Sivtr 开源:让人和 AI Agent 共享工作记忆
一个开发者在多个终端窗口、多个 AI Agent 之间切换时,最头疼的是什么?不是代码写不出来,而是找不到刚才那条命令输出在哪个窗口、上一轮对话的上下文丢在哪个 session 里。
Sivtr 就是冲着这个痛点来的。这个基于 Rust 的开源项目,把终端输出和 Agent 对话放进同一个工作区,人通过 TUI 面板浏览,Agent 通过 CLI 和 Skill 检索。核心理念很直接:人和 Agent 共享同一套工作记忆层。
解决的是真问题
多终端、多 Agent 协同的场景下,上下文管理一直是个老大难。你在 Terminal 里跑了个命令,输出一大堆日志,想复制给 Claude;切到 Cursor 里写代码,又要把刚才的错误信息粘贴给 Copilot;再打开 VS Code 的 Codex 插件,发现之前那段对话记录找不到了。
传统做法是什么?鼠标狂点,窗口狂切,Ctrl+C/Ctrl+V 按到手酸。更要命的是,这些操作都是割裂的——终端是终端,Agent 是 Agent,彼此不知道对方在干什么。
Sivtr 的思路是:既然人和 Agent 都在处理同一个项目的上下文,为什么不让它们共享同一个记忆空间?
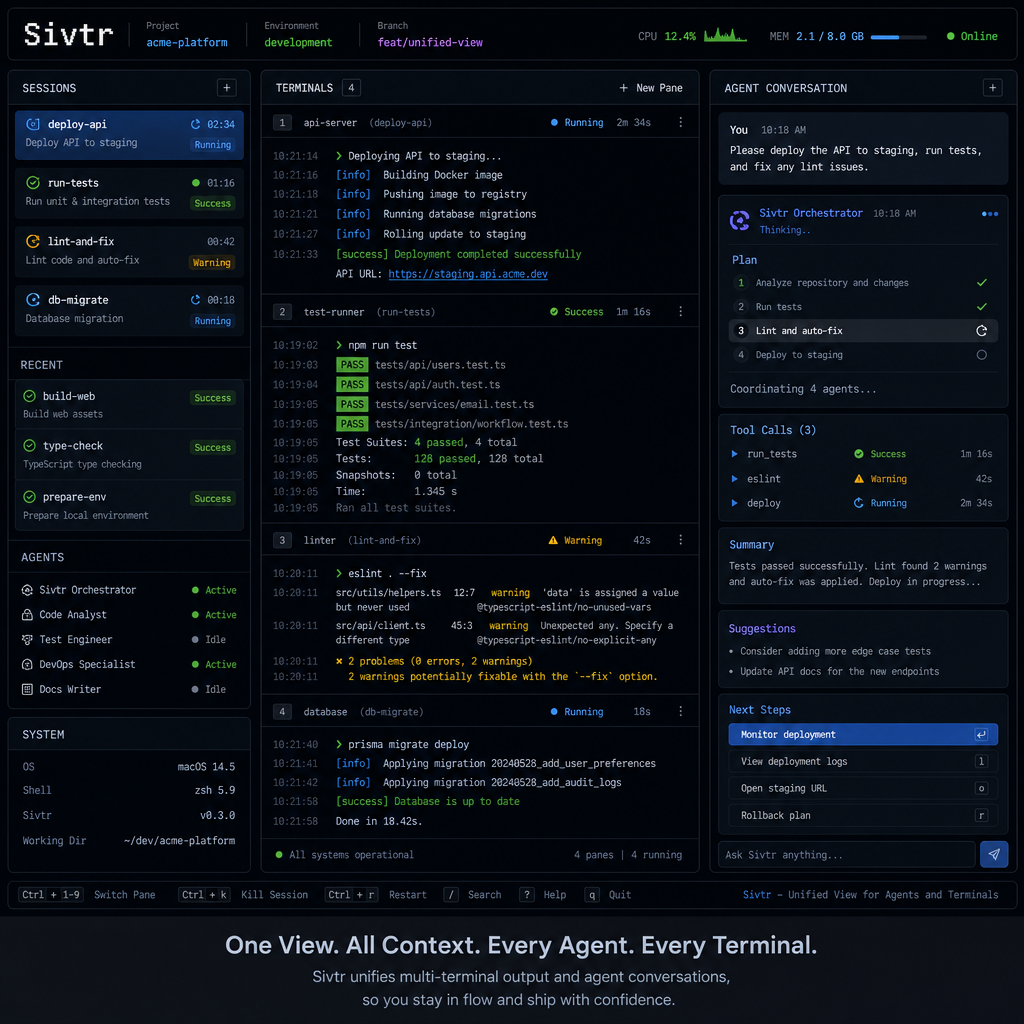
对人:跨会话复制粘贴,一键搞定
从人的角度看,Sivtr 最直接的价值是跨 session、跨终端、跨 Agent 的复制粘贴。
举个例子。你在终端里运行了一条 docker ps 命令,输出了一堆容器信息。传统做法是鼠标选中、复制、切窗口、粘贴。用 Sivtr,直接在命令行敲 sivtr cc 1,就把最近第 1 条命令的输出复制到剪贴板了。想复制最近 3 到 5 条命令的输出?sivtr co 3..5。
更进一步,Sivtr 支持正则检索。比如你想找最近所有包含 "error" 的输出,sivtr co -r \"error\" 就行。不用翻窗口,不用滚日志,直接定位。
这套逻辑不只适用于终端命令,也适用于 Agent 对话。你在 Claude 里问了个问题,回答很长,想把其中某一段提取出来。传统做法是打开对话历史,滚到那条消息,鼠标选中。用 Sivtr,所有对话都在同一个工作区里,sivtr co -a claude 1 就能复制 Claude 最近第 1 条回复。
关键是,这些操作都是跨 session 的。你昨天跑的命令、上周的 Agent 对话,只要还在 Sivtr 的记忆层里,随时可以检索、复制、引用。
对 Agent:统一的上下文检索接口
Sivtr 不只是给人用的工具,更是给 Agent 设计的共享记忆层。
传统 Agent 的记忆管理是怎么做的?要么把对话历史塞进 prompt,要么用向量数据库做 RAG。前者受限于上下文窗口,后者需要额外的基础设施。而且,这些记忆都是Agent 私有的——Claude 不知道你在 Cursor 里干了什么,Copilot 也不知道你在终端里跑了什么命令。
Sivtr 提供的是一个统一的记忆检索接口。Agent 可以通过 CLI 或 Skill 调用,查询终端输出、其他 Agent 的对话、甚至人类的操作记录。
