很多模型以前只能跑 agent-based simulation,现在多了一个生成式底座可以接
值得说一句的是,世界模型这个赛道目前主要还是各家自有 SDK 和 API 的形态,跟我们平时调 LLM 那种统一接口的体验不太一样。OpenAI Hub 这种聚合平台目前还是以语言模型和多模态生成模型为主——GPT、Claude、Gemini、DeepSeek 那一类是即开即用的;世界模型类目前更接近"专用基座 + 自有工具链"的阶段。等这条赛道再跑一阵,接口标准化之后,聚合层应该才会真正接得住。
写在最后
世界模型这一年的演进有个有意思的规律——每隔几周就有一家把这件事的某个维度往前推一步。Marble 1.1 推画质和空间尺度,盘古推点云和工业落地,HiDream 推架构原生全模态,Agora-1 这次推的是多智能体一致性。
这些模型最终会不会收敛到一个统一架构上很难说,但有一点比较确定:从"AI 能聊天"到"AI 能在一个共享世界里行动",中间这一段路,世界模型是绕不过去的。Agora-1 把多智能体这块短板补上之后,这条路又少了一个借口。
参考来源
- 开源智能体通信协议对比分析:MCP、ANP、Agora(知乎专栏) — 关于 Agora 在多智能体通信协议层面的背景介绍,可作为名词对照参考