ChromaDB 爆出预认证代码执行漏洞:AI 向量数据库安全拉响警报
开源向量数据库 ChromaDB 被曝存在严重的预认证代码注入漏洞(CVE-2026-45829)。攻击者无需任何身份验证,就能通过特定 API 端点在服务器上执行任意代码。这个漏洞影响 ChromaDB Python 项目 1.0.0 及更高的所有版本,对大量依赖该数据库的 AI 应用构成直接威胁。
漏洞细节:trust_remote_code 成突破口
这次漏洞的核心在于 ChromaDB 的 /api/v2/tenants/{tenant}/databases/{db}/collections 端点。攻击者可以通过发送恶意的模型存储库路径,并将 trust_remote_code 参数设置为 true,触发服务器执行任意 Python 代码。
具体攻击流程是这样的:
- 攻击者构造一个包含恶意代码的"模型存储库"
- 通过 API 请求将这个恶意存储库路径发送到 ChromaDB 服务器
- 利用
trust_remote_code=true参数,让服务器信任并加载远程代码 - 恶意代码在服务器端执行,攻击者获得完整控制权
这个漏洞最危险的地方在于"预认证"——攻击者不需要任何凭证就能发起攻击。对于那些将 ChromaDB 直接暴露在公网的服务来说,这基本等于把后门钥匙挂在门外。
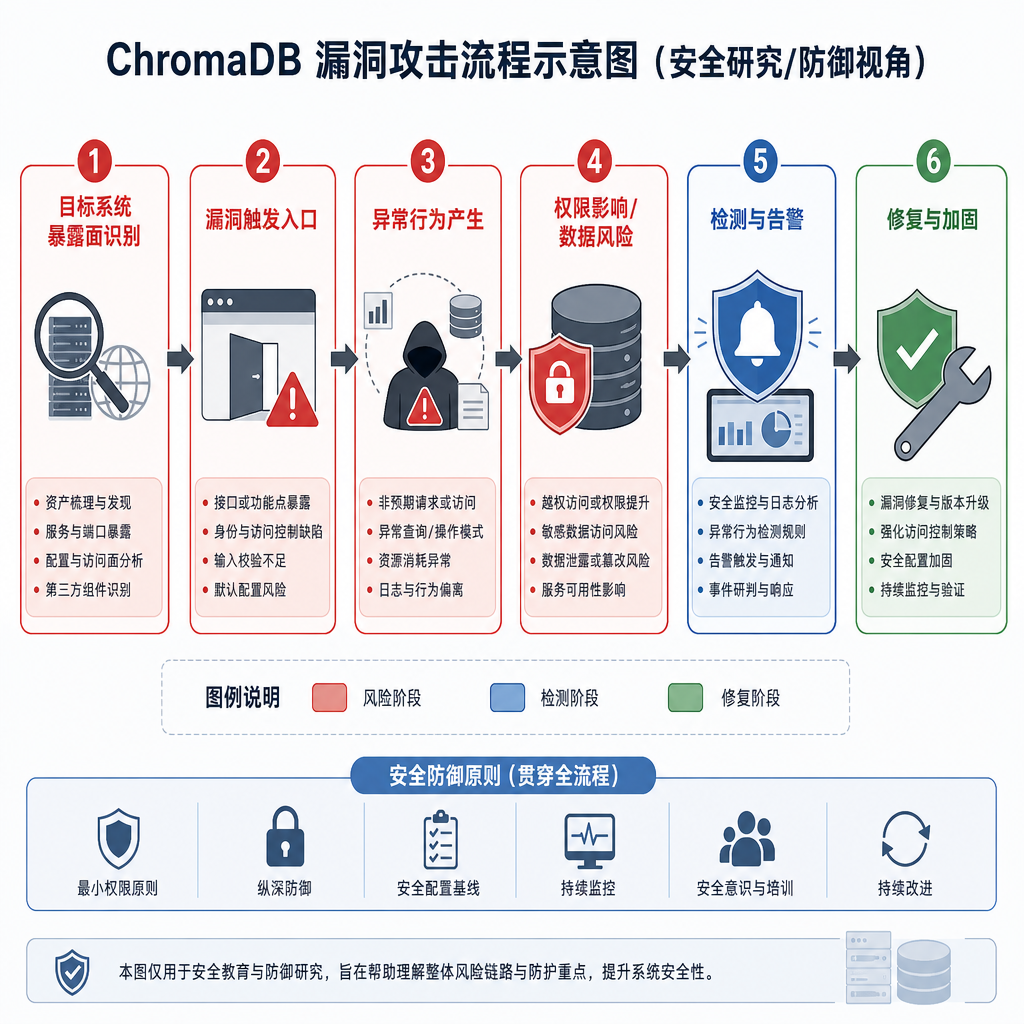
影响范围:不只是数据库的问题
ChromaDB 是目前最流行的开源向量数据库之一,专为 LLM 应用设计。它的典型使用场景包括:
- RAG(检索增强生成)系统:存储文档向量,为 GPT、Claude 等模型提供上下文
- 语义搜索引擎:基于向量相似度的智能搜索
- 推荐系统:通过嵌入向量计算内容相似性
- AI Agent 的记忆层:存储对话历史和知识库
这意味着漏洞的影响不仅限于数据库本身。一旦 ChromaDB 被攻破,攻击者可以:
- 窃取存储在向量数据库中的敏感文档和知识库
- 篡改向量数据,污染 AI 模型的检索结果
- 利用服务器作为跳板,攻击内网其他系统
- 植入后门,长期控制 AI 应用的数据流
根据 FOFA 的全网资产扫描,目前有相当数量的 ChromaDB 实例暴露在公网上。虽然具体数字未公开,但考虑到 ChromaDB 在 AI 开发社区的普及度,受影响的系统数量不会少。
为什么 trust_remote_code 这么危险
trust_remote_code 这个参数在 AI 生态里并不陌生。Hugging Face 的 Transformers 库、LangChain 等工具都有类似的机制。它的设计初衷是让开发者能够加载自定义模型代码,提高灵活性。
