Multi-Stream LLM:打破单流瓶颈的并行推理新架构
大模型推理的性能瓶颈一直是个老问题。从 KV Cache 优化到 FlashAttention,业界在单流架构上已经榨得够狠了。但斯坦福、MIT 和 Anthropic 的研究者最近换了个思路:既然单流是瓶颈,那就别挤在一条道上跑。
5 月 13 日发布的论文《Multi-Stream LLMs: Unblocking Language Models with Parallel Streams of Thoughts, Inputs, and Outputs》提出了一种全新的多流架构,把传统 LLM 的单一 token 序列拆成多个并行流——提示流、思考流、输入流、输出流各走各的路,互不阻塞。这不是简单的工程优化,而是从架构层面重新设计了 LLM 的计算范式。
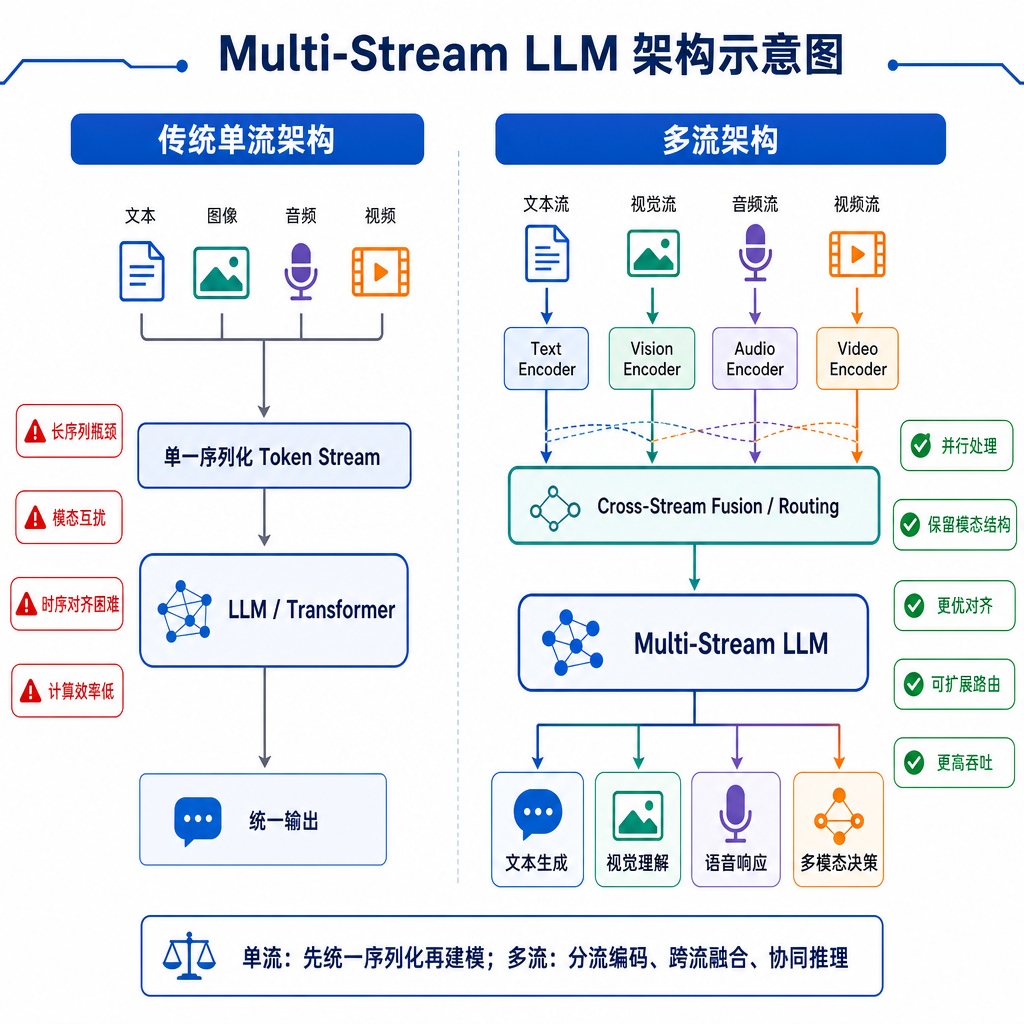
单流架构的根本问题
现有的 LLM 本质上是个自回归模型,所有 token 排成一条队列顺序生成。这在纯文本生成场景下没什么问题,但一旦涉及 Agent 应用——需要同时处理用户输入、调用工具、内部推理、生成输出——单流架构就成了灾难。
举个实际场景:你让 Agent 帮你分析一份财报。它需要:
- 读取你上传的 PDF(输入流)
- 调用计算工具处理数据(工具调用)
- 内部推理分析趋势(思考流)
- 生成可读的报告(输出流)
在传统架构下,这些操作必须串行执行。Agent 在等工具返回结果时,整个推理过程卡死;在生成长篇输出时,无法同时接收新的用户指令。更要命的是,所有内容——包括敏感的内部推理、工具调用参数、用户数据——都混在同一个 token 序列里,既不安全也不高效。
这不是实现问题,是架构设计的根本限制。单流架构天然假设所有计算都是线性依赖的,但 Agent 场景下大量操作其实可以并行。
Multi-Stream 的核心设计
Multi-Stream LLM 的思路很直接:既然不同类型的内容有不同的计算特性和安全需求,那就物理隔离开。论文提出了四类独立的流:
1. Prompt Stream(提示流) 存放系统提示、few-shot 示例等静态上下文。这部分内容通常很长但不常变化,可以预计算 KV Cache 并在多次推理间复用。传统架构下每次推理都要重新处理这些 token,Multi-Stream 把它们单独缓存,避免重复计算。
2. Thought Stream(思考流) 模型的内部推理过程,类似 Chain-of-Thought 的中间步骤。这部分内容对用户不可见,也不应该影响输出流的生成速度。Multi-Stream 让思考流异步执行,模型可以边输出边思考,而不是等思考完才开始输出。
3. Input Stream(输入流) 用户的实时输入、工具返回结果、外部数据源等动态内容。这些数据可能随时到达,传统架构下必须等当前生成完成才能处理新输入。Multi-Stream 允许输入流独立更新,模型可以在生成过程中响应新的输入事件。
4. Output Stream(输出流) 面向用户的最终输出。这是唯一需要严格自回归生成的流,但它不再被其他流阻塞。模型可以在输出流生成的同时,并行处理输入流的新数据或在思考流中规划下一步动作。
这四个流在 Transformer 内部共享底层表示,但通过 attention mask 和流标记(stream token)实现逻辑隔离。每个流有独立的 KV Cache,可以按需更新而不影响其他流。
技术实现的关键点
从单流改成多流,不是简单地把 token 序列切几段。论文在实现上解决了几个核心问题:
流间通信机制
虽然各流独立计算,但它们之间需要信息交换。比如思考流的推理结果要影响输出流的生成,输入流的新数据要触发思考流的更新。Multi-Stream 通过特殊的 cross-stream attention 实现流间通信:每个流可以选择性地 attend 到其他流的内容,但不会被其他流的生成阻塞。
