开源框架Spice:Agent需要的是可追溯状态,不是更长上下文
一个有9年AI经验的00后开发者Jia最近在Reddit和Linux.do社区发布了一个开源项目Spice,提出了一个反直觉的观点:Agent系统真正需要的不是更长的上下文窗口,而是可追溯的状态管理机制。
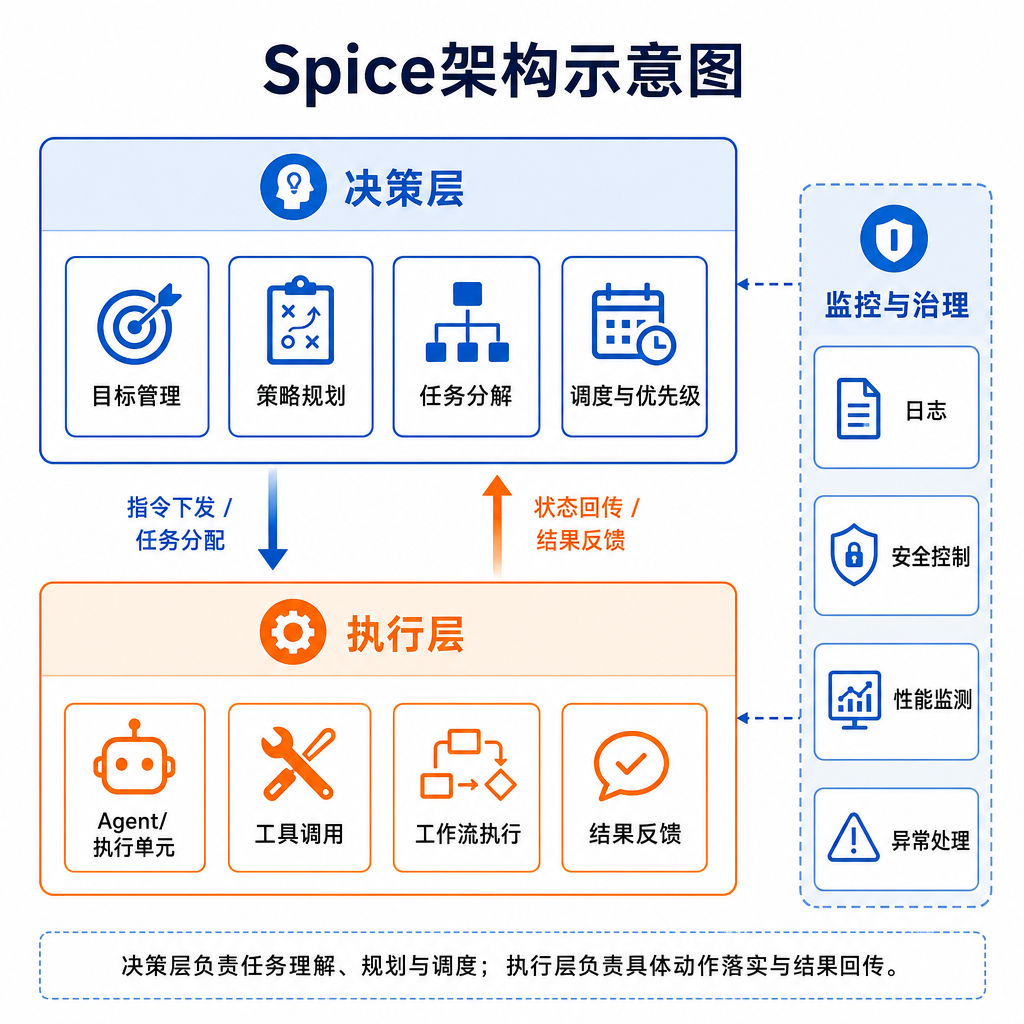
这个项目的核心思路是在执行层Agent之上构建一个决策层,让AI系统的决策过程变得显式、可追溯、可审计。目前项目已在GitHub开源,吸引了不少开发者用于研究、产品经理Agent、量化交易等场景。
决策层是什么?为什么需要它?
Spice的定位很明确:一个位于Agent执行层之上的决策层。
当前主流的Agent系统——无论是Claude Code、Codex还是Hermes——都专注于执行能力的提升。给它们一个明确的意图,它们能越来越好地完成任务。但有个更高层的问题通常被留给用户:接下来该做什么,为什么?
