残差连接这个老朋友,被人动了刀
5 月 24 日,一篇发布在 r/MachineLearning 上的工作引起了不少关注:Delta Attention Residuals,一种声称可以即插即用替换 Transformer 残差连接的新机制。研究者把它定位成 "drop-in upgrade",从 220M 一路测到 7.6B,验证集 PPL 稳定下降 1.7% 到 8.2%。
这个数字在当下不算炸裂,但它指向的是一个被反复尝试、却始终没能在大模型上跑通的老问题:跨层注意力(cross-layer attention)的路由坍缩。换句话说,过去那些试图让深层网络 "回头看" 浅层信息的方案,规模一上来就废了。Delta Attention Residuals 给出了一个挺优雅的解法——不是改路由器,而是改被路由的对象。
先回顾一下问题在哪
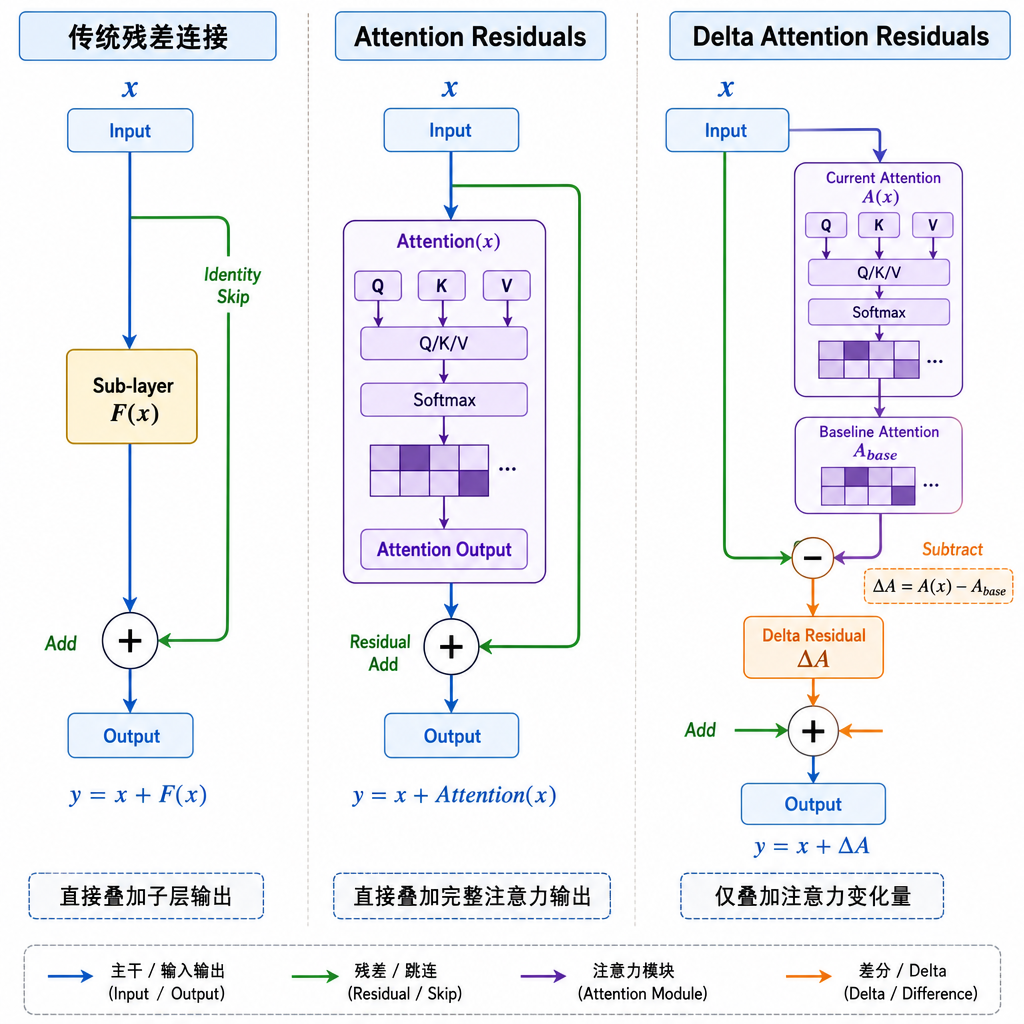
标准 Transformer 的残差连接长这样:
h_{i+1} = h_i + Sublayer(h_i)
每一层把自己算出来的东西加回主干,这是 2015 年 ResNet 留下的遗产,简单粗暴但好使。问题是,深层 Transformer 里每一层能 "看到" 的只有上一层的输出 h_i,浅层那些细粒度的句法、词形信息已经被层层叠加稀释掉了。
于是有了 Attention Residuals 这一类工作,思路是给每一层加一个小型注意力模块,让它在所有过往的隐状态 {h_0, h_1, ..., h_i} 上做加权选择,而不是只接收 h_i。听起来很合理——你想看哪一层就看哪一层,路由器自己学。
但实际跑起来,问题来了:累积隐状态之间高度冗余。
这件事其实早该被注意到。残差连接的本质是叠加,h_5 里包含了 h_0 到 h_4 的所有累积贡献,h_6 又包含了 h_5。这些向量在表征空间里彼此非常接近,余弦相似度高得吓人。让一个 softmax 路由器在一堆几乎相同的向量里挑选,最后的结果只能是——摆烂,权重摊平成接近均匀分布。
论文里给的数字很直观:在深层,标准 Attention Residuals 的最大注意力权重大约只有 0.2,对一个本应做 "选择" 的路由器来说,这等于没选。这就是所谓的 routing collapse。更糟的是,规模放大后这个机制不仅没好处,甚至会比基线还差——7.6B 上 PPL 是 18.58,而普通残差只有 17.43。
