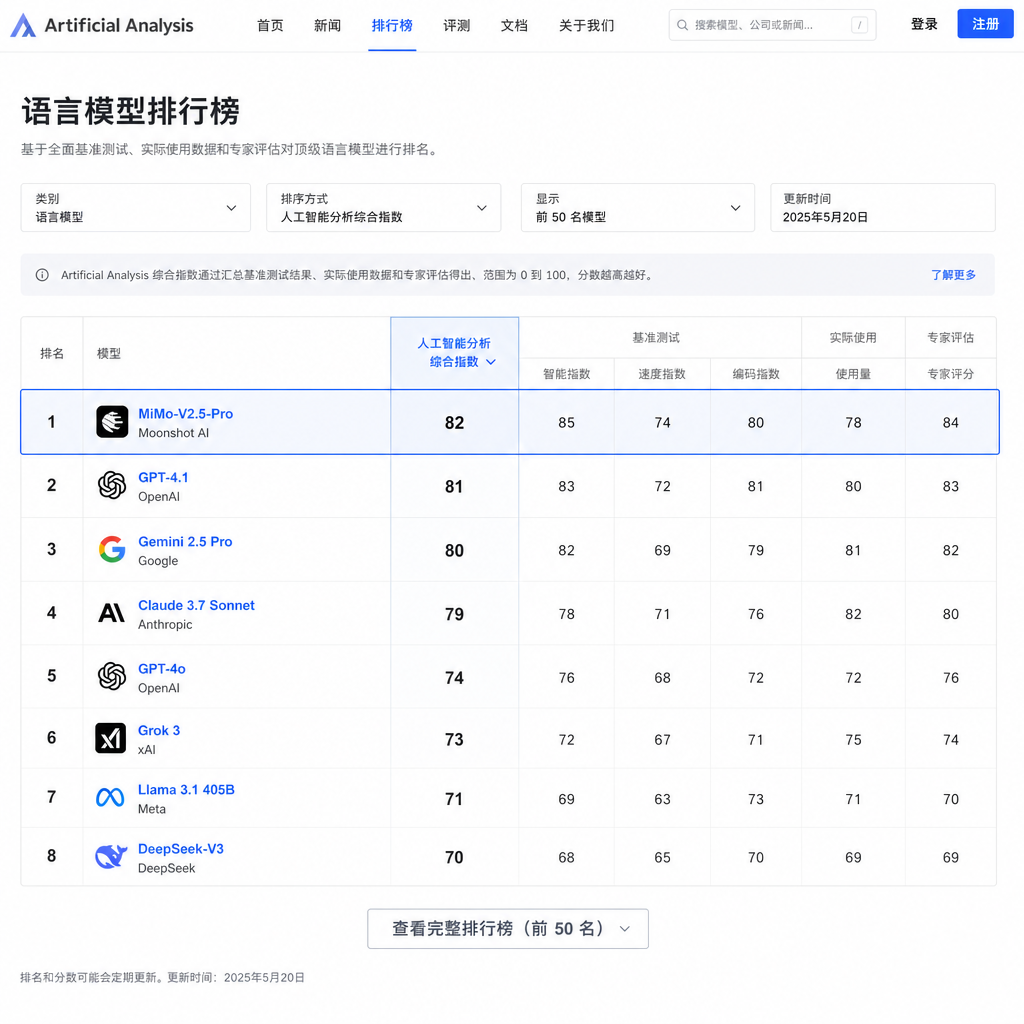
小米 MiMo-V2.5-Pro 登顶全球开源榜首
小米今天(5 月 26 日)发布的 2026 年第一季度财报里,藏着一个更值得关注的信号:它的基座大模型 MiMo-V2.5-Pro 在 Artificial Analysis 的智能指数和 Agent 指数双榜上,拿下了全球开源模型并列第一。
这不是小米第一次在 AI 上砸钱——财报显示,Q1 研发投入 90 亿元,同比增长 33.4%,今年 AI 领域至少投入 160 亿元,未来三年超 600 亿元。但这次不一样的是,钱砸出了实打实的排名。
双榜登顶,但更关键的是 Agent 能力
Artificial Analysis 是业内公认比较硬的第三方评测平台,它的智能指数综合了推理、代码、数学等多维度能力,Agent 指数则专门衡量模型在复杂任务中的自主决策和工具调用能力。MiMo-V2.5-Pro 能在这两个榜上同时登顶,说明它不是靠某个单项刷分上来的。
对比一下就知道这个位置有多难拿:Claude Opus 4.6、GPT-5.4 这些闭源顶模在 Agent 能力上一直是标杆,开源模型要追上它们,不只是参数量和训练数据的问题,更考验模型架构设计和对齐策略。小米这次能跟它们「坐在一张桌子上吃饭」,至少证明国产开源模型在 Agent 这条赛道上已经不是陪跑了。
更直接的验证来自 OpenRouter 平台的数据:MiMo-V2-Pro(注意这里是 V2-Pro,不是最新的 V2.5-Pro)在同一周以 30%+ 的市占率登顶周榜第一,周调用量达到 4.82 万亿 Token,终结了 Minimax 的连续榜首纪录。这个调用量不是刷出来的——开发者用脚投票,选的是真正能干活的模型。
MiMo-V2.5 系列:四款模型,两条路线
小米这次发布的 MiMo-V2.5 系列包含四款模型:
- MiMo-V2.5-Pro:旗舰模型,主打通用智能体能力、复杂软件工程和长程任务,对标 Claude Opus 4.6 和 GPT-5.4
- MiMo-V2.5:原生多模态模型,支持视觉和音频理解,在智能体性能上超越上一代 MiMo-V2-Pro,支持 100 万 Token 上下文
- MiMo-V2.5-TTS Series:语音合成模型
- MiMo-V2.5-ASR:语音识别模型
其中 MiMo-V2.5-Pro 和 MiMo-V2.5 已经全球开源。这个开源策略值得说一下:小米没有像很多厂商那样只开源「阉割版」,而是把最强的 Pro 版本直接放出来。这要么是真的有信心,要么是想通过开源快速占领开发者生态——从目前的调用量数据看,后者的效果已经显现了。
技术细节:省 Token 就是省钱
MiMo-V2.5-Pro 相比月之暗面的 Kimi K2.6 节省了 42% Token,MiMo-V2.5 相比 Meta 的 Muse Spark 节省 50% Token。这个数据看起来是技术指标,但对开发者来说就是真金白银。
举个例子:如果你用 MiMo-V2.5-Pro 处理一个 100 万 Token 的长文档分析任务,相比 Kimi K2.6 能省下 42 万 Token 的成本。按照目前主流 API 的定价(输入 Token 大约 0.01-0.03 元/千 Token),单次任务就能省几块到十几块钱。对于高频调用的企业应用来说,一个月下来省的钱可能比模型本身的订阅费还多。