但这个便利性是有代价的。当你设置 trust_remote_code=true 时,本质上是在说:"我信任这个远程仓库里的所有代码,可以在我的环境里执行。"如果这个信任被滥用,后果就是任意代码执行。
ChromaDB 的问题在于,它在一个不应该信任用户输入的地方,给了用户控制 trust_remote_code 的能力。这就像在公共 API 上开了一个"执行任意代码"的开关,还不需要密码。
类似的安全问题在 AI 工具链里并不罕见:
- Pickle 反序列化:PyTorch、TensorFlow 的模型文件可以包含任意 Python 对象,加载时会执行代码
- YAML 解析:某些 YAML 库允许执行 Python 代码,配置文件变成攻击入口
- 插件系统:LangChain、AutoGPT 等框架的插件机制,如果没有沙箱隔离,同样存在代码执行风险
AI 开发工具为了灵活性,往往会在安全性上做妥协。这次 ChromaDB 的漏洞再次证明,这种妥协的代价可能很高。
修复建议:不只是打补丁
官方已经在 GitHub issue #6717 中确认了这个漏洞,并发布了修复版本。如果你正在使用 ChromaDB,应该立即采取以下措施:
短期应急
- 升级到最新版本:检查 ChromaDB 的官方发布页,安装包含安全修复的版本
- 限制网络访问:如果 ChromaDB 不需要公网访问,立即配置防火墙规则,只允许内网访问
- 审查访问日志:检查
/api/v2/tenants/端点的访问记录,寻找异常请求 - 禁用 trust_remote_code:如果你的应用不需要加载远程模型代码,在配置中明确禁用这个功能
长期加固
这次漏洞暴露的不只是 ChromaDB 的问题,而是整个 AI 基础设施的安全盲区。以下是一些更系统的防护建议:
网络隔离:向量数据库不应该直接暴露在公网。标准做法是:
- 将 ChromaDB 部署在私有网络
- 通过 API Gateway 或反向代理控制访问
- 使用 VPN 或专线连接开发环境
最小权限原则:
- ChromaDB 进程不应该以 root 权限运行
- 使用容器或虚拟机隔离数据库服务
- 限制数据库进程的文件系统访问权限
输入验证:
- 对所有 API 输入进行严格校验
- 使用白名单机制,只允许已知的模型存储库路径
- 禁止用户控制
trust_remote_code等危险参数
监控和审计:
- 记录所有 API 调用,特别是涉及模型加载的操作
- 设置异常检测规则,识别可疑的访问模式
- 定期审查数据库配置和权限设置
依赖管理:
- 使用依赖扫描工具(如 Snyk、Dependabot)监控已知漏洞
- 及时更新所有依赖库,不只是 ChromaDB 本身
- 在测试环境验证更新,避免引入兼容性问题
AI 基础设施的安全困境
ChromaDB 这次漏洞是 AI 基础设施安全问题的一个缩影。过去几年,AI 开发工具的迭代速度远超传统软件,但安全实践并没有跟上。
