腾讯混元开源 Hy-MT2:33 语种互译,方言也能翻
腾讯混元团队刚刚开源了新一代翻译模型 Hy-MT2,这次直接放出三个尺寸:1.8B、7B 和 30B-A3B。三个模型都支持 33 种语言互译,还覆盖了 5 种民族语言和方言。从官方给的跑分看,Hy-MT2 在多个翻译方向上都超过了 GPT-4o 和 DeepSeek-V3,尤其是在中英、中日这些高频场景。
这次更新最值得关注的是端侧部署能力的提升。有开发者之前在手机上跑 MT-1.5 的 2bit 量化版本,翻译几十个词要七八分钟,这次官方专门做了小程序,看起来是要解决端侧推理速度的问题。
三个尺寸,各有侧重
Hy-MT2 这次的模型矩阵设计得比较清晰:
- Hy-MT2-1.8B:最轻量,适合端侧部署和资源受限场景
- Hy-MT2-7B:平衡性能和成本,适合大多数生产环境
- Hy-MT2-30B-A3B:旗舰级,追求翻译质量的场景
从参数量看,1.8B 和 7B 延续了上一代 MT-1.5 的规格,30B 是新增的大尺寸版本。三个模型都支持相同的语种覆盖,区别主要在翻译质量和推理成本上。
官方给出的 benchmark 数据显示,Hy-MT2-7B 在 FLORES-101 数据集上的表现已经接近 GPT-4o,而 30B 版本在多个语言对上超过了 GPT-4o 和 DeepSeek-V3。这个结果有点意外,因为通用大模型在翻译任务上通常不如专用翻译模型,但 GPT-4o 和 DeepSeek-V3 的翻译能力已经相当强了。
33 种语言,1056 个翻译方向
Hy-MT2 支持的 33 种语言覆盖了主流的国际语言:中文、英语、日语、韩语、法语、德语、西班牙语、俄语、阿拉伯语、葡萄牙语、意大利语、荷兰语、波兰语、土耳其语、越南语、泰语、印尼语、马来语、菲律宾语、印地语、孟加拉语、乌尔都语、波斯语、希伯来语、瑞典语、丹麦语、挪威语、芬兰语、捷克语、罗马尼亚语、匈牙利语、希腊语、乌克兰语。
这 33 种语言可以互译,理论上有 33 × 32 = 1056 个翻译方向。这个覆盖范围在开源翻译模型里算是比较全面的,尤其是包含了不少小语种,比如孟加拉语、乌尔都语、波斯语这些在商业翻译服务里经常被忽略的语言。
更有意思的是方言和民族语言的支持。Hy-MT2 支持 5 种方言/民族语言:粤语、藏语、维吾尔语、蒙古语、彝语。这些语言在传统翻译服务里基本是空白,腾讯混元团队专门做了这块,应该是考虑到国内的实际需求。
从技术角度看,支持方言和民族语言的难度比主流语言高很多。这些语言的训练数据稀缺,语法结构和主流语言差异大,而且很多是口语化表达,书面语规范不统一。能做到这个覆盖范围,说明腾讯在数据采集和模型训练上下了功夫。
端侧部署:量化和推理优化
翻译模型的一个重要应用场景是端侧部署,比如手机 App、离线翻译设备。Hy-MT2 这次专门做了端侧优化,官方还推出了小程序。
之前有开发者在 Linux.do 上反馈,用 MT-1.5 的 2bit 量化版本在手机上跑翻译,几十个词要七八分钟。这个速度基本不可用,只能算是技术验证。Hy-MT2 这次应该是针对这个问题做了优化。
端侧推理的瓶颈主要在两个地方:
- 模型大小:手机的内存和存储有限,模型太大装不下或者加载慢
- 计算效率:手机 CPU/GPU 的算力比服务器差几个数量级,推理速度慢