比如,你在终端里运行了一个测试脚本,输出了一堆错误信息。然后你问 Claude:"刚才那个测试为什么失败了?" 传统做法是你得手动把错误信息复制粘贴给 Claude。用 Sivtr,Claude 可以直接调用 sivtr query -t terminal -r \"test failed\" 检索最近的终端输出,自己找到错误信息。
更进一步,多个 Agent 之间也能通过 Sivtr 协同。假设你让 Cursor 写了一段代码,然后让 Claude 做 Code Review。传统做法是你得把代码从 Cursor 复制到 Claude。用 Sivtr,Claude 可以直接查询 Cursor 最近生成的代码片段,不需要人工中转。
这种设计的核心价值在于:Agent 不再是孤岛,而是共享同一个工作记忆空间。
技术实现:Rust + TUI + CLI
Sivtr 的技术栈选择很务实:Rust 写核心逻辑,TUI 做人机交互界面,CLI 做 Agent 调用接口。
为什么用 Rust? 因为 Sivtr 要处理的是高频、低延迟的操作——终端输出捕获、命令历史记录、实时检索。Rust 的性能和内存安全特性,保证了这些操作不会拖慢开发流程。而且,Rust 的跨平台支持很好,Sivtr 已经在 Windows、Linux、macOS 上可用。
TUI 界面怎么设计的? Sivtr 的 TUI 面板是一个统一的工作区视图。左侧是时间线,按时间顺序展示所有终端输出和 Agent 对话;右侧是详情面板,显示选中条目的完整内容。你可以用键盘快捷键快速浏览、搜索、复制。
项目还提供了 VS Code 插件,可以通过快捷键直接呼出 TUI 面板。这对 Cursor、Codex 这类 IDE 内置 Agent 特别有用——你不用切出 IDE,就能查看终端输出或其他 Agent 的对话记录。
CLI 接口怎么用? Sivtr 的 CLI 命令设计得很简洁:
sivtr cc <n>:复制第 n 条命令的输入sivtr co <n>:复制第 n 条命令的输出sivtr co <m>..<n>:复制第 m 到 n 条命令的输出sivtr co -r <regex>:复制匹配正则表达式的输出sivtr co -a <agent> <n>:复制指定 Agent 的第 n 条回复
这些命令既可以人手动调用,也可以被 Agent 通过 Skill 调用。
适配主流 Agent 生态
Sivtr 已经适配了几个主流的 AI 编程工具:
- Cursor:通过 VS Code 插件集成,可以在 Cursor 里直接呼出 Sivtr 面板
- Claude Code:支持通过 CLI 查询 Claude 的对话历史
- Codex:同样通过 VS Code 插件集成
- Pi Agent:支持通过 Skill 调用 Sivtr 的检索接口
这些适配不是简单的"能用",而是深度集成到工作流里。比如,你在 Cursor 里写代码,遇到一个编译错误,想看看刚才终端里的完整错误信息。传统做法是切到终端窗口,滚日志,找错误。用 Sivtr,直接在 Cursor 里按快捷键呼出面板,搜索 "error",一秒定位。
这个方向有多大想象空间?
Sivtr 现在做的,本质上是人和 Agent 的共享工作记忆层。这个方向的想象空间,远不止跨终端复制粘贴。