向量数据库、模型服务、Agent 框架——这些新兴的 AI 基础设施组件,很多都是在"快速迭代、先上线再说"的思路下开发的。安全性往往是后置的考虑,甚至被当作"优化项"而非"必需项"。
这种现状带来了几个系统性风险:
供应链攻击面扩大:AI 应用依赖大量开源库和预训练模型。每个依赖都是潜在的攻击入口。从 PyTorch 到 Hugging Face,从 LangChain 到 ChromaDB,任何一个环节出问题,都可能影响下游的数千个应用。
默认配置不安全:为了降低使用门槛,很多 AI 工具的默认配置都偏向"开放"而非"安全"。比如不需要认证的 API、默认开启的远程代码执行、缺少加密的数据传输。开发者如果不主动加固,生产环境就是裸奔。
安全工具缺失:传统的安全扫描工具对 AI 特有的风险(模型投毒、提示注入、向量污染)基本无能为力。专门针对 AI 的安全工具还在早期阶段,覆盖面和成熟度都不够。
知识断层:AI 开发者不一定懂安全,安全工程师不一定懂 AI。这种知识断层导致很多风险被忽视。比如这次的 trust_remote_code,对于熟悉 Python 安全的人来说是明显的红旗,但对于专注算法的 AI 工程师可能就是个"方便的功能"。
行业需要做什么
解决这些问题需要整个行业的共同努力:
开源项目方面:
- 建立安全响应机制,及时处理漏洞报告
- 引入安全审计,特别是在发布重大版本前
- 提供安全配置指南,帮助用户正确部署
- 默认采用安全配置,把便利性作为可选项而非默认项
云服务商方面:
- 提供托管的向量数据库服务,内置安全加固
- 在 AI 平台中集成安全扫描和监控
- 为开发者提供安全最佳实践和参考架构
企业用户方面:
- 将 AI 基础设施纳入安全管理体系
- 对 AI 应用进行安全评估和渗透测试
- 培训开发团队,提高安全意识
- 建立应急响应流程,快速处理安全事件
安全社区方面:
- 开发针对 AI 的安全工具和框架
- 建立 AI 安全漏洞数据库和知识库
- 推动 AI 安全标准和最佳实践的制定
ChromaDB 的这次漏洞是一个警钟。随着 AI 应用越来越深入到关键业务,向量数据库、模型服务这些基础设施的安全性不能再是"次要问题"。代码执行漏洞在传统软件里已经是老生常谈,但在 AI 领域,我们还在重复同样的错误。
如果你正在构建 AI 应用,现在就是审视安全架构的好时机。不要等到被攻击了才想起来打补丁。
参考来源
- ChromaDB 代码执行漏洞讨论 - Linux.do - 社区对 CVE-2026-45829 的技术分析和讨论
- ChromaDB GitHub Issue #6717 - 官方漏洞确认和修复进展
- 使用向量数据库 ChromaDB 构建语义搜索应用程序 - 知乎 - ChromaDB 的应用场景和技术背景