DeepSeek 修复特殊字符触发异常,官方辟谣隐私泄露
DeepSeek 今天发布官方说明,回应了近期用户反馈的「输入特殊字符后模型返回异常内容」问题。这个看起来像是「对话泄露」的 bug,实际上是模型幻觉,不涉及安全问题或隐私泄露。
问题是怎么发现的
最近几天,有用户在使用 DeepSeek 网页端时发现,输入 <think> 这类特殊字符后,模型会突然输出一堆跟当前对话完全不相关的内容——数学题、物理公式、线性代数推导、甚至命理分析和教育学讨论。这些内容看起来像是从别人的对话里「泄露」出来的,引发了用户对隐私安全的担忧。
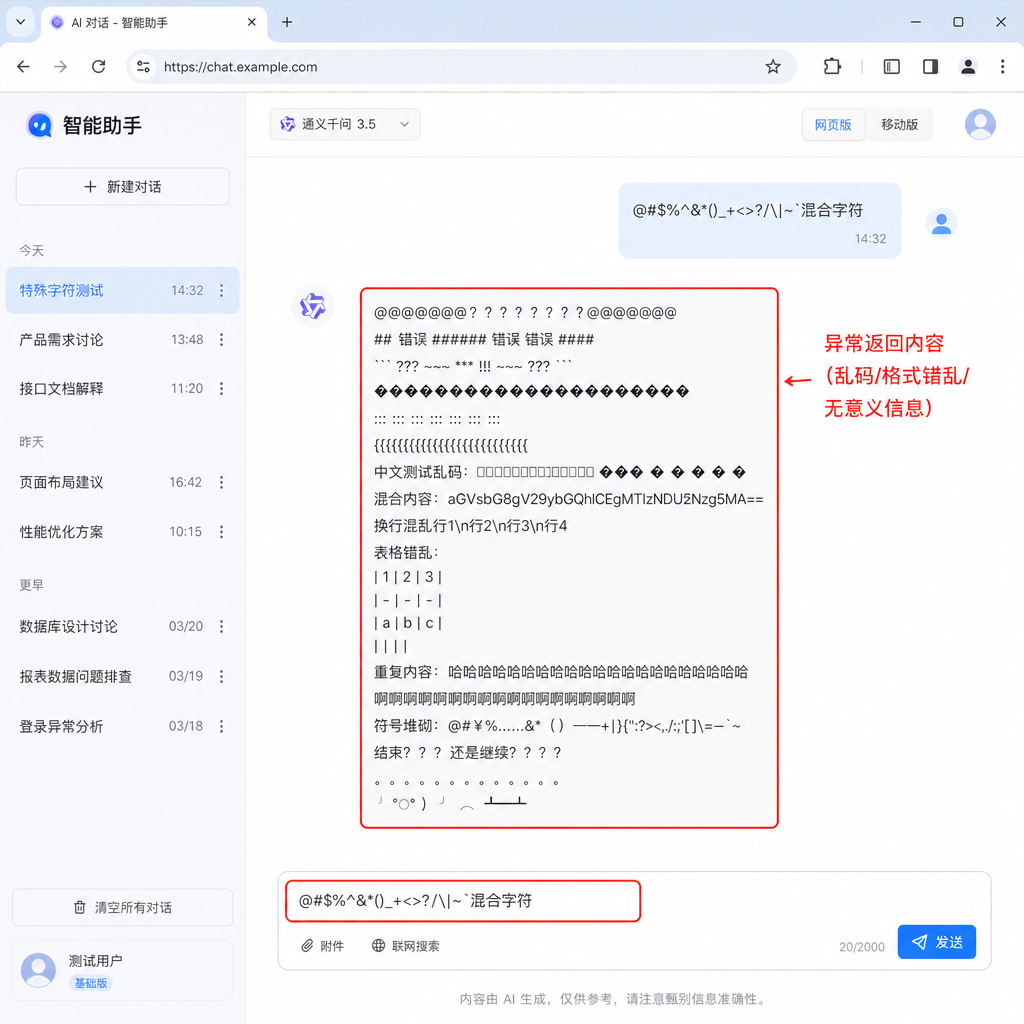
有用户在 Linux.do 等社区发帖讨论,怀疑是不是 DeepSeek 的多租户隔离出了问题,导致不同用户的对话内容串了。这个猜测听起来挺吓人——如果真是这样,那就是严重的安全事故。
DeepSeek 的官方解释
DeepSeek 技术团队排查后给出了明确结论:这是特殊字符引发的模型幻觉,不是安全漏洞,更不是隐私泄露。
什么叫「特殊字符引发的模型幻觉」?简单说,<think> 这类字符在 DeepSeek 的训练数据或系统提示词里可能有特殊含义。当用户直接输入这些字符时,模型会误以为这是某种内部指令或标记,然后开始「脑补」一些训练时见过的类似场景——比如推理过程、多轮对话、或者某些特定领域的问答。
这跟 ChatGPT 早期被发现的「DAN 越狱」有点像,但性质不同。DAN 是通过精心设计的提示词绕过模型的安全限制,而 DeepSeek 这次是模型对特殊字符的处理逻辑出了问题,导致输出了不该输出的内容。关键区别在于:这些异常内容不是从其他用户的真实对话里泄露的,而是模型自己「幻觉」出来的。
为什么会出现这种问题
从技术角度看,这个问题暴露了几个层面的设计缺陷:
1. 特殊字符处理不够鲁棒
现代大模型在训练和推理时会用到各种特殊标记(special tokens),比如:
<|im_start|>和<|im_end|>用来标记对话的开始和结束<think>或<reasoning>用来标记模型的内部推理过程<system>用来标记系统提示词
这些标记在正常情况下不会暴露给用户,但如果用户直接输入这些字符,模型可能会把它们当成真正的特殊标记来处理。DeepSeek 显然在输入过滤和字符转义上做得不够严格。
2. 推理过程的可见性控制不足
DeepSeek 的 R1 系列模型主打「长思维链」,会在内部进行大量推理,然后只把最终结果返回给用户。但这次事件说明,某些特殊字符可能会触发模型把内部推理过程直接输出出来。
这不是功能设计的问题——OpenAI 的 o1 系列也有类似的「思考过程」,但 OpenAI 做了更严格的输出控制,确保用户看不到中间过程。DeepSeek 在这方面的工程实现还不够成熟。