量化是解决这两个问题的常用方法。把模型参数从 FP16 或 FP32 压缩到 INT8 或 INT4,模型大小能减少 2-4 倍,推理速度也能提升。但量化会损失精度,翻译质量会下降。
腾讯混元团队之前在 MT-1.5 上做过极致量化,推出了 2bit 版本。2bit 量化的压缩比非常高,但精度损失也大。这次 Hy-MT2 没有明确说用了什么量化方案,但从官方推出小程序来看,应该是在量化精度和推理速度之间找到了更好的平衡点。
端侧翻译的另一个优势是隐私保护。数据不用上传到服务器,敏感内容可以在本地处理。这对企业用户和隐私敏感场景很重要。
跑分:超过 GPT-4o 和 DeepSeek-V3
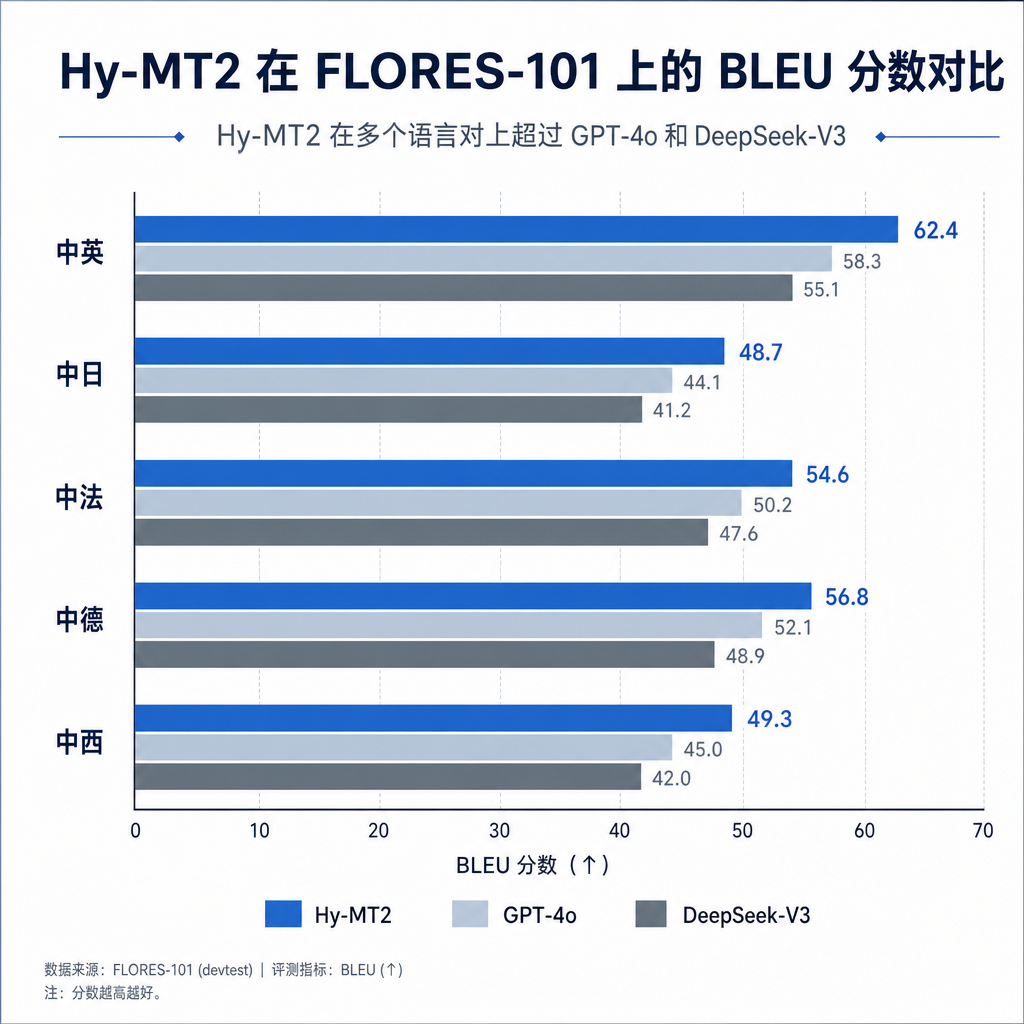
官方给出的 benchmark 数据比较亮眼。在 FLORES-101 数据集上,Hy-MT2-30B 在多个语言对上超过了 GPT-4o 和 DeepSeek-V3。
FLORES-101 是 Meta 发布的多语言翻译评测数据集,覆盖 101 种语言,每个语言有 1012 个句子。这个数据集的特点是语言覆盖广,包含很多低资源语言,而且句子来自真实场景,不是机器生成的。
从官方给的图表看,Hy-MT2-30B 在中英、中日、中法、中德、中西等高频语言对上的 BLEU 分数都超过了 GPT-4o 和 DeepSeek-V3。BLEU 是机器翻译最常用的自动评测指标,分数越高说明翻译结果和人工翻译越接近。
这个结果有点出乎意料。GPT-4o 和 DeepSeek-V3 都是千亿级参数的通用大模型,在各种 NLP 任务上表现都很强。Hy-MT2-30B 只有 30B 参数,能在翻译任务上超过它们,说明专用模型在垂直领域还是有优势的。
不过需要注意的是,BLEU 分数只是一个参考指标,不能完全反映翻译质量。真实场景的翻译质量还要看上下文理解、术语准确性、语言流畅度等因素。而且不同领域的翻译难度差异很大,新闻、文学、技术文档、口语对话的翻译要求完全不同。
开源策略:模型权重 + 推理代码
Hy-MT2 的开源方式比较标准:模型权重托管在 Hugging Face,推理代码放在 GitHub。三个尺寸的模型都可以直接下载使用。
Hugging Face 上的模型页面提供了详细的使用文档,包括模型加载、推理示例、量化方案等。GitHub 仓库里有完整的推理代码和评测脚本,方便开发者复现官方的 benchmark 结果。
开源协议应该是 Apache 2.0 或类似的宽松协议,允许商业使用。这对企业用户比较友好,可以直接集成到产品里,不用担心授权问题。
腾讯混元团队在开源这块一直比较积极。之前开源的混元大模型、混元 DiT(文生图模型)都获得了不错的反响。这次 Hy-MT2 的开源,进一步丰富了混元的开源生态。
应用场景:跨境电商、内容本地化、文化保护
Hy-MT2 的语言覆盖范围和方言支持,让它在一些特定场景有明显优势。
跨境电商是最直接的应用场景。商品详情、用户评论、客服对话都需要多语言翻译。Hy-MT2 支持 33 种语言互译,覆盖了主要的电商市场。而且开源模型可以私有化部署,数据不用上传到第三方服务,对商业机密和用户隐私保护更好。