Spice不打算替代这些执行Agent,而是坐在它们前面,把决策过程拆解成可检查的步骤:
- 观察到了什么
- 考虑了哪些选项
- 为什么选择了某个选项
- 拒绝了哪些权衡
- 执行后发生了什么
- 这个结果如何影响下一次决策
这种设计哲学的转变,本质上是从"让模型做得更好"转向"让系统决策得更清晰"。
从Prompt到Context,再到State
Jia在介绍Spice时提出了一个演进路径,很好地解释了为什么需要State Engineering:
Prompt Engineering(2024):解决"模型这次该怎么说"。重点是如何设计提示词让模型按预期回答。
Context Engineering(2025):解决"模型这次能看到什么"。重点是如何把正确的信息放入上下文窗口。
State Engineering(2026及以后):解决"系统现在相信什么,模型基于什么来做下一次决策"。重点是长期且深入地维护用户状态。
这个演进不是技术的简单迭代,而是工程重心的根本转移。
为什么Context不够?
很多人的第一反应是:把上下文窗口做得更长不就行了?从8K到128K再到1M tokens,问题不就解决了吗?
但Jia认为这是方向性的误判。更长的上下文解决的是"能看到多少历史信息",但没有解决"如何从历史中提取有效状态"和"如何保证决策的一致性"。
举个例子:一个产品经理Agent在第一天的对话中了解到用户偏好简洁的UI设计,第三天又了解到用户需要丰富的数据可视化功能。这两个需求可能存在冲突。如果只是把所有对话塞进上下文,模型可能会在第五天的决策中忘记第一天的偏好,或者无法显式地处理这个权衡。
State Engineering要做的是:
- 显式记录"用户偏好简洁UI"这个状态
- 显式记录"用户需要丰富可视化"这个状态
- 在决策时显式地识别冲突
- 显式地做出权衡并记录理由
- 让这个决策过程可追溯、可审计
这不是更长的上下文能解决的问题,而是需要一套状态管理和决策追溯机制。
Spice的技术实现
从目前公开的信息看,Spice的运行时还处于早期阶段,但已经可以安装使用。基本流程是:
- 安装Spice
- 配置LLM provider(支持主流模型)
- 在终端运行
- 检查Decision对象(决策记录)
核心的数据结构是Decision对象,它记录了一次完整的决策过程。这个设计让决策变成了一等公民(first-class citizen),而不是隐藏在prompt和response之间的黑盒。