第一个方向是多 Agent 协同。现在的 AI 编程工具,基本都是单 Agent 模式——你问 Claude 一个问题,Claude 回答;你问 Copilot 一个问题,Copilot 回答。但实际开发场景里,很多任务需要多个 Agent 配合。比如,让 Cursor 写代码,让 Claude 做 Code Review,让 Copilot 写测试。这三个 Agent 如果能共享同一个记忆层,协同效率会高很多。
第二个方向是长期记忆管理。现在的 Agent 记忆,要么是短期的(对话历史),要么是静态的(RAG 知识库)。Sivtr 提供的是一个动态的、可检索的长期记忆层。你上周写的代码、上个月的 Agent 对话、三个月前的终端输出,都可以随时检索、引用。这对需要长期维护的项目特别有用。
第三个方向是跨项目的知识复用。Sivtr 的记忆层不是绑定在单个项目上的,而是可以跨项目共享。比如,你在项目 A 里遇到过一个 Docker 配置问题,解决方案记录在 Sivtr 里。几个月后,你在项目 B 里遇到类似问题,Sivtr 可以直接检索出之前的解决方案。
当然,这些方向都还在早期阶段。Sivtr 现在的功能还比较基础,但核心架构已经搭好了。
开源社区的反馈
Sivtr 在 Linux.do 社区发布后,反响不错。几个开发者提到的痛点,确实是 Sivtr 想解决的:
- 多终端场景下的上下文丢失:一个开发者说,他经常在 3-4 个终端窗口之间切换,每次都要花时间找之前的命令输出。用了 Sivtr 之后,直接在 TUI 面板里搜索,效率提升明显。
- Agent 对话历史难以管理:另一个开发者提到,他用 Claude 和 Cursor 写代码,经常需要回看之前的对话,但两个工具的对话历史是分开的。Sivtr 把它们放在同一个工作区里,查找方便多了。
- 跨 session 的复制粘贴:还有开发者说,他经常需要把昨天的命令输出复制给今天的 Agent,传统做法是翻终端历史或者 Agent 对话记录。Sivtr 的跨 session 检索功能,正好解决了这个问题。
也有人提出了一些改进建议,比如支持更多的 Agent、增加向量检索功能、提供 Web 界面等。项目作者表示,这些功能都在规划中。
值得关注的几个细节
1. 隐私和安全
Sivtr 把所有终端输出和 Agent 对话都记录下来,这涉及到隐私和安全问题。项目文档里提到,Sivtr 的数据存储是本地化的,不会上传到云端。而且,用户可以配置哪些命令或对话不被记录(比如包含敏感信息的命令)。
2. 性能开销
Sivtr 需要实时捕获终端输出和 Agent 对话,这会不会影响性能?根据项目文档,Sivtr 的核心逻辑是异步的,捕获和存储操作不会阻塞主线程。而且,Rust 的性能优势保证了即使在高频操作下,开销也很小。
3. 扩展性
Sivtr 的架构是模块化的,支持通过插件扩展功能。比如,你可以写一个插件,把 Sivtr 的记忆层同步到 Notion 或 Obsidian;或者写一个插件,支持向量检索和语义搜索。
和现有方案的对比
市面上有没有类似的工具?有,但定位不太一样。
终端历史管理工具(如 atuin、mcfly):这些工具专注于终端命令历史的管理和检索,但不涉及 Agent 对话,也不提供统一的工作区视图。