这个设计很巧妙。传统 attention 是全局的,所有 token 互相可见;Multi-Stream 的 attention mask 是分块的,每个流只能看到自己和显式允许的其他流。这样既保证了必要的信息流动,又避免了不必要的依赖。
动态流调度
不是所有流在所有时刻都需要计算。用户没有新输入时,输入流可以休眠;不需要内部推理时,思考流可以暂停。Multi-Stream 实现了动态调度机制,根据每个流的状态决定是否分配计算资源。
这对推理效率影响很大。传统架构下,即使模型在等待外部输入,GPU 也在空转或者生成无用的 padding token。Multi-Stream 可以把计算资源集中在活跃的流上,闲置的流不占用 GPU 周期。
流级别的安全隔离
把思考流和输出流分离,带来了意外的安全收益。模型的内部推理过程(可能包含敏感的中间结果、工具调用参数、用户数据的分析)不会泄露到输出流中。即使输出流被攻击者观察,也无法推断思考流的内容。
这对企业应用很重要。很多场景下,模型需要处理敏感数据(财务信息、医疗记录、代码库),但输出内容要脱敏。传统架构下只能靠 prompt engineering 或后处理过滤,Multi-Stream 从架构层面保证了隔离。
性能表现:不只是理论优势
论文在多个 Agent benchmark 上测试了 Multi-Stream 架构,结果相当实在:
推理延迟降低 40-60%
在需要频繁工具调用的任务上(如 WebShop、ALFWorld),Multi-Stream 的端到端延迟比传统架构低 40-60%。主要收益来自两方面:一是输入流和思考流的并行处理,减少了等待时间;二是提示流的 KV Cache 复用,避免了重复计算。
这个提升不是靠更快的硬件或更激进的量化,而是更合理的计算编排。同样的模型、同样的硬件,只是改了推理架构。
吞吐量提升 2-3 倍
在多用户并发场景下,Multi-Stream 的吞吐量提升更明显。因为不同用户的请求可以共享提示流的 KV Cache,而各自的输入流和输出流独立计算。传统架构下每个请求都是完全独立的,无法复用任何计算。
这对 API 服务商很有吸引力。同样的 GPU 集群,Multi-Stream 可以服务更多并发用户,直接降低单次推理成本。
内存占用降低 30%
提示流的 KV Cache 在多次推理间复用,加上动态流调度减少了无效计算,Multi-Stream 的峰值内存占用比传统架构低 30% 左右。这意味着同样的显存可以跑更大的 batch size 或更长的上下文。
局限性:不是万能药
多流架构不是没有代价。论文也坦诚地指出了几个问题:
训练复杂度增加
Multi-Stream 模型需要学习流间的协调机制,这比传统的单流训练更复杂。论文使用了两阶段训练:先在单流数据上预训练,再在多流数据上 fine-tune。但多流数据的构造本身就是个问题——现有的训练语料都是单流格式,需要人工或启发式地拆分成多个流。
这可能限制了 Multi-Stream 的普及速度。除非有大规模的多流训练数据,否则很难从头训练一个高质量的 Multi-Stream 模型。更现实的路径是把现有模型改造成多流版本,但这需要大量的 fine-tuning 工作。
并非所有任务都受益
对于纯文本生成任务(写文章、翻译、摘要),Multi-Stream 的优势不明显。这些任务本身就是线性的,没有并行的空间。多流架构反而增加了调度开销,可能比单流更慢。
Multi-Stream 的价值主要体现在 Agent 场景——需要同时处理多种输入、执行复杂推理、生成结构化输出的任务。如果你的应用只是简单的问答或文本生成,单流架构可能更合适。
工程实现的挑战
