5 月 19 日,阿里云在 Qwen Chat 和 Arena AI(前身 LMArena)上悄悄挂出了两个新模型:Qwen3.7-Max-Preview 和 Qwen3.7-Plus-Preview。没有发布会,没有博客文章,连官方推特也只是甩了一句 "Qwen 3.7 Preview"。但所有人都明白这是什么信号——明天(5 月 20 日)就是阿里云峰会,Qwen3.7 正式版已经上膛。
这种 "先丢榜单、后开发布会" 的玩法,Qwen 团队已经轻车熟路。从 Qwen3-Max 到 Qwen3.5、再到 Qwen3.6,每一代旗舰几乎都是先在 Arena AI 拿成绩、再走正式发布流程。理由也不复杂:在第三方盲测榜单上先把分数刷出来,比自己写技术博客更有说服力。
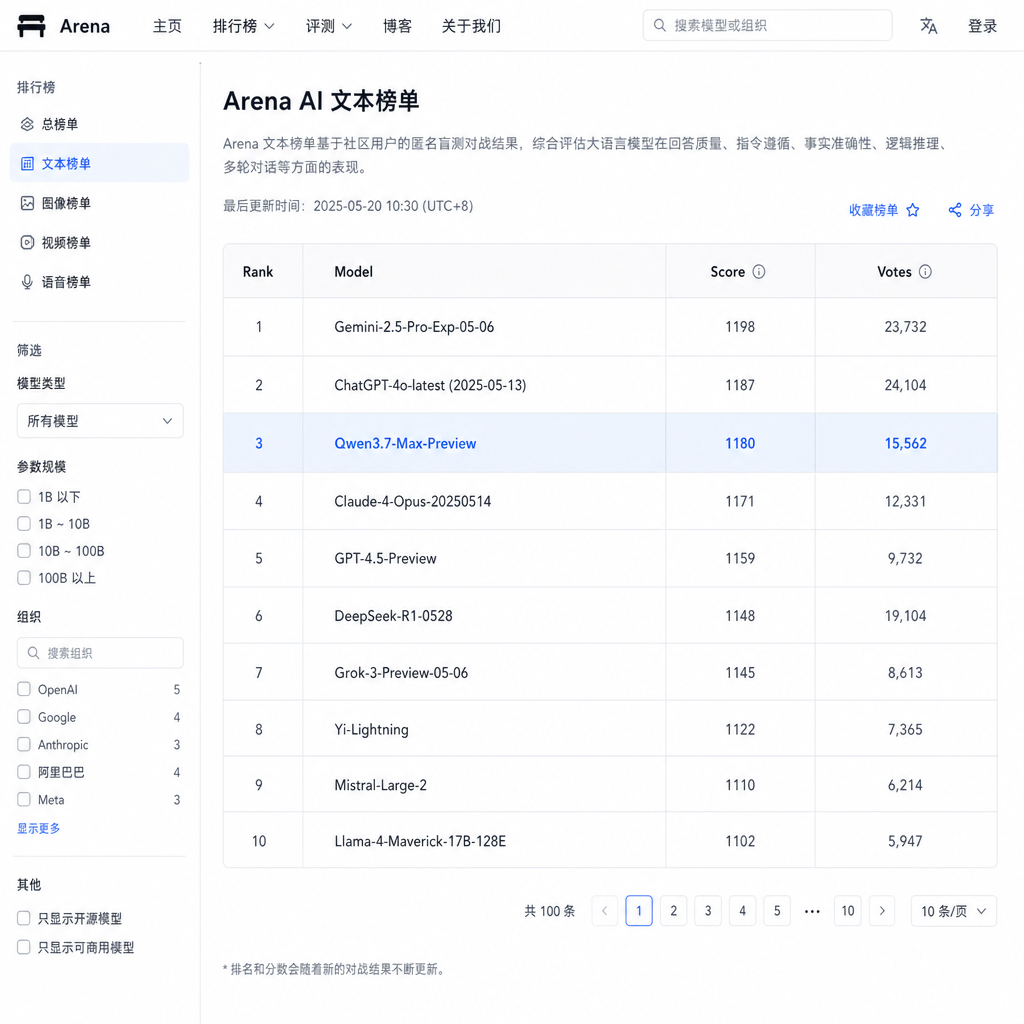
榜单成绩:能打,但还不是断崖式领先
先说硬数据。在 Arena AI 文本竞技场上,Qwen3.7-Max-Preview 综合排名第 13 位,让通义千问在所有参赛实验室里排到第 6。子榜单的表现更值得拆开来看:
- 数学:第 7
- 专家级应用:第 9
- 软件与 IT:第 9
- 编程:第 10
- 专家竞技场(仅专家级提示):第 9
视觉这边,Qwen3.7-Plus-Preview 综合排名第 16 位,把通义千问在视觉榜的实验室排名抬到了第 5。
这是一组什么样的成绩?坦白讲,不算炸场,但也绝不弱。要知道 Arena AI 现在的头部位置基本被 GPT、Claude、Gemini 几家瓜分,前 10 几乎是死磕。Qwen3.7-Max-Preview 能在文本综合榜挤进前 13,并且在数学、编程、专家应用这些 "硬科目" 上稳定在前 10,已经说明这一代旗舰至少不是挤牙膏。
更值得注意的是 "专家竞技场" 第 9 这个名次。这个子榜单只统计专家级提示词,背后多是真实开发者、研究者抛出的复杂问题——能在这里冲到前 10,意味着模型在长链路推理、复杂任务拆解上确实有真东西。
Preview 版的克制:只开思考模式,工具全关
两个 Preview 版本都做了同样的功能裁剪:
- 仅支持思考模式(Thinking Mode)
- 搜索工具不可用
- 代码解释器不可用
这种取舍其实挺典型。Preview 阶段把模型本体单独拎出来跑榜单,剥掉所有外挂工具,是为了让评测分数干净——不会出现 "模型不行但搜索来救场" 的情况。Arena AI 的盲测机制下,工具调用反而会引入噪声,关掉是更诚实的选择。
至于只开思考模式,参考 Qwen3.5 系列的设计思路,正式版大概率会延续 "思考 / 非思考双模融合" 的架构。Plus 系列在过去几代里一直是 "效果、速度、成本均衡" 的中端旗舰,Max 系列则负责打榜和复杂任务。这一代延续这个分工没什么悬念。
从 3.6 到 3.7:迭代节奏快到反常
值得说一句的是迭代节奏。阿里云今年的更新密度肉眼可见地变快了:
- Qwen3.5 系列上线时强调长上下文(最高 100 万 tokens)和多模态融合
- Qwen3.6-Max-Preview 主打 "更强的世界知识、指令遵循、Agentic Coding"
- Qwen3.6-Plus 升级 Vibe Coding,多模态识别更强
- 现在 Qwen3.7 双 Preview 直接登场
大版本之间的间隔从过去的几个月压缩到了几周。这背后一方面是底座训练管线确实成熟了,另一方面也是被竞争逼的——Anthropic、Google、OpenAI 的迭代节奏没有一家是慢的,国产阵营里 DeepSeek V4 已经发到 Pro 和 Flash 双版本,Qwen 不快不行。
