腾讯云DataBuddy:一句话跑完数据全流程
腾讯云正式发布大数据智能体工作台DataBuddy,这是一款基于WorkBuddy同源Agent底层能力打造的大数据原生智能体工作台。用户通过自然语言对话,即可完成数据接入、开发、治理、分析全链路任务,不用再在多个页面之间切换操作。
这个产品的核心价值很直接:把原本需要数小时甚至数周的数据需求响应,压缩到秒级。腾讯内部实践数据显示,获数延迟降低了90%。
解决的真问题:数据需求响应太慢
企业数据应用的"最后一公里"一直是个老大难问题。传统流程是这样的:业务人员提需求 → 数据部门排期 → 开发报表 → 交付使用。这个链路平均耗时数小时到数周,业务人员面临三大瓶颈:
- 数据获取门槛高:需要懂SQL、懂数据模型,基层业务人员根本用不起来
- 分析效率低:每次需求都要走一遍完整流程,临时性分析需求响应不过来
- 强依赖技术团队:数据部门成为瓶颈,业务决策滞后于市场变化
定制式BI和自助式BI都没能彻底解决这个问题。前者灵活性差,后者学习成本高,业务与技术的割裂始终存在。
DataBuddy的思路是用Agent把整个流程串起来。你说一句"分析近6个月产业树大类毛利趋势",系统自动生成SQL、渲染图表、归因异常波动,甚至一键导出Word/PDF分析报告。决策链路从"看数"升级为"懂数"。

技术架构:NL2DSL + DeepSeek-R1深度推理
DataBuddy的核心能力是自然语言理解(NL2DSL),这是数据分析3.0时代的标志性技术。系统提供从数据接入、模型分析到可视化呈现的全流程能力,关键在于几个技术点:
1. 语义理解与意图澄清
接入DeepSeek-R1大模型后,Agent的语义理解和逻辑推理过程更加透明。模型可以展示详细的思考过程链,有效解决用户模糊提问的意图澄清问题。
比如用户问"最近销售怎么样",系统会推理:
- "最近"指的是最近7天、30天还是本季度?
- "销售"是指销售额、销售量还是增长率?
- 需要按地区、产品还是渠道维度拆解?
系统会主动反问确认,而不是瞎猜一个结果。
2. 统一语义层 + NL2SQL优化
结合腾讯云WeData的统一语义层,DataBuddy在生成SQL时能减少大模型幻觉,降低30%的Token消耗。统一语义层相当于给大模型提供了一份"数据字典",明确告诉它每个指标的定义、计算逻辑、数据来源,避免生成错误的查询语句。
3. 多端适配与移动化
系统提供完善的多端适配(移动端、PC端、系统嵌入端)。腾讯内部已经实现基层业务人员和管理者通过移动端随时随地唤起对话问数,不再局限于办公室。这对快速决策场景特别有用,比如销售在客户现场需要临时调数据,直接手机上问一句就能拿到结果。
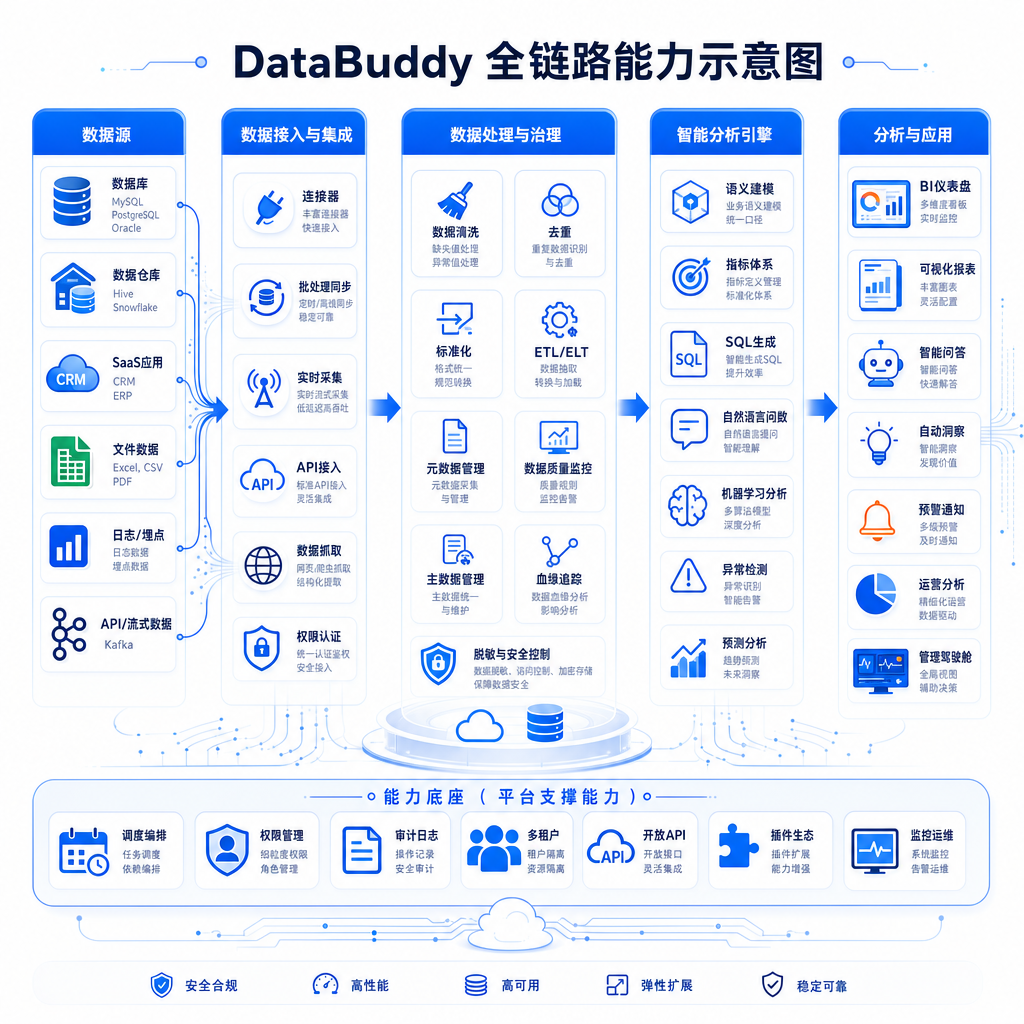
