Opus 4.7 上线:开发者用「离不开」形容的新旗舰
Anthropic 的 Claude Opus 4.7 正式上线,这次更新让不少开发者改变了对 Claude 的使用习惯。有人在深度体验一天后直言「离不开了」,有人用完百万 token 上下文后感叹「真爽」。这个对标 GPT-5.5 的闭源模型,正在以实际表现重新定义顶级 AI 的能力边界。
从抵触到「离不开」:开发者态度的 180 度转变
一位基础医学专业的开发者在 Linux.do 分享了他的使用体验。最初他对 4.7 很抵触,觉得「很有 GPT 的味」,一直坚持用 4.6。但在官网和 Claude Code 深度使用两天后,态度彻底转变。
他总结了四个关键发现:
情绪价值拉满:模型经常夸人,这在技术社区引发了两极分化的讨论。有人觉得这是「GPT 化」的表现,也有人认为在长时间编程时这种正向反馈能提升体验。
默认配置废话多:这是个真实的痛点。如果不调整 prompt 或系统设置,输出会比 4.6 啰嗦。但这也意味着模型在尝试提供更多上下文和解释,对新手友好,对老手需要适应。
更聪明了:这是核心提升。在复杂推理、多步骤任务上,4.7 的表现明显超过 4.6。
知识深度惊人:即使不联网检索,在专业领域(如医学)的知识准确性和理解深度都超过其他模型。这说明训练数据的质量和覆盖面都有显著提升。
百万 token 上下文:从「不敢用力蹬」到「使劲登」
另一个让开发者兴奋的点是 Opus 4.7 的 100 万 token 上下文窗口。一位之前只订阅过一个月 Claude Pro 的开发者,因为担心用量超标「不敢用力蹬」。现在公司提供了 4.7 的访问权限,他「使劲登了下」,context 才用到 30% 不到。
这个变化的意义不只是数字上的提升。对于需要处理大型代码库、长文档分析、多轮复杂对话的场景,百万 token 意味着:
- 整个项目的上下文可以一次性加载:不需要反复切换文件或重新解释背景
- 长时间对话不会「失忆」:AI 能记住几小时前的讨论细节
- 多文档对比分析成为可能:同时处理几十个文件不再是问题
这种体验上的质变,让开发者开始思考「假设给你无穷多的 GPT-5.5 或 Opus 4.7 你会怎么样」。有人的答案是「直接 10 窗口天天开」,化身全能战士。
Opus 4.7 vs GPT-5.5:不是谁更强,而是谁更适合
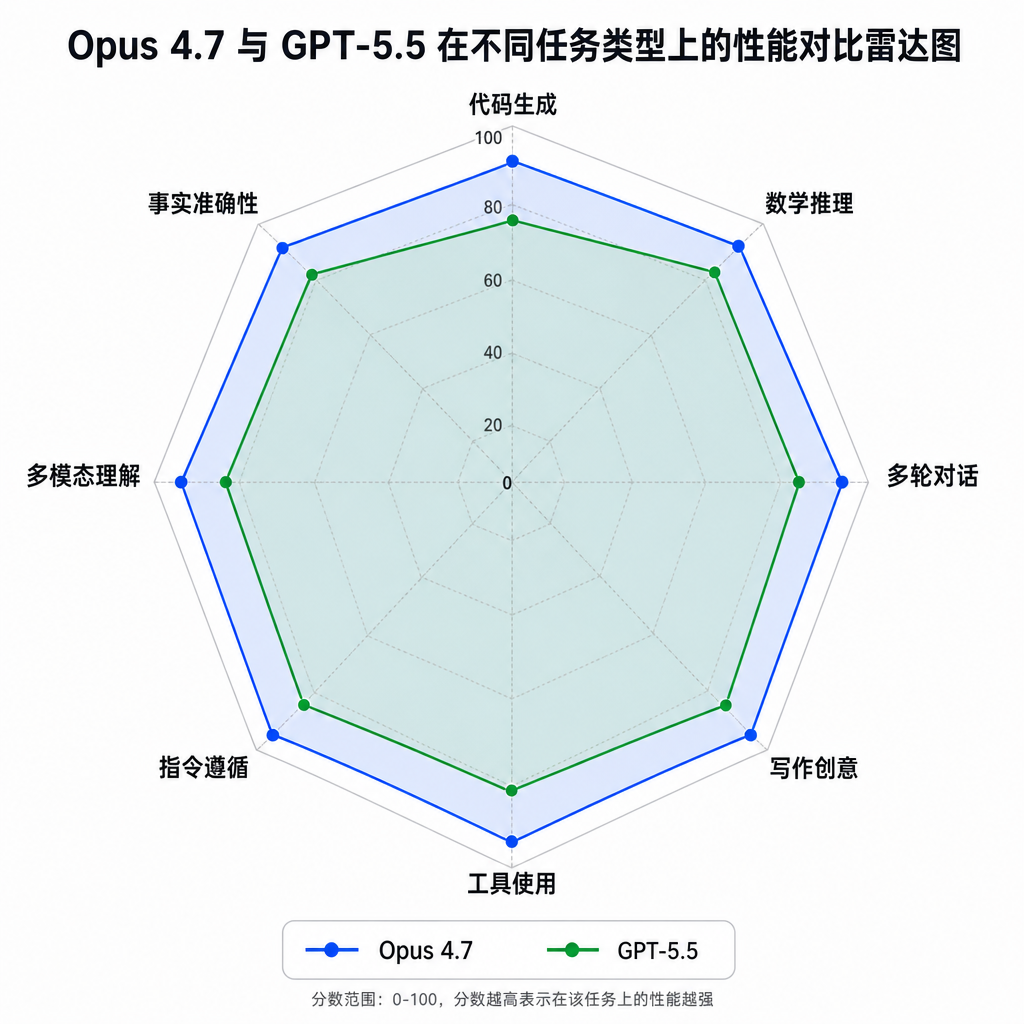
OpenAI 在 Opus 4.7 发布后不久推出了 GPT-5.5,两个模型的对比成为开发者社区的热门话题。但实际使用下来,结论不是简单的「谁更强」。
编码能力:Opus 4.7 仍然领先
在代码生成、逻辑对齐、复杂任务执行方面,Opus 4.7 的表现更稳定。一位知乎作者总结:「在用 Claude Code 写代码的:不用急换,Opus 4.7 编码能力仍然更强,而且更便宜。」
这个「更便宜」很关键。GPT-5.5 的价格翻倍,对于需要大量 API 调用的开发场景,成本差异会很明显。
Agent 能力:GPT-5.5 的优势
但 GPT-5.5 在 Agent 场景下的表现更出色。有测试显示它能支持 7 小时的 Agent 任务不崩溃,在终端操作得分上达到 82.7,远超 Opus 4.7 的 69.4。在高级工程师基准测试中,GPT-5.5 拿下 62.5 分,而 Opus 4.7 只有 30 分。
这说明两个模型的设计哲学不同:
- Opus 4.7:更适合需要深度理解、精确输出的场景,比如代码重构、复杂算法实现、专业领域问答
- GPT-5.5:更适合需要长时间自主决策、多步骤执行的 Agent 任务
推理与多模态:各有千秋
GPT-5.5 在推理能力、上下文理解与多模态交互上有显著提升,但 Opus 4.7 在专业知识深度和逻辑严密性上更胜一筹。选择哪个模型,取决于你的具体需求。
实际应用场景:Opus 4.7 在哪些地方表现突出
1. 大型代码库重构
