微软开源 Webwright:1000 行代码让 GPT-5.4 网页任务成功率飙升 81%
微软研究院本月开源了网页智能体框架 Webwright,这个只有约 1000 行代码的框架,让 GPT-5.4 在复杂网页任务上的表现直接跃升一个台阶。在 Odysseys 基准测试中,Webwright + GPT-5.4 组合拿到 60.1% 的成功率,比基础 GPT-5.4 的 33.5% 高出 26.6 个百分点,提升幅度达 81.49%。
这个成绩意味着什么?今年 4 月 Odysseys 榜单上的最佳模型 Claude Opus 4.6 得分是 44.5%,Webwright 直接把这个记录提升了 35.1%。而且这还是在处理平均 272.3 个词的长链路跨站任务——不是简单的表单填写,是那种需要在多个网站间跳转、理解上下文、完成复杂操作序列的真实场景。
不预测点击,直接写代码
传统网页智能体的玩法是"截图或解析 DOM → 预测下一步点击/输入/滚动"。这种方式在简单任务上还行,但一旦遇到多步骤操作就容易掉链子。想想看,填一个复杂表单、选日期、跨页面重复操作,用点击序列表达有多别扭。
Webwright 换了个思路:让模型直接在终端里写 Playwright 代码。Playwright 是微软自家的浏览器自动化库,开发者用它写 E2E 测试已经很熟了。现在 AI 也用同样的工具,写代码、执行 shell 命令、看日志和截图、发现问题再改代码,整个流程跟人类开发者调试脚本没什么两样。
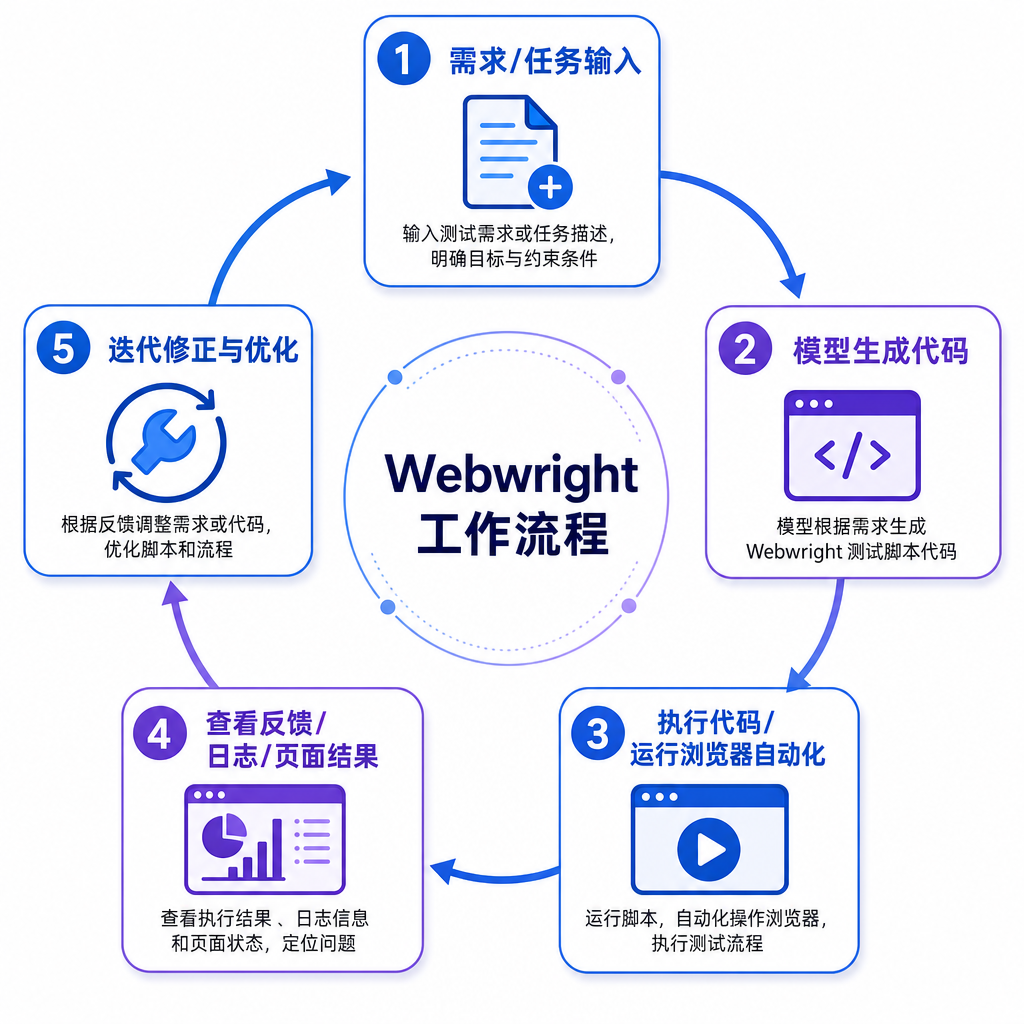
这种方式的优势很明显。代码天然适合表达多步逻辑,循环、函数、抽象这些编程基本功都能用上。填表单?写个循环遍历字段。日期选择?调用日期选择器的 API。跨页面操作?函数封装复用。相比一次只能预测一个低级动作,代码方式的表达能力强太多。
架构简洁,三个组件搞定
Webwright 的架构出人意料地简单:Runner(约 150 行)、Model Endpoint(约 550 行)、终端环境(约 300 行),总共约 1000 行代码。没有多智能体编排,没有复杂的分层规划,就是最直接的"模型 - 环境"交互循环。
执行流程也很直白:
- Runner 把当前上下文发给模型
- 模型返回思考过程和一条 shell 命令
- 环境执行命令,返回终端输出、日志、截图或错误栈
- 进入下一轮
这种设计哲学跟当下流行的"堆智能体、加规划层"完全相反。微软的选择是:与其搞复杂架构,不如让模型直接面对真实的开发环境,用代码这种更强大的表达方式解决问题。从结果看,这个选择是对的。
两个工程问题的巧妙解法