Delta 的核心想法:路由 "贡献" 而不是 "状态"
作者的切入点很简洁:既然 h_i 之间高度冗余,那就别路由 h_i,路由它们之间的差分。
v_i = h_{i+1} - h_i
这个 v_i 就是第 i 个子层 "实际贡献了什么",把累积量做了一次离散微分。相比 h_i 这种状态量,v_i 是 增量量,结构上天然彼此不同——一个 attention 层贡献的方向和一个 FFN 层贡献的方向不一样,浅层和深层贡献的语义层级也不一样。
打个不太严谨的比方:原来路由器拿到的是一堆 "账户余额",每一笔都长得差不多;现在拿到的是 "每月流水",进出明细一目了然。让你在一堆余额里挑哪个最值得参考,你只能蒙;让你在流水里挑,你立刻知道哪个月发生了什么。
效果立竿见影:
- 深层最大注意力权重从 ~0.2 抬到 ~0.6
- 平均最大权重从 0.35 提升到 0.62
- 路由分布的锐度提升约 1.8 倍
这意味着路由器真的在做选择了,而不是平均地照顾所有过去层。
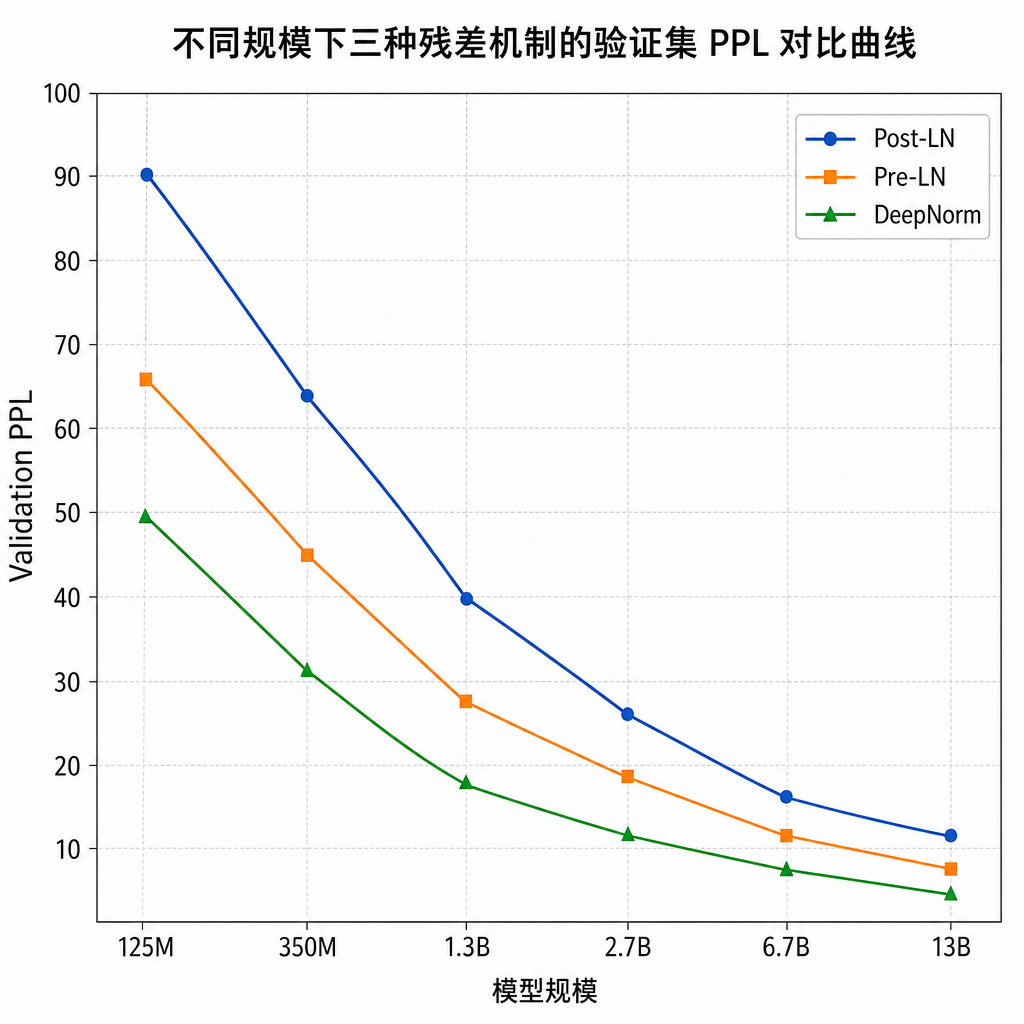
数据说话:从 220M 到 7.6B 的尺度曲线
这个工作真正值得注意的地方,其实是规模实验。AI 圈这几年充斥着 "小模型上 work、大模型上崩" 的故事,跨层注意力就是典型受害者。作者把对照组拉满:
| 规模 | 标准残差 PPL | Attention Residuals PPL | Delta Attention Residuals PPL |
|---|---|---|---|
| 220M | 基线 | 略优 | -1.7% ~ -3% |
| 1B+ | 基线 | 持平或略劣 | 稳定优于基线 |
| 7.6B | 17.43 | 18.58(反而更差) | -8.2%(最优) |
这条曲线讲了两件事。
第一,Attention Residuals 在大模型上不仅没用还有害,这不是实验误差,是 routing collapse 在 scale 下的必然结果——路由器维度变大、深度加深,冗余问题指数级恶化。第二,Delta 的优势是随规模放大的。8.2% 的 PPL 降幅在 7.6B 这个量级不是小数字,意味着同样的训练 token 数下,模型的语言建模能力实质性提升了一档。