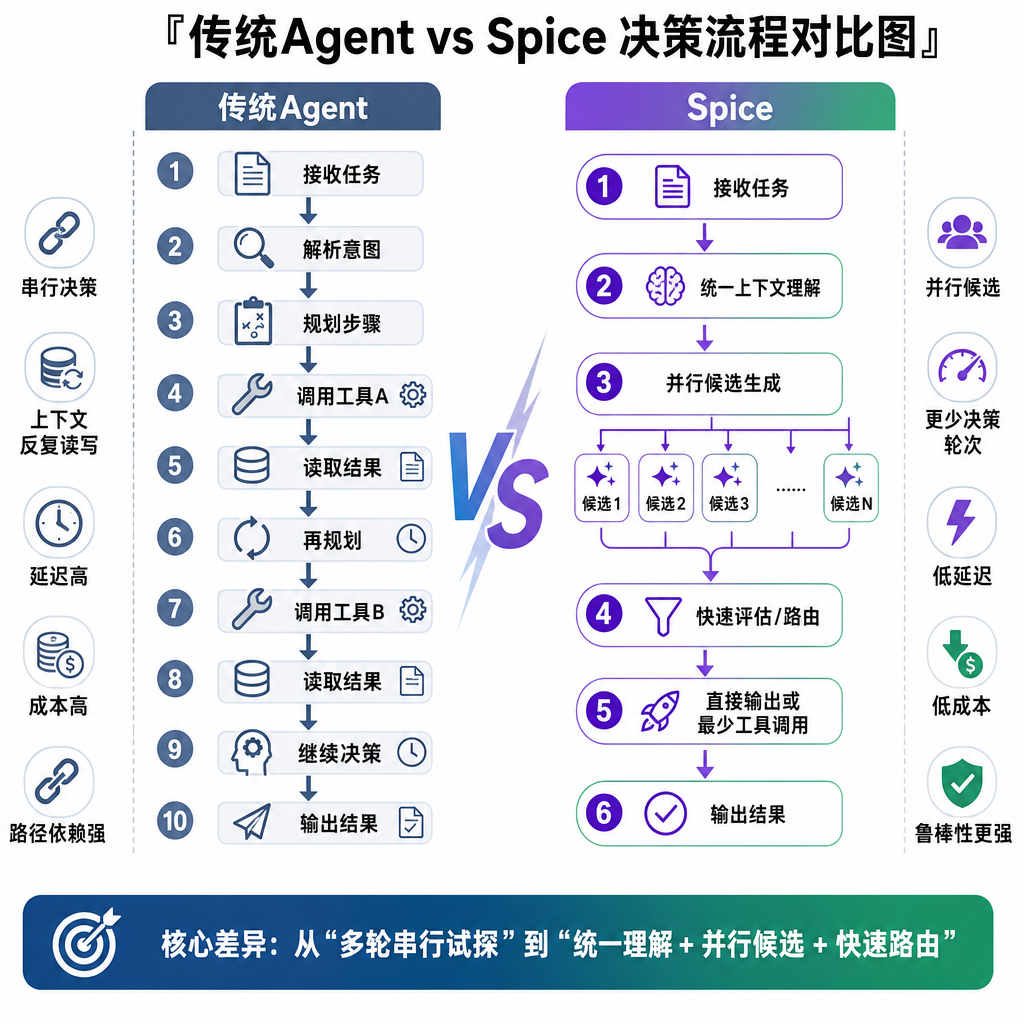
与传统Agent的区别
传统Agent的工作流程通常是:
用户输入 → LLM推理 → 工具调用 → 返回结果
Spice的工作流程是:
观察环境 → 生成候选决策 → 评估权衡 → 选择决策 → 记录理由 → 执行 → 更新状态
关键差异在于:
- 显式的候选生成:不是直接输出一个答案,而是先生成多个可能的选项
- 显式的权衡评估:每个选项的优劣、风险、成本都被记录下来
- 显式的决策理由:为什么选A不选B,这个理由被持久化
- 状态的持续更新:决策的结果会更新系统状态,影响后续决策
这种设计让Agent系统从"黑盒执行器"变成了"可解释的决策系统"。
实际应用场景
根据社区反馈,Spice已经被用在了几个有意思的场景:
研究场景:研究人员用Spice来追踪实验决策过程。比如在调参时,记录每次参数调整的理由、预期效果、实际结果,以及这些结果如何影响下一次调整。这比简单的实验日志更有价值,因为它捕捉了决策的因果链。
产品经理Agent:让Agent扮演产品经理角色,收集需求、分析竞品、制定roadmap。Spice的决策追溯能力让这个过程变得可审计——你可以看到Agent为什么优先做功能A而不是功能B,这个决策基于什么假设,后续如何验证。
量化交易:在量化策略中,决策的可追溯性至关重要。Spice可以记录每次交易决策的依据、风险评估、预期收益,以及实际结果如何反馈到下一次决策。这对策略优化和风险控制都有价值。
这些场景的共同点是:需要长期交互、需要决策一致性、需要可解释性。这正是Spice想要解决的问题。
开源社区的反响
项目在Linux.do社区发布后,获得了不少关注。有开发者表示这个思路很新颖,也有人质疑实际效果如何。
支持者认为,Spice抓住了当前Agent系统的一个真实痛点:执行能力在提升,但决策能力和长期一致性还很弱。通过显式的状态管理和决策追溯,可以让Agent系统更可控、更可信。
质疑者则担心,增加这一层决策抽象会不会带来额外的复杂度和性能开销?在实际应用中,这套机制能否真正提升Agent的表现,还是只是增加了工程负担?
这些问题需要更多实践来回答。好在Spice是完全开源的,任何人都可以试用、改进、验证。
State Engineering的未来
Jia提出的State Engineering概念,本质上是在问一个更深层的问题:AI系统如何在长期交互中保持一致性和可靠性?