多流架构对推理引擎的要求更高。现有的推理框架(vLLM、TensorRT-LLM、SGLang)都是为单流设计的,要支持 Multi-Stream 需要大量的底层改造。流间通信、动态调度、KV Cache 管理都需要重新实现。
论文提供了一个原型实现,但距离生产可用还有距离。短期内,Multi-Stream 更可能以研究原型的形式存在,而不是直接集成到主流推理框架中。
对行业的启示
Multi-Stream LLM 的意义不只是一个新架构,而是提出了一个新的思考方向:LLM 的推理范式不一定要照搬训练范式。
现有的 LLM 推理基本是训练的镜像——训练时怎么喂数据,推理时就怎么生成 token。但训练和推理的目标不同:训练追求模型能力的上限,推理追求实际应用的效率。把训练范式直接搬到推理上,必然会有不匹配的地方。
Multi-Stream 证明了,在不改变模型能力的前提下,重新设计推理架构可以带来显著的性能提升。这个思路可以推广到其他方向:
- 异构推理:不同类型的 token(文本、代码、结构化数据)用不同的解码策略
- 分层推理:把推理过程分成规划层、执行层、验证层,各层独立优化
- 投机推理:用小模型生成候选,大模型并行验证,而不是串行生成
这些方向都在探索同一个问题:如何在保持模型能力的同时,让推理过程更高效、更灵活、更安全。Multi-Stream 提供了一个具体的答案,但肯定不是唯一的答案。
开源模型的机会
有意思的是,Multi-Stream 架构对开源模型可能更友好。
闭源模型(GPT、Claude、Gemini)的推理架构是黑盒,用户只能通过 API 调用,无法控制内部的计算流程。即使这些模型内部采用了多流架构,用户也感知不到,更无法针对自己的场景优化流的配置。
开源模型则不同。如果 Llama、Qwen、DeepSeek 等模型采用 Multi-Stream 架构并开源推理代码,开发者可以根据自己的应用场景定制流的划分和调度策略。比如:
- RAG 应用可以把检索结果放在独立的输入流,避免阻塞生成
- Code Agent 可以把代码执行结果放在独立的反馈流,实现边写边测
- 多模态应用可以把图像、音频、文本放在不同的流,各自独立处理
这种灵活性是闭源 API 无法提供的。Multi-Stream 可能成为开源模型相对闭源模型的一个差异化优势——不是模型能力更强,而是推理架构更开放、更可定制。
当然,这需要开源社区在推理引擎上投入更多精力。目前 vLLM、TGI 等主流推理框架还是单流架构,要支持 Multi-Stream 需要大量的开发工作。但如果这个方向被验证有价值,社区的响应速度通常比商业公司更快。
写在最后
Multi-Stream LLM 不是那种让人眼前一亮的突破性创新,它更像是一个务实的工程优化——发现了现有架构的瓶颈,提出了一个合理的解决方案,用实验证明了效果。
但正是这种务实的创新,往往对行业影响更深远。FlashAttention、KV Cache、Speculative Decoding 都是类似的例子——不改变模型本身,只是让推理过程更高效,但最终让大模型的应用成本降低了一个数量级。
Multi-Stream 会不会成为下一个 FlashAttention?现在下结论还太早。但至少它证明了,LLM 推理的优化空间远没有耗尽,架构层面的创新仍然大有可为。
对开发者来说,这是个值得关注的方向。即使短期内用不上 Multi-Stream,理解它的设计思路也有助于优化现有的 Agent 应用——哪些操作可以并行、哪些数据可以复用、哪些流程可以异步,这些问题在单流架构下同样存在,只是没有被系统化地解决。
Multi-Stream 提供了一个系统化的框架。接下来就看工程实现能不能跟上了。
参考资料
- Multi-Stream LLMs 论文 - 斯坦福、MIT、Anthropic 联合发布的原始论文
- Reddit 讨论 - 社区对 Multi-Stream 架构的技术讨论
- Hugging Face 相关讨论 - 开源社区对多流架构的实现探讨