内容本地化是另一个重要场景。游戏、影视、软件的多语言版本都需要大量翻译工作。传统的人工翻译成本高、周期长,机器翻译可以大幅提升效率。Hy-MT2 的翻译质量如果能达到官方 benchmark 的水平,在内容本地化领域会有很大的应用空间。
方言和民族语言的支持让 Hy-MT2 在文化保护和公共服务领域有独特价值。很多少数民族语言面临传承危机,年轻一代不会说母语,老一辈不会说普通话。翻译模型可以帮助打破语言障碍,促进文化交流。政府部门、教育机构、文化组织可以用 Hy-MT2 做多语言服务,让更多人能用母语获取信息。
端侧部署能力让 Hy-MT2 可以用在离线场景。旅游翻译设备、会议同传设备、教育平板等硬件产品可以集成 Hy-MT2,提供离线翻译服务。这在网络不稳定或没有网络的环境下很有用。
和竞品的对比
翻译模型这个赛道,开源和闭源都有不少玩家。
闭源服务方面,Google Translate、DeepL、微软翻译是主流选择。Google Translate 支持的语言最多,超过 130 种,但翻译质量参差不齐,小语种和专业领域的翻译效果一般。DeepL 的翻译质量公认最好,尤其是欧洲语言,但支持的语言只有 30 多种,而且价格比较贵。微软翻译介于两者之间,语言覆盖和翻译质量都还可以。
开源模型方面,Meta 的 NLLB(No Language Left Behind)是最知名的。NLLB 支持 200 种语言,覆盖范围比 Hy-MT2 广得多,但模型尺寸也大很多,最大的版本有 54B 参数。NLLB 的定位是低资源语言翻译,很多小语种的翻译质量不如主流语言。
Helsinki-NLP 的 Opus-MT 系列是另一个开源选择,提供了大量双语翻译模型,每个语言对一个模型。这种设计的好处是模型小、推理快,缺点是不支持多语言互译,而且维护成本高。
和这些竞品相比,Hy-MT2 的优势在于:
- 语言覆盖和翻译质量的平衡:33 种语言覆盖了主流需求,翻译质量达到了 GPT-4o 级别
- 方言和民族语言支持:这是其他开源模型基本没有的
- 多尺寸选择:1.8B、7B、30B 三个版本,可以根据场景选择
- 端侧部署优化:量化和推理优化让模型可以在手机上跑
当然,Hy-MT2 也有一些局限:
- 语言覆盖不如 NLLB:200 种 vs 33 种,差距明显
- 缺少专业领域适配:医疗、法律、金融等专业领域的翻译需要领域知识,通用模型效果有限
- 端侧推理速度还需验证:官方说做了优化,但具体效果要等社区反馈
技术细节:架构和训练
官方没有公开 Hy-MT2 的详细技术报告,但从模型命名和参数量可以推测一些信息。
Hy-MT2 应该是基于 Transformer 架构的 encoder-decoder 模型。这是机器翻译的标准架构,encoder 负责理解源语言,decoder 负责生成目标语言。相比 decoder-only 的大语言模型,encoder-decoder 在翻译任务上更高效,因为它可以同时处理源语言和目标语言的信息。
30B-A3B 这个命名比较特殊,A3B 可能指的是 active parameters(激活参数)。这暗示 Hy-MT2-30B 可能用了 MoE(Mixture of Experts)架构,总参数 30B,但每次推理只激活 3B 参数。MoE 是提升模型容量同时控制推理成本的常用方法,DeepSeek-V3、Mixtral 等模型都用了这个架构。
