通义发布实时翻译模型,体验链接翻车引热议
阿里通义千问团队昨晚推出了翻译模型 Qwen-MT,本该是个值得关注的技术进展,结果官方给出的体验链接全部失效,开发者们连模型长什么样都没看到。有人在 Linux.do 社区直接开喷:"通义好草台啊,给的链接都是错的,都不知道怎么体验。"
这场翻车来得不是时候。就在同一天,字节跳动旗下的火山引擎正式发布了豆包·同声传译模型 Seed LiveInterpret 2.0,不仅技术指标亮眼,体验链接还能正常访问。两相对比,阿里这波操作显得格外尴尬。

链接翻车背后:产品发布流程的失控
从技术角度看,Qwen-MT 本身可能没问题。阿里在机器翻译领域积累不浅,去年云栖大会上推出的端到端语音翻译大模型 Gummy 就展示过不错的实时流式翻译能力。但这次发布出现的低级错误,暴露的是产品发布流程的混乱。
一个正常的模型发布流程应该是这样的:技术团队完成模型训练和测试 → 产品团队搭建体验环境 → 市场团队准备宣发素材 → 多轮内测确认链接可用 → 正式对外发布。但从这次情况看,阿里很可能跳过了最关键的"内测确认"环节,或者测试环境和生产环境没有做好隔离,导致对外链接直接指向了内部测试地址。
这种失误在大厂里其实不罕见。产品经理催进度、技术团队赶工期、测试环节被压缩,最后上线前没人真正从用户视角走一遍完整流程。结果就是,PPT 做得漂亮,demo 视频剪得精彩,但用户点开链接一看——404。
更讽刺的是,通义实验室官网上还挂着"千问大语言模型通过超万亿参数规模预训练具备自然语言理解、文本生成、视觉理解、音频理解、工具使用、角色扮演、AI Agent 互动等多种能力"这样的宣传语。能力再强,用户连门都进不去,有什么用?
豆包同传 2.0:字节在语音赛道的野心
对比之下,字节这边的发布就专业多了。豆包·同声传译模型 Seed LiveInterpret 2.0 不仅技术指标领先,体验流程也很完整。用户可以直接在火山引擎平台上测试中英互译功能,模型会实时克隆用户音色,以极低延迟输出翻译语音。
从技术实现上看,这个模型做的事情比单纯的语音生成复杂得多。它需要同时完成三件事:语音识别(听懂你说的话)、机器翻译(转换成另一种语言)、语音合成(用自然的声音说出来)。而且这三个环节必须是流式处理,不能等你说完一整句话再开始翻译,否则延迟会让对话体验变得很糟糕。
字节在基准测试中给出的数据显示,Seed LiveInterpret 2.0 在中英互译的平均翻译质量人类评分达到 74.8 分(满分 100),这个成绩在同类模型中算是第一梯队。更关键的是,它能根据语境自动判断是否需要重复主语,处理自然语言中的停顿和语病,这些细节决定了翻译听起来是机器腔还是人话。
有开发者测试了一段鲁迅语录:"有一份热,便发一份光""无穷的远方,无数的人们",这种短促的停顿模型都能准确识别。但也有人发现,当输入英文讲座时,音色克隆效果会明显下降,几乎没有相似度。这说明模型在不同语言方向上的表现还不够稳定,技术一致性有待改进。