3. 训练数据的「污染」
模型输出的那些看起来像「泄露对话」的内容,很可能来自训练数据。如果训练数据里包含了大量带有特殊标记的对话记录(比如从其他 AI 助手的日志里爬取的数据),模型就会学会在看到类似标记时输出类似的内容。
这不是隐私泄露,但确实说明 DeepSeek 的训练数据清洗还有优化空间。
这个问题有多严重
从安全角度看,这不是高危漏洞。DeepSeek 的说明很明确:不涉及安全问题或隐私泄露。用户的真实对话内容没有被泄露给其他用户,多租户隔离也没有被破坏。
但从产品体验角度看,这是个不应该出现的低级错误。一个成熟的 AI 产品应该对用户输入做充分的过滤和转义,确保任何输入都不会触发意外行为。DeepSeek 作为国内头部的开源模型团队,在这种基础工程问题上翻车,多少有点不应该。
对比一下其他主流模型:
- OpenAI 的 GPT 系列:对特殊字符的处理非常严格,即使你输入
<|im_start|>这种内部标记,模型也会把它当成普通文本处理 - Anthropic 的 Claude:同样有完善的输入过滤机制,不会因为特殊字符触发异常行为
- Google 的 Gemini:在这方面也做得比较稳健
DeepSeek 这次的问题,说明国内模型在工程化和安全性上跟国际一线还有差距。
DeepSeek 的修复计划
DeepSeek 在说明中承诺,会通过「针对性训练」增强模型对特殊字符的识别与处理能力,修复相关的已知问题。
具体怎么修?大概率是这几个方向:
1. 输入过滤和转义
在用户输入进入模型之前,先做一轮过滤,把所有可能引发问题的特殊字符转义成普通文本。这是最直接的解决方案,但需要维护一个「危险字符」列表,而且可能会误伤正常输入。
2. 微调模型的特殊字符处理逻辑
通过额外的训练数据,让模型学会正确处理特殊字符。比如在训练数据里加入大量「用户输入特殊字符 → 模型正常回复」的样本,让模型明白这些字符在用户输入里只是普通文本。
3. 强化输出控制
在模型输出之前,再做一轮检查,确保输出内容不包含不该暴露的内部推理过程或训练数据片段。这需要在推理引擎层面做改动,工程量比较大。
从 DeepSeek 的说法来看,他们选择的是第二种方案——「针对性训练」。这个方案比较彻底,但需要时间。短期内,DeepSeek 可能会先上一个临时的输入过滤方案,然后再通过模型更新彻底解决问题。
对开发者的影响
如果你在用 DeepSeek 的 API 做开发,这个问题基本不影响你。因为:
- API 调用不会直接暴露特殊字符:你通过 API 发送的请求会经过 DeepSeek 的后端处理,不会像网页端那样直接把用户输入传给模型
- 问题主要出现在网页端:目前的报告都集中在 DeepSeek 的网页聊天界面,API 用户还没有反馈类似问题