简单不代表粗糙。团队重点解决了两个实际工程问题,解法都很聪明。
第一个是"过早宣告完成"。模型有时候任务还没真正做完就说"搞定了",这在自动化场景里是大忌。Webwright 的做法是加一个门控步骤:模型必须先生成一份自检配置,然后在全新文件夹里运行最终脚本,结合日志和截图进行自我反思,判断到底成功还是失败,之后才能输出完成标记。
这个设计强制模型对自己的工作负责。不是说完"done"就完事,得拿出证据证明任务确实完成了。这种自验证机制在生产环境里特别重要——你不会想要一个自以为完成了任务、实际上啥都没干对的智能体。
第二个是上下文膨胀。长轨迹任务的编码很容易超出上下文限制,尤其是包含大量日志、截图、错误信息的时候。Webwright 每 20 步会把历史压缩成一份摘要,保留关键信息,丢弃冗余细节。这个策略在保持上下文连贯性和控制 token 消耗之间找到了平衡点。
基准测试:两个榜单都是第一梯队
Webwright 在两个主流基准上都交出了强劲成绩。
Online-Mind2Web 包含 300 个任务,覆盖 136 个常用网站。基于 GPT-5.4 的 Webwright 整体准确率 86.67%,在 100 步预算下位列公开配方前列。这个数据集更偏向单站点、中等复杂度的任务,Webwright 的高准确率说明它在常规场景下很稳。
Odysseys 才是真正的硬骨头。任务指令平均 272.3 个词,需要跨多个网站完成长链路操作。这种任务对智能体的规划能力、上下文理解、错误恢复都有极高要求。前面提到的 60.1% 成功率就是在这个基准上拿到的,比之前最好的 Opus 4.6(44.5%)高出 35.1%,比基础 GPT-5.4(33.5%)提升 81.49%。
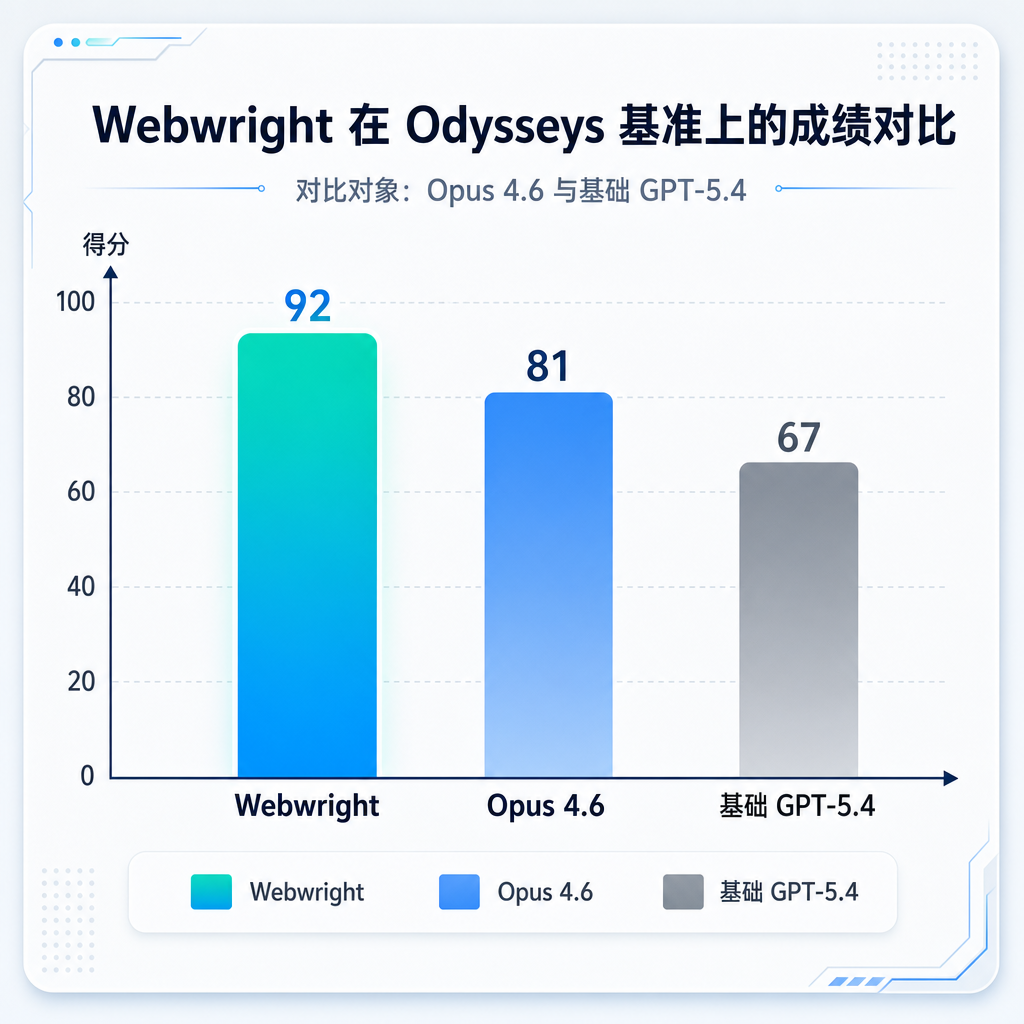
这个提升幅度不是调参调出来的,是架构选择带来的本质差异。代码方式在处理复杂多步任务时的优势,在 Odysseys 这种场景下体现得淋漓尽致。
代码方式的深层优势
为什么写代码比预测点击强这么多?除了前面提到的表达能力,还有几个深层原因。
可调试性。代码是可读的、可检查的。出了问题,看日志、看错误栈、看中间状态,定位问题比分析点击序列直观太多。模型也能利用这些信息快速定位并修正错误,而不是在黑盒里瞎猜。
可复用性。写过的函数、封装好的逻辑可以在后续步骤中复用。这种抽象能力是点击序列完全不具备的。想象一个需要在多个页面重复相同操作的任务,代码方式写一次函数就行,点击方式得每次重新预测。