语音翻译赛道:不只是做个翻译软件
如果只是把 Qwen-MT 和豆包同传当成两个翻译工具来比较,那就看窄了。这波语音翻译模型的升级,核心价值在于"语音交互"能力已经宣告成熟,翻译只是其中一个应用场景。
回顾一下时间线就能看出端倪。字节在 2024 年推出了旗舰语音生成基础模型 Seed-TTS,今年 1 月发布了豆包 Realtime Voice Model(首个端到端语音理解与生成模型),4 月开源了中英双语 TTS 模型 MegaTTS3,一个月前又发布了豆包播客语音模型。这一系列动作,明显是在构建完整的语音能力矩阵。
阿里这边也不甘示弱。去年云栖大会上推出的 Gummy 模型,虽然无法实时语音复刻,但可以实时流式生成语音识别与翻译结果。这次发布 Qwen-MT,应该是想在翻译能力上再进一步。只不过,发布流程的翻车让技术进展被淹没在了吐槽声中。
把视野再打开一点,会发现几乎所有基础大模型厂商都在往语音赛道挤。OpenAI 的高级语音模式、Meta 的 Seamless Streaming(支持近 100 种输入语言和 36 种语音输出语言)、MiniMax 的 Speech-02 模型(单次输入支持 200K 字符,30 多种语言)、科大讯飞的会议耳机和翻译耳机,甚至 Elon Musk 的 xAI 也在 Grok 应用里上线了可互动的 3D 虚拟 AI 少女 Ani。
大家都在抢这个赛道,原因很简单:语音交互是下一代 AI 产品的关键入口。
AI 硬件的救命稻草
单纯文字对话的用户体验每上升 1 分,背后可能是 100 分的模型能力提升,10000 分的算力、算法、架构的投入。这个投入产出比太低了。相比之下,语音交互能带来更自然、更高效的体验,而且有明确的商业化路径——AI 硬件。
从 2023 年开始,各种形态的可穿戴 AI 助手层出不穷。硅谷初创公司 Humane 推出的 AI Pin、Rabbit R1、年收入近 1 亿美金的 AI 录音硬件 Plaude、TicNote,再到字节推出的 Ola Friend 耳机,AI 硬件已经事实上成为了各家厂商将 AI 商业化的"救命稻草"。
为什么是硬件?因为没有键盘的眼镜、耳机,天然适合语音交互这一新形式。而且硬件产品能够激发市场去琢磨还有哪些尚未被发现的隐秘机会。
字节在宣布豆包同传模型 2.0 发布时,同时提到该模型将在 8 月迅速进入 Ola Friend 耳机中。这个动作很明确:语音翻译模型带来的"实时语音交互"体验,正在成为 AI 硬件产品吸引用户的新战场。
阿里这边也在布局。就在 Qwen-MT 发布两天后,阿里在 WAIC 上正式推出了首款 AI 眼镜。字节也被爆将在年内发布自家的 AI 眼镜。国内正在打响的"百镜大战",背后的技术支撑就是实时语音交互能力。
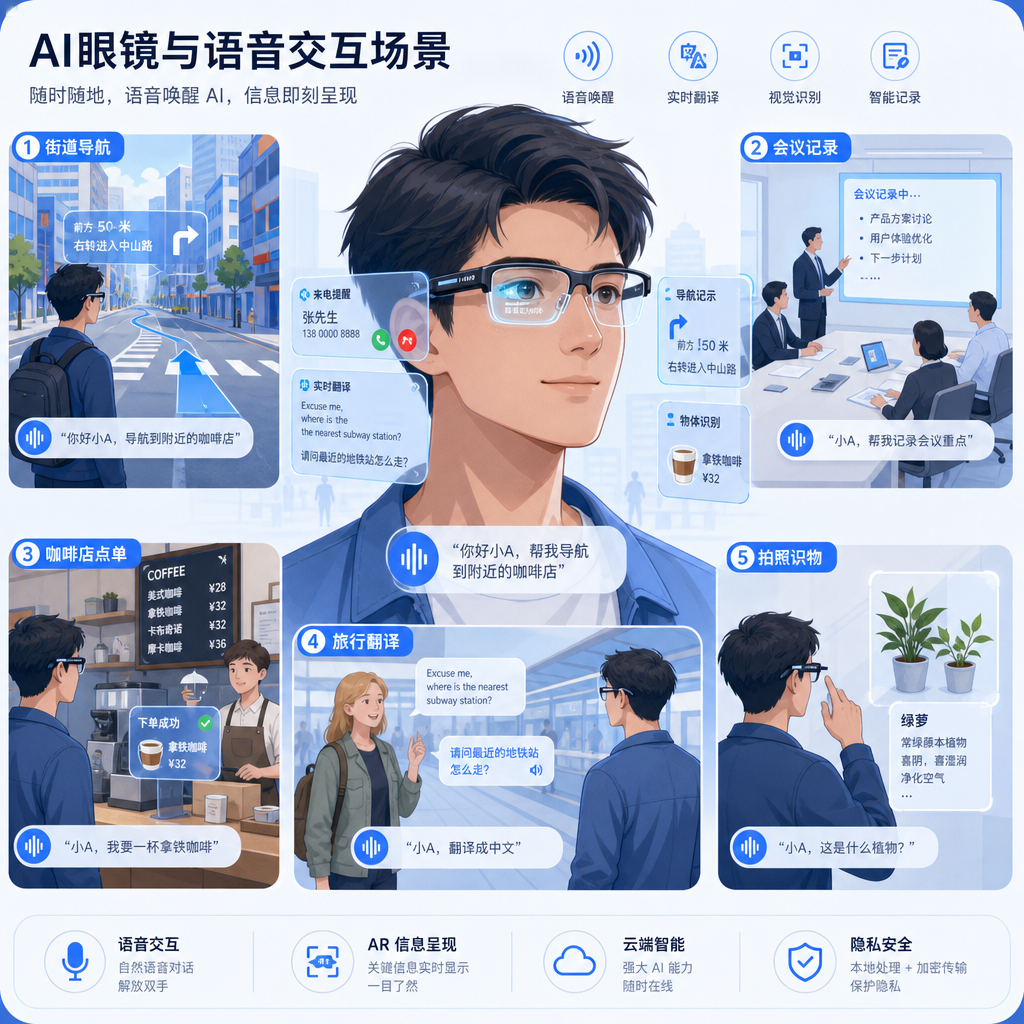
技术成熟度:还有多远?