实现成本:几乎为零
按作者描述,Delta Attention Residuals 是 "drop-in",意思是你不需要改架构,只在每层之间加一个轻量的路由模块,输入从 {h_0, ..., h_i} 换成 {v_0, ..., v_{i-1}}。伪代码大致是这样:
# 标准残差
h_next = h + sublayer(h)
# Delta Attention Residuals
v_i = h_next - h # 当前子层的 delta
deltas.append(v_i) # 累积所有历史 delta
routed = attention_route(deltas, query=h_next) # 在 deltas 上路由
h_next = h_next + routed # 把路由结果叠回主干
需要存的额外状态是历史 delta 序列,显存开销和原本存累积隐状态差不多——其实更省,因为你不需要再保留 h_0,只需要保留差分。计算开销主要来自路由器本身的注意力计算,作者说这部分相对总 FLOPs 可忽略。
训练侧没有特殊技巧,没有 warm-up trick、没有辅助 loss,就是把模块塞进去开始练。这一点比很多需要复杂训练 schedule 的方案友好得多。
这事儿到底重要在哪
抛开数字,聊点判断。
第一,它把一个老话题重新变成了 open problem。 跨层连接在 DenseNet 时代就被研究透了,过去几年很多人觉得 Transformer 的残差结构已经定型、没必要再折腾。Delta 的结果说明这块还有可挖的空间,而且挖出来的不是 0.5% 的玄学提升,是 8% 量级的实在收益。
第二,它对 "信息在 Transformer 里如何流动" 这个问题给了新的实验依据。 路由权重从 0.2 抬到 0.6,意味着模型确实在 "挑选" 历史层——这是可解释性研究者会感兴趣的。哪些 delta 被频繁选中?是早期的句法层 delta,还是中层的语义层 delta?这些都是后续值得追的问题。