全链路能力:接入→开发→治理→分析
DataBuddy覆盖的不只是查询分析,而是大数据全链路:
数据接入
自然语言描述数据源和接入规则,Agent自动配置连接器、设置同步策略。比如"每天凌晨2点同步MySQL订单表的增量数据到数据湖",系统自动完成配置。
数据开发
用自然语言描述数据处理逻辑,Agent生成ETL任务。比如"把订单表和用户表关联,计算每个用户的累计消费金额",系统生成对应的数据流任务并调度执行。
数据治理
自动识别数据质量问题、重复数据、异常值,并提供修复建议。比如发现某个字段空值率突然上升,系统会主动告警并分析可能的原因。
数据分析
这是最直接的应用场景。用户提问,系统生成SQL、渲染图表、归因分析、生成报告,一气呵成。
实际效果:大幅降低数据部门工作量
腾讯内部落地后,最明显的变化是数据部门底层报表的开发工作量大幅下降。原本需要人工开发的常规报表,现在业务人员自己就能通过对话生成。数据团队可以把精力集中在更复杂的数据建模和算法优化上。
具体数据:
- 获数延迟降低90%:从数小时到秒级响应
- Token消耗降低30%:通过统一语义层优化
- 问题排查时间缩短:从数小时到30分钟(配合智能运维Agent)
目前这套能力已经向金融、零售(圣牧乳业、花王)、工业等多个行业客户横向赋能。
背后的产品矩阵:Data+AI一体化
DataBuddy不是孤立的产品,而是腾讯云大数据Data+AI能力体系的一部分。这个体系在2025年9月的腾讯全球数字生态大会上正式发布,覆盖底层架构、数据平台、数据应用全流程。
底层架构:DIaaS理念
腾讯云提出**DIaaS(数据智能即服务)**理念,打造多模态智能数据湖TCLake,结合流湖引擎和企业级搜索ES。在10亿规模向量场景下实现毫秒级响应,查询性能提升10倍,存储节省高达90%。
这个架构的关键是多模态数据处理。传统数据平台主要处理结构化数据,但企业实际场景中有大量非结构化数据(文档、图片、音视频)。TCLake支持文本与向量的混合检索,并引入AutoRAG一键化生成方案,为知识库构建提供基础能力。
平台层:WeData升级
腾讯云WeData升级为端到端的一体化Data+AI平台,打通数据接入、治理、建模、训练到推理全链路,统一管理多模态数据、模型和指标资产。这是从DataOps到AIOps的融合。
应用层:Agent矩阵
除了DataBuddy这样的分析Agent,腾讯云还推出了运维场景的智能Agent体系,包括:
- 自主调优Agent:降低资源成本15%
- 自主运维Agent:问题排查时间从数小时缩短至30分钟
- 预测治理Agent:事前预警和自动化处置
腾讯云副总裁黄世飞表示,未来的数据平台将由更多Agent驱动,成为新一代智能化基础设施。腾讯云已在腾讯云智能体开发平台上推出TCDataAgent等产品,计划通过开放生态与合作伙伴共同构建覆盖运维、分析等场景的Agent矩阵。