Agent 记忆管理方案(如 LangChain 的 Memory 模块、MemGPT):这些方案专注于 Agent 的长期记忆,但不涉及终端输出,也不提供人机共享的接口。
多 Agent 协同框架(如 AutoGPT、MetaGPT):这些框架专注于多 Agent 的任务分解和协同,但记忆管理不是核心功能。
Sivtr 的独特之处在于:它同时面向人和 Agent,提供统一的记忆共享层。这个定位,目前市面上还没有直接竞品。
适合谁用?
重度 AI 编程用户:如果你同时用多个 AI 编程工具(Cursor、Claude、Copilot 等),经常需要在它们之间切换上下文,Sivtr 能显著提升效率。
多终端开发者:如果你习惯开多个终端窗口(本地、远程、Docker 容器等),经常需要跨终端复制粘贴,Sivtr 的跨 session 检索功能会很有用。
Agent 开发者:如果你在开发自己的 Agent 或 AI 工作流,需要一个统一的记忆管理层,Sivtr 提供了现成的基础设施。
长期项目维护者:如果你维护的项目周期很长,需要经常回看之前的命令输出或 Agent 对话,Sivtr 的长期记忆管理功能会很有价值。
未来方向
从项目文档和社区讨论来看,Sivtr 接下来可能会往几个方向发展:
1. 支持更多 Agent:目前已经适配了 Cursor、Claude、Codex、Pi Agent,未来可能会支持 GitHub Copilot、Tabnine、Codeium 等更多工具。
2. 向量检索和语义搜索:现在的检索主要基于关键词和正则表达式,未来可能会引入向量检索,支持语义搜索。比如,你问"上周那个 Docker 配置问题怎么解决的",Sivtr 可以通过语义理解找到相关记录。
3. 多人协同:现在 Sivtr 是单用户的,未来可能会支持团队协同。比如,团队成员可以共享某些记忆片段,或者查询其他成员的操作记录(当然需要权限控制)。
4. Web 界面:现在 Sivtr 主要通过 TUI 和 CLI 使用,未来可能会提供 Web 界面,方便在浏览器里查看和管理记忆。
5. 与知识管理工具集成:比如,把 Sivtr 的记忆层同步到 Notion、Obsidian、Logseq 等工具,方便做笔记和知识沉淀。
总结
Sivtr 解决的是一个很实际的问题:多终端、多 Agent 场景下的上下文管理。它的核心价值不是技术有多炫,而是真的能提升开发效率。
从人的角度看,Sivtr 让跨 session、跨终端、跨 Agent 的复制粘贴变得简单。从 Agent 的角度看,Sivtr 提供了一个统一的记忆检索接口,让多 Agent 协同成为可能。
这个方向的想象空间很大。现在的 AI 编程工具,基本都是单 Agent、短期记忆的模式。Sivtr 提出的"人和 Agent 共享工作记忆层",可能是未来 AI 编程工作流的一个重要方向。
项目刚开源不久,功能还在完善中,但核心架构已经搭好了。如果你是重度 AI 编程用户,或者对 Agent 记忆管理感兴趣,值得关注一下。
参考来源
- Sivtr GitHub 仓库 - 项目源码和文档
- Sivtr 在 Linux.do 的开源推广帖 - 项目介绍和社区讨论