与开发者工具链的天然契合。Playwright、Puppeteer 这些工具本来就是给开发者用的,文档完善、社区成熟、最佳实践清晰。模型用这些工具,等于站在了整个前端自动化生态的肩膀上。相比之下,预测点击是在重新发明轮子。
更容易验证和测试。代码可以单独运行、单元测试、集成测试。Webwright 的自检机制就是利用了这一点。而点击序列的验证只能端到端跑一遍,出错了也不知道哪一步有问题。
对网页智能体的启示
Webwright 的成功给整个网页智能体领域带来几个重要启示。
第一,不要低估代码的力量。AI 社区有时候过于追求"端到端学习",觉得让模型直接预测动作更"纯粹"。但实际上,利用现有的强大工具(比如浏览器自动化库)往往是更明智的选择。代码是人类几十年积累下来的最佳实践,没必要让 AI 从零开始学。
第二,简单架构可能更有效。Webwright 只有 1000 行代码,没有复杂的多智能体系统,没有精心设计的规划层,但效果比很多复杂系统都好。这说明在某些场景下,直接让强大的模型面对问题,给它合适的工具,可能比搭建复杂架构更有效。
第三,自验证机制很关键。"过早宣告完成"是所有自动化系统的通病,Webwright 的门控自检设计提供了一个可行的解决方案。这个思路可以推广到其他类型的智能体系统。
第四,上下文管理需要精细设计。长轨迹任务必然面临上下文膨胀问题,Webwright 的定期压缩策略是一个实用的工程方案。随着任务复杂度提升,如何在保留关键信息和控制 token 消耗之间平衡,会是所有智能体系统都要面对的挑战。
局限与未来方向
Webwright 也不是完美的。代码方式要求模型对 Playwright API 有足够了解,这对模型的代码能力有一定要求。虽然 GPT-5.4 这个级别的模型没问题,但小模型可能搞不定。
另外,Webwright 目前主要针对功能性任务(填表单、点击按钮、提取信息),对于需要视觉理解的任务(比如"点击页面上最大的红色按钮")可能不如视觉模型 + 点击预测的方式直接。不过这不是架构问题,加入视觉模块就能解决。
从论文透露的信息看,团队后续可能会探索几个方向:一是支持更多浏览器自动化工具,不局限于 Playwright;二是优化上下文压缩策略,在更长的任务轨迹上保持性能;三是研究如何让小模型也能用好代码方式,降低算力门槛。
开源意味着什么
微软选择开源 Webwright,对社区来说是个好消息。代码已经在 GitHub 上,开发者可以直接用,也可以基于它做定制开发。
更重要的是,Webwright 提供了一个清晰的参考实现。1000 行代码的规模意味着任何有一定工程能力的团队都能读懂、修改、扩展。相比那些动辄几万行、依赖一堆内部工具的项目,Webwright 的学习曲线要平缓得多。
