Agent-Run-Kit:让 AI 智能体像工程师一样交接班
一个开发者刷到视频看到有人让 AI 自动开发了几个小时、提交了几十次 commit 完成了整个项目,于是自己折腾了两周,做出了一套基于 Anthropic 长期运行智能体思路的开源框架 Agent-Run-Kit。这套系统解决的核心问题是:如何让 AI 在跨越多个上下文窗口的长任务中保持连贯性,不会中途断片或降智。
长任务智能体的真实痛点
用过 AI 辅助开发的人都遇到过这些问题:新开对话需要重新给模型喂上下文,或者自己描述一大堆杂乱无章的需求,最后模型产出的效果往往不尽人意。更要命的是执行长任务时的降智——模型要么想"毕其功于一役"导致上下文在中途耗尽,留下一堆未完成且没文档的功能;要么在没充分测试的情况下就标记任务完成,后续智能体只能靠猜,浪费大量时间修复基础功能。
Anthropic 今年 3 月发布的长期运行智能体框架给出了一套解决方案:用初始化智能体负责首轮环境搭建,编码智能体负责在每轮会话中增量推进,并为下个会话留下清晰产物。核心洞察是通过进度文件和 Git 历史,让智能体在开启新窗口时快速理解现状——这种做法借鉴了高效软件工程师的日常实践。
Agent-Run-Kit 就是基于这套思路的工程化实现。
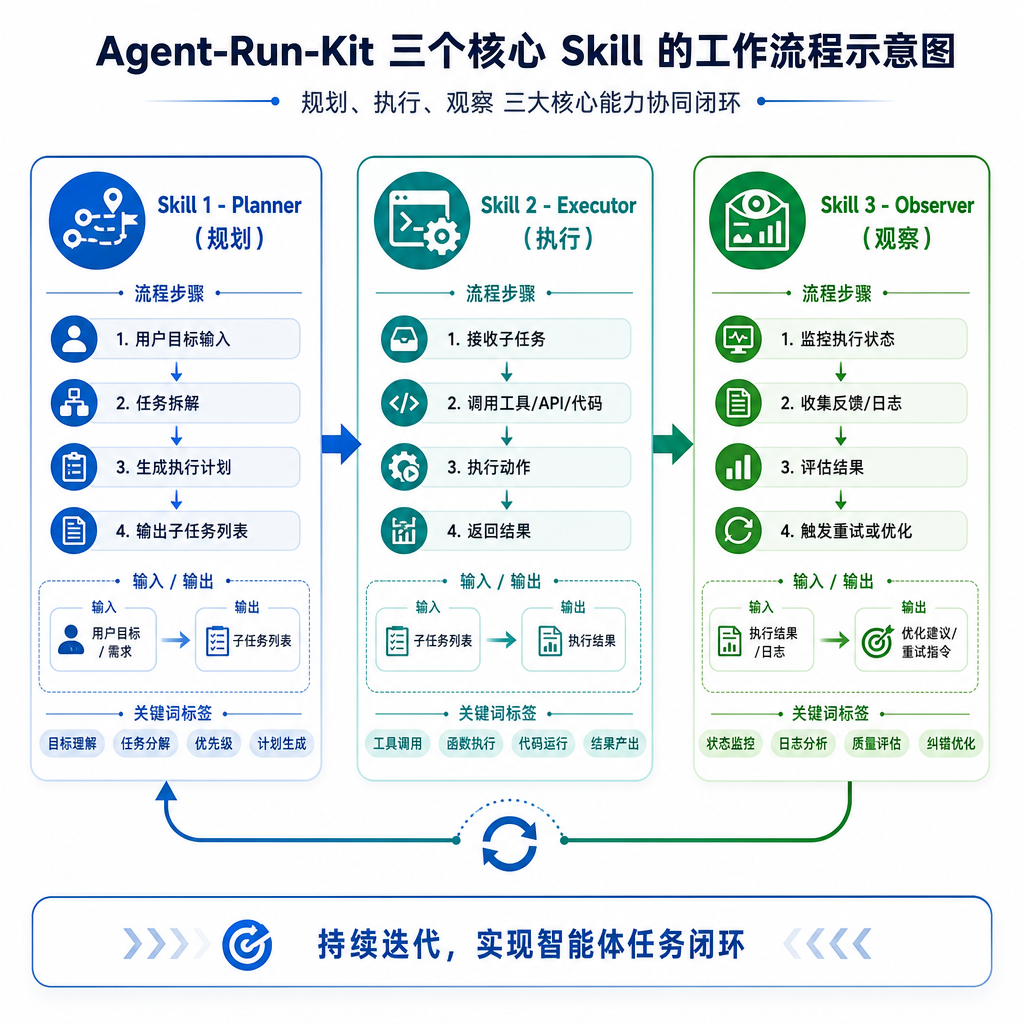
三个 Skill 撑起整个系统
Agent-Run-Kit 的架构非常简洁,本质上就是三个 skill 在干活:
Task_init 负责根据需求拆分成 n 个子任务。这不是简单的任务列表,而是要求智能体根据项目需求编写详尽的功能清单。比如在克隆 claude.ai 的例子中,清单包含 200 多项功能("用户可开启新对话、输入查询、按回车并看到响应"这种粒度),初始状态均标为"失败",为后续开发提供清晰蓝图。
Auto_dev 负责开发。当你执行 $Auto_dev 完成 3 个任务 时,代理会读取任务清单,委派给子代理去干活,等待子代理反馈。关键是它会在会话开始时阅读 Git 日志和进度文件了解近期进展,结束时提交 Git 并更新进度。这确保了每个会话都能立即发现并修复现有 Bug,而不是在错误的基础上开发新功能。
Context_archive 负责压缩代理所需的上下文。代理通过读取工作日志来获取项目近况,当工作日志臃肿时可以使用该 skill 来压缩。这解决了上下文窗口有限的问题,理论上可支持智能体无限期工作。
工程化细节:魔鬼藏在 JSON 和 Git 里
这套系统的稳定性来自几个关键的工程化设计。
首先是用 JSON 而不是 Markdown 管理任务清单。实验证明,使用 JSON 格式比 Markdown 更能防止模型误改文件。系统要求编码智能体仅修改 JSON 文件中的 passes 字段,并严禁删除或编辑测试项。这种约束大幅降低了智能体"自作主张"的概率。
其次是强制要求 Git 提交和进度记录。最佳实践是要求智能体提交 Git(附带描述性信息)并在进度文件中写下总结。这让智能体能利用 Git 回滚错误,恢复至可用状态。初始化智能体会建立初始 Git 仓库和进度记录文件,后续每个编码智能体都必须在开始时阅读进度文件和 Git 日志,结束时提交 Git 并更新进度。
第三是端到端测试的强制要求。若无明确提示,Claude 虽会进行单元测试或 curl 命令,但常忽略端到端的有效性。在构建 Web 应用时,若明确提示使用浏览器自动化工具模拟真实用户操作,Claude 的端到端验证表现优异。系统要求初始化智能体编写 init.sh 脚本来启动服务器并在开发前运行基础测试,确保智能体总是先验证核心流程,而不是在错误的基础上开发新功能。