这背后是模型压缩和推理优化技术的进步。小米没有公开具体的技术细节,但从结果推测,可能在以下几个方向做了工作:
- 更高效的 Tokenizer:通过改进分词算法,用更少的 Token 表达相同的语义
- 动态上下文裁剪:在保证任务完成质量的前提下,智能识别并丢弃冗余上下文
- 推理时优化:通过 KV Cache 复用、Speculative Decoding 等技术减少实际计算量
定价调整:取消复杂计费,直接降价
小米同时调整了 MiMo Token Plan 的计费方式:
- 取消「1 Token = 4 Credits」的换算,直接按 Token 计费
- 不再区分 256k 和 1M 上下文窗口的 Credit 倍率
- 连续月费订阅:现有用户开通自动续费后次月 7 折,新用户次月 77 折
- 年费订阅:一次性订阅全年 88 折,最高可减 948.96 元
这个调整看起来是简化计费,实际上是在降价。之前很多用户抱怨大模型的计费方式太复杂——不同上下文长度不同价格、输入输出 Token 分开计费、还要换算成 Credits——现在直接按 Token 算,开发者能更清楚地预估成本。
对比一下主流模型的定价(以 100 万 Token 输入为例):
- GPT-5.4:约 30-50 元(根据上下文长度浮动)
- Claude Opus 4.6:约 45-60 元
- Kimi K2.6:约 20-35 元
- MiMo-V2.5-Pro:约 15-25 元(开源版本免费,API 调用收费)
小米的定价策略很明确:用价格优势抢市场份额。这在开源模型里是常见打法,但能做到性能不输闭源顶模的同时还便宜一半,就不只是价格战了。
罗福莉和她的 36 天迭代周期
值得一提的是,MiMo 大模型的负责人罗福莉是 DeepSeek 前核心成员,业内称她为「天才少女」。从上次发布 MiMo-V2 系列到这次 V2.5 系列,只过了 36 天。
这个迭代速度在大模型领域算是非常激进的。通常来说,一个主版本的迭代周期至少要 2-3 个月,因为需要重新训练、对齐、评测、修 bug。36 天能出一个新版本,要么是团队规模和算力投入足够大,要么是在架构设计上做了模块化,可以快速替换和升级某些组件。
罗福莉之前说过,「当未来模型足够稳定后将会开源」。现在 MiMo-V2.5-Pro 开源了,说明小米认为这个版本已经达到了可以大规模使用的稳定性。这对开发者来说是好消息——不用担心用着用着模型就不维护了。
MiMo-V2.5 的多模态能力:不只是看图说话
MiMo-V2.5(非 Pro 版本)主打原生多模态能力,支持视觉和音频理解。这里的「原生」很关键——不是把图像编码器和语言模型拼起来,而是从预训练阶段就让模型学会跨模态推理。
具体来说,MiMo-V2.5 能做到:
- 视觉理解:不只是识别图片里有什么,还能理解图片中的空间关系、因果关系、时间序列(比如看一组连续截图推断操作流程)
- 音频理解:识别语音内容、说话人情绪、背景音效,甚至能根据音频推断场景(比如听到键盘声和鼠标点击声,推断用户在编程)
- 跨模态推理:给一张产品设计图和一段用户反馈录音,模型能综合两者给出改进建议
这种能力在 Agent 场景下特别有用。比如你让 Agent 帮你调试一个前端页面,它不仅能看代码,还能看浏览器截图,理解实际渲染效果和预期效果的差异,然后给出修改方案。这比纯文本交互的模型要高效得多。