从公开信息看,Qwen3.7 这一代的重点很可能继续押在三个方向:
- Agentic Coding:从 3.6 开始这就是 Qwen 的发力点,编程榜第 10 的成绩说明确实在持续投入
- 数学与推理:数学子榜第 7 是这次成绩单里最亮眼的一项
- 多模态:Plus-Preview 在视觉榜的表现表明 VL 能力没有掉队
为什么这次发布值得开发者关注
说句实话,对一线开发者而言,Arena AI 的排名只是参考。真正决定一个模型能不能进生产的,是几件事:
第一,价格。 Qwen3.6-Max-Preview 的阶梯定价是输入 915 元 / 百万 tokens、输出 5490 元 / 百万 tokens。如果 3.7 正式版能维持这个价格段,对国产模型而言性价比仍然能打。对比 GPT 和 Claude 的旗舰价格,Qwen-Max 一直是 "够用且便宜" 的代表。
第二,上下文。 Qwen3.5-Plus 已经做到了 100 万 tokens 上下文,Max 系列稳在 26 万。3.7 这一代如果能把 Max 的上下文也推到百万级,长文档、代码仓库分析的场景会舒服很多。
第三,Agent 能力。 现在大家做 Agent 应用,最痛的不是模型不会推理,而是工具调用不稳、长链路任务容易跑偏。Qwen3.6 已经在 Agentic Coding 上花了大力气,3.7 如果能把这块继续做扎实,对国内做 Coding Agent、自动化工作流的团队是直接利好。
5 月 20 日峰会前瞻
按惯例,明天的阿里云峰会上,Qwen3.7 正式版应该会一口气放出几件东西:
- Qwen3.7-Max 正式版(开放思考 / 非思考双模、搜索、代码解释器全功能)
- Qwen3.7-Plus 正式版(多模态完整能力)
- 大概率还会有 Qwen3.7-Flash,定位低成本高速场景
- 配套的 API 定价、上下文规格、阶梯计费方案
- 可能伴随 Qwen Chat 的产品形态升级
更值得期待的是开源版本。Qwen 系列一直是国产开源模型里最舍得放权重的,Qwen3、Qwen3.5 都有开源版上 Hugging Face。如果 3.7 这一代延续这个传统,社区生态会再热闹一轮。
顺带提一句,OpenAI Hub 已经在准备接入 Qwen3.7 系列。正式版上线后,开发者可以用同一个 Key 在 GPT、Claude、Gemini、DeepSeek、Qwen 之间自由切换,做模型对比和路由策略时会省不少事——尤其对那些已经在跑多模型 A/B 测试的团队。
写在最后
国产大模型这场仗打到 2026 年,已经不是 "能不能做出来" 的问题,而是 "迭代节奏跟不跟得上" 的问题。Qwen 这两年的策略很清晰:榜单先上、产品后发、价格压低、开源跟进。这套打法在 3.7 这一代依然在执行。
排名第 13 不是终点,明天的正式版才是。如果 Qwen3.7 正式版能在工具调用打开后把综合排名再往上推一截,国产旗舰阵营今年的格局会被重新搅动一次。
参考来源
- IT之家:阿里云千问大模型 Qwen3.7-Max-Preview 首发亮相 Arena AI — 首发报道,含 Arena AI 榜单详细排名数据
- 知乎专栏:国产AI新王登基!Qwen3.6-Max-Preview亮相 — 上一代 Qwen3.6-Max-Preview 的详细解读,可作为对比参考