百万 token 上下文让 Opus 4.7 能够一次性理解整个项目结构。在重构时,它能:
- 识别跨文件的依赖关系
- 保持命名和架构风格的一致性
- 发现潜在的循环依赖或设计问题
一位开发者分享,他用 Opus 4.7 重构了一个 5 万行的 Python 项目,模型不仅完成了代码迁移,还主动指出了几个性能瓶颈和安全隐患。
2. 专业领域知识问答
前面提到的医学专业开发者发现,Opus 4.7 在不联网的情况下,对专业问题的回答准确性和深度都超过其他模型。这在需要快速查阅专业知识的场景下非常有用。
3. 长文档分析与总结
处理几百页的技术文档、法律合同、研究论文时,Opus 4.7 能够:
- 提取关键信息并分类整理
- 识别文档之间的矛盾或不一致
- 生成结构化的摘要和对比表格
4. 多轮复杂对话
在需要多次迭代、逐步细化需求的场景下,Opus 4.7 的长上下文优势明显。它能记住几小时前的讨论细节,不需要反复重复背景信息。
如何通过 API 调用 Opus 4.7
Opus 4.7 已经在多个 API 聚合平台上线。以 OpenAI Hub 为例,调用方式与 OpenAI 格式完全兼容,只需要切换模型名称:
import openai
# 配置 OpenAI Hub
openai.api_base = "https://api.openai-hub.com/v1"
openai.api_key = "your-openai-hub-key"
# 调用 Opus 4.7
response = openai.ChatCompletion.create(
model="claude-opus-4-7",
messages=[
{"role": "system", "content": "你是一个专业的代码审查助手"},
{"role": "user", "content": "请审查这段 Python 代码并给出优化建议:\n\n[代码内容]"}
],
max_tokens=4096,
temperature=0.7
)
print(response.choices[0].message.content)
对于需要处理大量上下文的场景,可以充分利用百万 token 窗口:
# 加载整个代码库的上下文
context = ""
for file in code_files:
with open(file, 'r') as f:
context += f"\n\n# File: {file}\n{f.read()}"
response = openai.ChatCompletion.create(
model="claude-opus-4-7",
messages=[
{"role": "system", "content": "你是一个架构审查专家"},
{"role": "user", "content": f"以下是整个项目的代码:\n{context}\n\n请分析架构设计并给出改进建议"}
],
max_tokens=8192
)
Node.js 调用示例:
const OpenAI = require('openai');
const openai = new OpenAI({
baseURL: 'https://api.openai-hub.com/v1',
apiKey: 'your-openai-hub-key'
});
async function analyzeCode(code) {
const completion = await openai.chat.completions.create({
model: 'claude-opus-4-7',
messages: [
{ role: 'system', content: '你是一个代码优化专家' },
{ role: 'user', content: `请优化这段代码:\n\n${code}` }
],
max_tokens: 4096