当前的LLM是无状态的——每次推理都是独立的,依赖上下文来"记住"历史。这种设计在短对话中没问题,但在长期交互中会遇到瓶颈:
- 上下文窗口的物理限制:即使扩展到10M tokens,也不可能无限增长
- 信息检索的效率问题:上下文越长,模型找到关键信息的难度越大
- 决策一致性的挑战:没有显式的状态管理,模型容易在长期交互中"忘记"之前的决策或产生矛盾
State Engineering试图通过显式的状态抽象来解决这些问题。它不是简单地把所有历史塞进上下文,而是:
- 提取关键状态:从历史交互中提取出影响决策的关键信息
- 维护状态一致性:确保新决策不会与已有状态产生无法解释的矛盾
- 追溯决策链条:让每个决策都能追溯到它的依据和理由
这种思路不仅适用于Agent系统,也可能影响更广泛的AI应用设计。
与现有工具的关系
Spice不是要替代现有的Agent框架,而是作为一个补充层存在。你仍然可以用LangChain、AutoGPT、Claude Code等工具来做执行,Spice负责在它们之上提供决策管理。
这种分层设计的好处是:
- 执行层可以继续优化:更快的推理、更好的工具调用、更强的代码生成
- 决策层专注于一致性:状态管理、决策追溯、权衡评估
- 两层可以独立演进:不会因为决策层的改动影响执行层的性能
从架构角度看,这是一个合理的关注点分离(separation of concerns)。
技术挑战与未来方向
当然,Spice还处于早期阶段,有不少技术挑战需要解决:
状态表示问题:如何用结构化的方式表示复杂的决策状态?自然语言描述灵活但难以计算,结构化数据精确但表达力有限。需要找到一个平衡点。
状态更新策略:什么时候更新状态?如何处理状态冲突?如何避免状态爆炸?这些都需要精心设计的策略。
性能开销:增加决策层会带来额外的LLM调用和计算开销。如何在可解释性和效率之间取得平衡?
与人类的交互:决策过程显式化后,如何让人类有效地介入和监督?UI/UX设计也是个挑战。
Jia在社区中表示,这些问题都在探索中,欢迎开发者贡献想法和代码。
对行业的启发
Spice这个项目的价值,不仅在于它提供了一个可用的工具,更在于它提出了一个值得思考的方向:Agent系统的下一步演进,可能不在执行层,而在决策层。
过去两年,行业在执行能力上投入了大量资源:更强的模型、更好的工具调用、更快的推理速度。这些都很重要,但可能还不够。
真正让AI系统进入用户生活、承担长期任务的关键,可能是决策的可靠性和可解释性。用户需要知道AI为什么做出某个决策,需要相信AI在长期交互中不会"精神分裂",需要在必要时介入和纠正。
Spice的State Engineering思路,为这个方向提供了一个具体的探索路径。它不一定是最终答案,但至少是一个有价值的尝试。
对于开发者来说,这个项目也提供了一些启发:
- 不要只盯着模型能力:系统设计和架构同样重要
- 显式优于隐式:把关键的决策过程显式化,而不是藏在黑盒里
- 长期一致性是个真问题:不要以为更长的上下文就能解决一切
如何开始使用
如果你对Spice感兴趣,可以从GitHub仓库开始:
- Clone项目代码
- 按照README配置LLM provider(支持OpenAI、Anthropic等主流API)
- 运行示例代码,观察Decision对象的结构
- 尝试在自己的项目中集成
项目还在快速迭代中,文档和示例会持续完善。如果你有想法或遇到问题,可以在GitHub提Issue或在Linux.do社区讨论。
Spice这个项目的出现,标志着Agent系统的工程重心正在从"如何执行"转向"如何决策"。这不是技术的简单升级,而是思维方式的转变。
从Prompt Engineering到Context Engineering,再到State Engineering,每一步都在解决更深层的问题。Spice能否成功还需要时间验证,但它提出的问题和方向,值得每个AI开发者思考。
毕竟,让AI做得更快是一回事,让AI做得更对、更可信,是另一回事。后者可能才是真正的难题。
参考来源
- Spice GitHub仓库 - 项目源码和文档
- Reddit讨论帖 - 作者在r/MachineLearning的介绍
- Linux.do社区帖子 - 中文社区的详细介绍和讨论