回到技术本身,目前的语音翻译模型还存在一些明显的局限。
首先是语言覆盖面。豆包同传 2.0 主要聚焦中英文对话,这点上与 Meta 的 Seamless Streaming(支持近 100 种输入语言和 36 种语音输出语言)相比仍有差距。从"语言覆盖面"这个角度,字节确实还有很长的路要走。
其次是音色克隆的一致性。在不同语言方向上,模型的音色克隆表现差异较大。中文转英文时效果还不错,但英文转中文时相似度会明显下降。这说明模型在跨语言场景下的技术一致性还需要改进。
第三是专业词汇的翻译准确度。对于特定领域的术语,模型的翻译准确度还有提升空间。这在会议、学术交流等场景下会成为明显的痛点。
不过,从另一个角度看,这些局限恰恰说明了赛道还有很大的优化空间。谁能率先解决这些问题,谁就能在下一代 AI 产品交互入口的争夺战中占据优势。
商业化困境:光靠模型盈利是做梦
在国外各个主力 AI 模型都已经开始开发不同的收费模式时,反观国内,除了 AI Agent 带来了较为成体系的价格结构之外,AI 基础模型厂商几乎是"一片噤声",无人愿意提及。正如大家常说的:"光靠模型就能盈利,那是做梦"。
这也是为什么大家都在往硬件上挤。硬件有明确的定价模型,用户愿意为体验买单。而且硬件能够锁定用户,形成生态闭环。字节的 Ola Friend 耳机可以通过唤醒词"豆包豆包"激活 AI 聊天助手,这种体验虽然还谈不上颠覆性,但至少是一个可行的商业化路径。
阿里这边的思路可能也类似。AI 眼镜 + Qwen-MT 翻译模型,瞄准的是跨国出海、会议场景等刚需市场。这些场景的商业价值是明确的,用户有付费意愿。
但问题在于,硬件的门槛比软件高得多。供应链管理、品控、售后服务,这些都是互联网公司不擅长的领域。而且硬件市场的竞争已经很激烈了,科大讯飞、华为、小米都在做类似的产品。阿里和字节能不能在这个赛道上跑出来,还是个未知数。
这场翻车的启示
回到最开始的问题:通义这次发布为什么会翻车?
表面上看,是产品发布流程的失控。但往深了说,可能是阿里内部对这个项目的重视程度不够。如果是战略级的产品发布,不可能出现这种低级错误。
更深层的问题是,阿里在 AI 赛道上的节奏有点乱。一会儿推 Gummy,一会儿推 Qwen-MT,一会儿又要做 AI 眼镜,看起来什么都在做,但每个方向都没有做到极致。相比之下,字节的路径就清晰得多:先把语音能力矩阵搭建完整,然后通过硬件产品落地,形成商业闭环。
对于开发者来说,这次翻车也是个提醒:不要迷信大厂的技术实力,产品体验才是王道。模型再先进,用户连门都进不去,有什么用?在选择技术方案时,稳定性、可用性、文档完善度,这些"软实力"往往比模型参数更重要。
语音翻译赛道的竞争才刚刚开始。阿里这次翻车,给了字节一个绝佳的宣传机会。但从长期来看,真正决定胜负的还是技术积累和产品体验。谁能率先解决音色克隆一致性、专业词汇翻译准确度、多语言覆盖面这些核心问题,谁就能在下一代 AI 产品交互入口的争夺战中占据优势。
至于通义的 Qwen-MT,等链接修好了再说吧。
参考来源
- 通义好草台啊,昨晚推出个实时翻译的模型 - Linux.do - 开发者社区对通义发布翻车的讨论
- 豆包上新同声传译,顺便狙击阿里AI眼镜?- 36氪 - 豆包同传模型 2.0 技术解析与行业分析