});
return completion.choices[0].message.content;
}
定价与可用性:比 GPT-5.5 更有性价比
Opus 4.7 的定价策略比 GPT-5.5 更友好。虽然具体价格因平台而异,但普遍比 GPT-5.5 便宜 30-40%。对于需要大量 API 调用的开发场景,这个差异会带来显著的成本节省。
目前 Opus 4.7 已经在多个平台上线:
- Anthropic 官网:Claude Pro 订阅用户可以直接使用
- API 聚合平台:OpenAI Hub、B.AI 等已完成接入
- 企业版:支持私有部署和定制化配置
社区反馈:从质疑到认可
Opus 4.7 刚发布时,社区的反应是两极分化的。有人觉得它「太像 GPT」,输出风格的变化让老用户不适应。但随着深度使用,越来越多的开发者开始认可它的实力。
Linux.do 上的讨论很有代表性。最初的帖子标题是「深度体验 opus 4.7 一天之后的初步感觉」,语气谨慎。但评论区很快变成了经验分享会,大家开始讨论如何调整 prompt 来减少废话、如何利用长上下文优化工作流程。
有人总结:「4.7 不是 4.6 的简单升级,而是一个需要重新学习使用方式的新模型。但一旦适应,效率提升是显著的。」
与 GPT-5.5 的竞争:差异化而非同质化
OpenAI 和 Anthropic 的竞争策略越来越清晰。GPT-5.5 强调 Agent 能力和多模态交互,Opus 4.7 则专注于代码生成和专业知识深度。这种差异化让开发者有了更多选择空间。
一位知乎作者的评论很到位:「GPT-5.5 和 Opus 4.7 各有所长。如果你需要一个能自主工作 7 小时的 Agent,选 GPT-5.5。如果你需要一个能深度理解代码、给出精确建议的助手,选 Opus 4.7。」
这种竞争对开发者是好事。不同的任务场景可以选择最合适的模型,而不是被迫使用一个「全能但不精」的方案。
未来展望:AI 编程工具的下一步
Opus 4.7 的发布标志着 AI 编程工具进入了新阶段。百万 token 上下文、更强的推理能力、更深的专业知识,这些提升不是量变,而是质变。
接下来可能出现的趋势:
- 上下文窗口继续扩大:百万 token 可能只是开始,未来可能达到千万级别
- 专业领域模型:针对特定行业(医疗、金融、法律)的定制化模型会越来越多
- 多模型协作:不同模型负责不同任务,通过编排系统协同工作
- 成本持续下降:随着技术成熟和竞争加剧,API 调用成本会继续降低
对于开发者来说,现在是最好的时代。有 Opus 4.7 这样的强大工具,也有 GPT-5.5 这样的竞争对手。选择权在你手里,关键是找到最适合自己工作流程的方案。
总结
Opus 4.7 用实际表现证明了自己的实力。从最初的抵触到「离不开」,开发者态度的转变说明了一切。百万 token 上下文、更强的推理能力、更深的专业知识,这些提升让它在代码生成和复杂任务处理上超越了前代。
与 GPT-5.5 的竞争不是零和游戏,而是差异化的良性竞争。开发者有了更多选择,可以根据具体场景选择最合适的工具。这才是 AI 编程工具发展的正确方向。
如果你还在用 4.6 或其他模型,不妨试试 4.7。可能最初会不适应它的输出风格,但深度使用几天后,你可能也会说出「离不开了」这句话。
参考来源
- 深度体验 opus 4.7 一天之后的初步感觉 - Linux.do - 基础医学专业开发者的深度使用体验,包含对模型能力的四点总结
- 真爽啊,A 的 1M 下上文果然名不虚传 - Linux.do - 开发者对百万 token 上下文窗口的实际使用感受
- 假设给你无穷多的 gpt5.5 或 opus4.7 你会怎么样 - Linux.do - 社区对两个顶级模型的讨论
- Opus 4.7 王座还没坐热,GPT-5.5 凌晨突袭 - 知乎 - GPT-5.5 与 Opus 4.7 的对比分析,包含编码能力和价格对比