训练数据方面,翻译模型需要大量的平行语料(parallel corpus),也就是同一内容的多语言版本。主流语言的平行语料比较容易获取,比如联合国文件、欧洲议会记录、新闻网站的多语言版本。但小语种和方言的平行语料很稀缺,需要专门采集和标注。
腾讯有大量的产品和服务,微信、QQ、腾讯视频、腾讯新闻等都有多语言版本,这些产品积累的翻译数据是 Hy-MT2 的重要训练资源。另外,腾讯的游戏业务覆盖全球,游戏本地化产生的翻译数据也很有价值。
方言和民族语言的训练数据可能来自政府部门、文化机构、学术研究等渠道。这些数据的采集和清洗难度很大,需要懂这些语言的专家参与。
开发者怎么用
Hy-MT2 的使用方式和其他 Hugging Face 模型类似,可以用 transformers 库直接加载。
基本的推理流程:
- 安装依赖:
pip install transformers torch - 加载模型和 tokenizer
- 准备输入文本,指定源语言和目标语言
- 调用模型生成翻译结果
对于生产环境,还需要考虑:
- 批处理:一次处理多个句子,提升吞吐量
- 缓存:常见翻译结果可以缓存,避免重复计算
- 降级策略:模型推理失败时,回退到其他翻译服务
- 质量监控:记录翻译结果,定期人工抽查质量
端侧部署需要额外的工作:
- 模型量化:用 ONNX、TensorRT、NCNN 等工具量化模型
- 推理引擎:选择适合移动端的推理引擎,比如 MNN、TNN、ONNX Runtime Mobile
- 资源管理:控制内存占用,避免 OOM
- 电量优化:推理过程比较耗电,需要优化计算逻辑
未来展望
翻译模型的发展方向主要有几个:
更多语言覆盖:目前 Hy-MT2 支持 33 种语言,未来可能会扩展到更多小语种。NLLB 已经做到了 200 种语言,但很多语言的翻译质量还不够好。如何在扩大语言覆盖的同时保证翻译质量,是一个挑战。
领域适配:通用翻译模型在专业领域的表现有限。医疗、法律、金融等领域有大量专业术语和特定表达方式,需要领域知识才能翻译准确。未来可能会出现更多领域定制的翻译模型。
多模态翻译:除了文本翻译,图片、视频、语音的翻译需求也在增长。比如图片中的文字识别和翻译、视频字幕的实时翻译、语音的同传翻译。多模态翻译需要结合 OCR、ASR、TTS 等技术,技术难度更高。
上下文理解:当前的翻译模型主要是句子级翻译,缺少对上下文的理解。一个词在不同上下文中可能有不同的含义,句子级翻译容易出现歧义。未来的翻译模型需要更好的上下文理解能力,可以处理段落级甚至文档级的翻译。
个性化翻译:不同用户对翻译风格的偏好不同,有的喜欢直译,有的喜欢意译。未来的翻译模型可能会支持个性化设置,根据用户的偏好调整翻译风格。
Hy-MT2 的开源是一个好的开始,但翻译模型的发展还有很长的路要走。期待看到更多的技术创新和应用落地。
参考来源
- Hy-MT2 模型集合 - Hugging Face - 官方模型权重和使用文档
- 腾讯混元全新翻译模型 Hy-MT2 开源 - Linux.do - 社区讨论和开发者反馈
- Hy-MT 项目文档 - GitHub - 技术文档和推理代码