但如果你在做对话系统或 AI 助手,这个事件提醒你:永远不要信任用户输入。即使你用的是成熟的商业模型,也要在应用层做好输入过滤和输出检查。
行业视角:模型安全还有很长的路要走
DeepSeek 这次的问题,其实是整个 AI 行业都在面对的挑战:如何让模型既强大又安全。
现在的大模型越来越复杂,训练数据越来越多,推理过程越来越不透明。这带来了很多新的安全风险:
- 提示词注入:攻击者通过精心设计的输入,让模型执行非预期的操作
- 数据泄露:模型可能会「记住」训练数据里的敏感信息,并在某些情况下泄露出来
- 对抗样本:特定的输入可能会让模型输出完全错误的结果
- 幻觉问题:模型会「编造」看起来很真实但完全错误的信息
DeepSeek 这次遇到的是「特殊字符触发幻觉」,本质上是对抗样本和幻觉问题的结合。这类问题很难通过传统的测试手段发现,因为攻击面太大了——谁能想到输入一个 <think> 就能让模型「发疯」?
国际上,OpenAI、Anthropic、Google 都在投入大量资源做模型安全研究。OpenAI 有专门的「红队」(Red Team) 来测试模型的安全性,Anthropic 提出了「Constitutional AI」来让模型更可控。国内的模型团队在这方面还需要加大投入。
用户应该怎么办
如果你是 DeepSeek 的用户,现在不用太担心。官方已经明确这不是安全问题,你的对话内容不会泄露给其他人。
但如果你在用 DeepSeek 处理敏感信息(比如公司内部文档、个人隐私数据),建议:
- 等官方修复后再继续使用:虽然不是安全漏洞,但异常行为总归不是好事
- 不要在输入里包含特殊字符:尤其是
<think>、<system>这类看起来像标记的字符 - 定期检查对话历史:确保没有出现异常内容
如果你是开发者,可以考虑切换到其他模型,或者在 OpenAI Hub 这类聚合平台上同时接入多个模型,做好备份方案。
总结
DeepSeek 这次的问题不算大,但暴露了国内模型在工程化和安全性上的短板。好在官方反应及时,承认问题并给出了修复计划。
对整个行业来说,这是个提醒:模型能力的提升不能以牺牲安全性为代价。用户对 AI 的信任是建立在「它不会出意外」的基础上的。一个小小的特殊字符就能让模型「发疯」,这种事情多了,用户自然会用脚投票。
DeepSeek 作为国内开源模型的标杆,希望能在这次事件后把安全测试和工程质量提升到新的高度。毕竟,开源不是低质量的借口,用户体验和安全性应该是所有 AI 产品的基本线。
参考来源
- DeepSeek辟谣隐私泄露 - Linux.do - 用户社区讨论和官方说明原文
- 今日DeepSeek 就" 字符触发模型异常回复"发布说明 - Linux.do - 技术社区对问题的分析和讨论