对于想做网页自动化的团队,Webwright 是个很好的起点。它证明了代码方式的可行性,提供了工程上的最佳实践,也暴露了需要注意的坑(比如过早完成、上下文膨胀)。站在这个基础上,针对具体场景做优化,比从零开始摸索要快得多。
与其他方案的对比
Webwright 不是第一个做网页智能体的项目,但它的定位很独特。
与 OpenAI Operator 对比:Operator 是闭源的,走的是视觉模型 + 点击预测路线。Webwright 开源、用代码方式,两者技术路线完全不同。从公开数据看,Webwright + GPT-5.4 在某些任务上的成功率(60.1%)确实超过了 Operator 早期版本的表现,但 Operator 在视觉理解任务上可能有优势。
与 AutoGPT、BabyAGI 等通用智能体框架对比:那些框架追求通用性,什么任务都想做。Webwright 专注网页自动化,架构针对这个场景深度优化。专注带来的好处是性能更强、工程更简洁。
与传统 RPA 工具对比:UiPath、Automation Anywhere 这些 RPA 工具需要人工录制流程或写规则。Webwright 是 AI 驱动的,给自然语言指令就能执行,灵活性高得多。但 RPA 工具在稳定性、企业级功能上更成熟,各有优势。
实际应用场景
Webwright 这种框架能用在哪?几个明显的方向:
自动化测试。让 AI 根据测试用例描述自动生成 E2E 测试脚本,比人工写测试快多了。而且 AI 能覆盖更多边界情况,测试覆盖率更高。
数据采集。需要从多个网站抓数据?给 Webwright 一个任务描述,它自己写爬虫、处理分页、提取信息。比传统爬虫灵活,网站结构变了也能自适应。
业务流程自动化。很多企业有大量重复性的网页操作任务(录入数据、生成报表、跨系统同步信息)。Webwright 可以把这些任务自动化,而且不需要专门的 RPA 工程师,业务人员用自然语言描述需求就行。
辅助开发。开发者可以让 Webwright 帮忙写一些重复性的前端交互代码,或者快速验证某个交互流程是否可行。相当于一个会写浏览器自动化脚本的 AI 助手。
技术债与工程实践
从 Webwright 的设计能看出微软团队的工程素养。几个细节值得注意:
错误处理。环境执行命令后会返回完整的错误栈,模型能根据错误信息精确定位问题。这比只返回"失败"要有用得多。
日志管理。每一步的终端输出、日志都会保留,模型可以回溯查看。这对调试长轨迹任务至关重要。
截图机制。关键步骤会自动截图,模型能通过视觉信息验证操作结果。这在处理动态内容、异步加载时特别有用。
隔离执行。自检阶段在全新文件夹里运行脚本,避免污染主环境。这种隔离思想在生产系统里是基本要求。