第三,它和 MoE、KV cache 优化这些方向是正交的。 你完全可以在一个 MoE 模型里使用 Delta 残差,也可以叠加 GQA、MLA 之类的 attention 变体。这种正交性让它有机会被快速吸收进下一代开源大模型架构里。
要泼冷水的话,也有几点要说。当前公开的实验主要是 PPL,下游 benchmark(MMLU、HellaSwag、代码任务等)的数据还没看到完整披露。PPL 降低和下游能力提升之间不是严格线性关系,尤其在指令微调、RLHF 之后,预训练阶段的 PPL 优势可能会被部分抹平。另外,7.6B 还不算真正的大模型时代,30B、70B 上能不能保持线性的 scaling 优势,需要更多算力投入才能验证。
对开发者意味着什么
如果你在做预训练或者从头架构调整,Delta Attention Residuals 值得放进短期的 ablation 列表。改动量小,潜在收益明确,失败成本低。
如果你只是在用现成的开源模型做微调或推理,这个工作短期内和你关系不大——它需要从头训练才能体现价值,没法在已经训好的权重上 retrofit。但中长期看,下一波开源大模型如果采纳类似机制,推理框架可能需要适配新的层间连接方式,vLLM、SGLang 这类项目大概率会跟进。
至于在线调用现成模型这条路,主流的 GPT、Claude、Gemini、DeepSeek 这些 API 还是该怎么用怎么用,OpenAI Hub 这边的接入也没受影响。架构层面的革新最终落到 API 用户手上,往往要等下一代模型发布才能感知到。
写在最后
2026 年这个时间点,预训练范式的边际收益越来越薄,scaling law 的曲线在所有人能感知的层面都开始放缓。这种背景下,架构层面的微创新反而值钱了——一个改动几十行代码、训练成本不变、却能稳定降低 8% PPL 的方案,放在两年前可能没人在乎,现在却是真金白银的优化。
Delta Attention Residuals 不是革命,但它是那种 "做对了一件小事" 的工作。在大家都在拼数据、拼算力的当下,能从结构假设里抠出收益的研究,越来越稀缺。
参考来源
- Delta Attention Residuals 原始发布讨论 - r/MachineLearning — 研究者首次公开方法和实验数据的 Reddit 帖子,含作者本人在评论区的答疑