行业趋势:数据平台的普惠化
DataBuddy的发布反映了一个更大的趋势:数据平台的普惠化。通过自然语言接口降低使用门槛,使数据智能成为企业如水电气般的基础设施。
这个趋势的背后是算力成本的下降和开源大模型的普及。数据逐渐成为企业智能化发展的关键差异化因素。传统数据平台在多模态数据处理、实时性、知识库构建等方面的不足越来越明显,Data+AI一体化成为必然方向。
腾讯云提出的"AI-Ready"智能大数据平台,通过云原生架构、Data+AI一体化和Agent增强,为企业提供面向未来的数据底座。这不是简单的功能堆砌,而是从底层架构到应用层的系统性重构。
竞争格局:大厂都在做Agent
数据分析Agent不是新概念,但真正能跑通全链路的产品不多。国内外大厂都在布局:
- 国外:Snowflake的Copilot、Databricks的AI Assistant、Google的Duet AI for BigQuery
- 国内:阿里云的DataWorks AI助手、华为云的DataArts Studio智能助手
腾讯云DataBuddy的差异化在于:
- 全链路覆盖:不只是查询分析,而是接入→开发→治理→分析全流程
- 深度推理:接入DeepSeek-R1,思考过程透明可解释
- 内部验证:腾讯内部大规模落地,数据真实可信
但也要看到,这类产品的核心挑战不在技术,而在数据治理的成熟度。如果企业的数据质量差、指标定义混乱、权限管理不清晰,再智能的Agent也无法发挥作用。DataBuddy更适合数据治理已经有一定基础的企业,而不是从零开始的小公司。
未来方向:从工具到生态
腾讯云的规划是通过开放生态与合作伙伴共同构建Agent矩阵。这意味着DataBuddy不会是一个封闭的产品,而是一个可扩展的平台。
可以预见的方向包括:
- 垂直行业Agent:针对金融、零售、制造等行业的专用Agent
- 场景化Agent:营销分析、风控分析、供应链分析等场景的定制Agent
- 开发者生态:允许企业基于DataBuddy开发自己的Agent
这个思路和OpenAI的GPTs、Anthropic的Claude Projects类似,都是从单一工具向平台生态演进。
对于开发者来说,这类产品的出现意味着数据分析的门槛进一步降低,但也对数据工程师提出了新要求:不再是写SQL和开发报表,而是设计数据架构、优化语义层、训练和调优Agent。技能要求从执行层上升到架构层。
参考来源
- 腾讯云发布大数据Agent工作台DataBuddy - 36氪 - 产品发布官方消息
- 腾讯云大数据TC Data Agent 智能体发布与应用实战 - 知乎 - 技术架构与应用实践详解