这些细节单独看不起眼,但组合起来就是一个可靠的工程系统和一个 demo 的区别。
对 AI 编码能力的要求
Webwright 的成功很大程度上依赖模型的代码能力。GPT-5.4 能写出正确的 Playwright 代码、理解错误信息、快速修正问题,这些能力缺一不可。
这也解释了为什么 Webwright 在 GPT-5.4 上效果这么好。GPT-5 系列在代码理解和生成上有质的提升,特别是对 API 文档的理解、对错误栈的分析、对边界情况的处理。这些能力在 Webwright 这种场景下被充分发挥出来。
反过来说,Webwright 也是检验模型代码能力的好基准。一个模型在 Webwright 上的表现,直接反映了它写代码、调试代码、理解工具文档的综合能力。这比单纯的代码补全或算法题更接近真实开发场景。
行业影响
Webwright 的开源可能会推动网页智能体领域的一波创新。代码方式被证明可行后,会有更多团队尝试这个方向,针对不同场景做优化。
浏览器自动化工具的开发者也会受益。Playwright、Puppeteer 这些工具原本是给人类开发者用的,现在 AI 也成了用户。工具开发者可能会针对 AI 使用场景做优化,比如更清晰的错误信息、更友好的 API 设计、更完善的文档。
对企业来说,Webwright 降低了部署网页自动化的门槛。不需要专门的 RPA 团队,不需要复杂的流程设计,给 AI 一个任务描述就能跑起来。这可能会加速企业数字化转型,特别是在中小企业。
结语
Webwright 用 1000 行代码证明了一件事:在网页自动化这个场景下,让 AI 写代码比预测点击更有效。这个结论看似简单,但背后是对问题本质的深刻理解和工程实践的精心打磨。
微软选择开源这个项目,给社区提供了一个高质量的参考实现。对于想做网页智能体的团队,Webwright 是个很好的起点;对于研究者,它提供了新的思路和基准;对于开发者,它是一个实用的自动化工具。
AI 编码能力的提升,正在改变我们构建自动化系统的方式。Webwright 只是一个开始,未来会有更多场景被代码方式的智能体攻克。这个方向值得持续关注。
参考资料
- 约 1000 行代码搭起网页 AI 智能体:微软 Webwright 让 GPT-5.4 跑分提升 81% - IT之家对 Webwright 框架的详细报道,包含架构设计和基准测试数据
- Webwright GitHub 仓库 - 微软研究院开源的 Webwright 完整代码(搜索 "microsoft webwright" 可找到)
- Playwright 官方文档 - 微软开发的浏览器自动化库,Webwright 的核心依赖