实际使用流程
准备工作很简单:
- 新建该系统所需的文件(已经在 Agent-Run-Kit 仓库中提供)
- 让 AI 出一份项目落地的详细计划,最好是按阶段规划
- 使用
$Task_init根据计划的阶段规划子任务,例如:$Task_init 根据 xxx 对阶段一进行规划子任务 - 使用
$Auto_dev开始干活,例如:$Auto_dev 完成 3 个任务
这样就可以让代理开始工作,并且稳定性较高。开发者在 Linux.do 社区分享时提到,这套系统经过两周的打磨测试,虽然还有许多不完善的地方,但已经能够稳定运行。
为什么这套方法有效
Agent-Run-Kit 的设计哲学可以总结为一张表:
| 失败模式 | 初始化智能体的应对 | 编码智能体的应对 |
|---|---|---|
| 试图一次完成所有任务 | 根据需求规格,建立包含端到端功能描述的 JSON 清单 | 会话开始时阅读清单,选择单一功能进行开发 |
| 过早宣布项目完工 | 将所有功能初始状态标为"失败" | 仅修改 JSON 文件中的 passes 字段,严禁删除测试项 |
| 环境残留 Bug 或进度记录不明 | 建立初始 Git 仓库和进度记录文件 | 开始时阅读进度文件和 Git 日志,运行基础测试;结束时提交 Git 并更新进度 |
| 浪费时间摸索如何运行应用 | 编写 init.sh 脚本以运行开发服务器 | 会话开始时阅读并执行 init.sh |
| 未充分测试就标记完成 | 要求使用浏览器自动化工具进行端到端测试 | 启动服务器,用 Puppeteer 验证核心流程 |
这种方法的核心是将人类工程师的工作习惯编码到系统中。优秀的工程师会写详细的任务清单、频繁提交 Git、写测试、记录工作日志——Agent-Run-Kit 强制智能体也这么做。
局限与未来方向
当然,挑战依然存在。比如视觉限制和自动化工具的局限——Claude 无法通过 Puppeteer 识别浏览器原生弹窗,导致相关功能更易出错。此外,这套演示主要针对 Web 开发,未来需要探索将其推广至科研、金融建模等其他长程任务领域。
Anthropic 在分享这套方法时提到,这是多个团队(特别是代码强化学习和 Claude Code 团队)的心血结晶。Agent-Run-Kit 作为社区的工程化实现,证明了这套思路的可行性。
从更大的视角看,长期运行智能体框架代表了 AI Agent 发展的一个重要方向:不是让模型变得更聪明,而是让它们能够像人类一样在多个会话中保持连贯性。这需要的不仅是更强的模型能力,更需要合理的工程化设计——外部记忆、任务拆解、进度管理、测试验证,这些都是人类工程师几十年积累下来的最佳实践。
Agent-Run-Kit 目前还处于早期阶段,开发者在社区分享时也坦言"还有许多不完善的地方"。但它提供了一个可运行的起点,让更多开发者能够基于 Anthropic 的思路构建自己的长期运行智能体系统。对于想要让 AI 处理复杂、耗时任务的开发者来说,这是一个值得关注的方向。
如果你也在折腾 AI Agent,不妨看看这套系统的实现。毕竟,让 AI 学会像工程师一样交接班,可能比让它一次性完成所有任务更靠谱。
参考来源
- Agent-Run-Kit GitHub 仓库 - 项目源码和文档
- 基于 Anthropic 长期运行代理思路,我折腾了一套 Agent-Run-Kit - 开发者在 Linux.do 社区的原始分享帖