中国模型的调用量已经连续五周超过美国
OpenRouter 平台的数据显示,中国模型的总调用量已经连续五周超过美国。这个趋势在今年 Q1 开始显现,到现在已经比较稳定了。
背后的原因有几个:
- 性价比优势:中国模型普遍比美国模型便宜 30-50%,在性能接近的情况下,开发者自然选便宜的
- 本地化支持:中文理解、中国特色场景(比如电商、短视频、社交媒体)的处理能力更强
- API 稳定性:国内模型的 API 服务在中国大陆的访问速度和稳定性明显好于海外服务
- 合规性:对于需要数据本地化存储的企业应用,用国内模型更容易满足合规要求
小米 MiMo 系列在这个趋势中扮演了重要角色。从 MiMo-V2-Pro 登顶 OpenRouter 周榜就能看出,它不是靠低价倾销抢市场,而是真的有开发者愿意用、用得好。
Hermes Agent:第一贡献模型
财报里还提到,Xiaomi MiMo 大模型助力 Hermes Agent 登顶全球调用量榜首,成为第一贡献模型。Hermes Agent 是一个开源的 AI Agent 框架,支持多模型接入,开发者可以用它快速搭建自己的 Agent 应用。
MiMo 能成为 Hermes Agent 的第一贡献模型,说明两件事:
- Agent 能力确实强:Hermes Agent 的开发者和用户选择 MiMo,是因为它在实际任务中的表现最好
- 生态整合能力:小米不只是做模型,还在积极参与开源生态,跟主流 Agent 框架深度整合
这对小米来说是个正向循环:模型好 → 开发者用 → 反馈数据多 → 模型迭代快 → 模型更好。DeepSeek 就是靠这个循环起来的,小米现在也在走这条路。
开源模型的商业化困境
小米这次开源 MiMo-V2.5-Pro,看起来很大方,但开源模型的商业化一直是个难题。Meta 开源 Llama 系列,主要是为了推广自己的 AI 基础设施和开发工具;Mistral 开源模型,但核心收入来自企业定制服务和私有部署。
小米的商业化路径可能有几个方向:
- API 服务:开源模型免费,但 API 调用收费。这是最直接的变现方式,也是目前主流做法
- 硬件绑定:在小米手机、IoT 设备上预装 MiMo 模型,提供端侧 AI 能力。这能增强硬件产品的竞争力
- 企业服务:为企业提供私有部署、模型微调、定制开发等服务。这块的利润率比 API 服务高得多
- 生态分成:通过 MiMo 模型构建的应用生态,小米可以从中抽成(类似苹果 App Store 的模式)
从财报披露的「未来三年 AI 投入超 600 亿元」来看,小米短期内不指望 AI 业务盈利,更多是在抢占市场份额和技术高地。这个打法跟当年小米做手机时的「硬件不赚钱,靠服务和生态赚钱」如出一辙。
对开发者意味着什么
如果你是开发者,MiMo-V2.5-Pro 登顶这件事对你有几个实际影响:
- 多了一个靠谱的开源选择:之前开源模型里能打的不多,Llama 3.3、Qwen 2.5、DeepSeek-V3 算是第一梯队,现在 MiMo-V2.5-Pro 也进来了
- Agent 应用的成本降低了:如果你在做 Agent 相关的项目,MiMo-V2.5-Pro 的性价比值得考虑。尤其是需要长上下文和复杂推理的场景
- 多模态能力更容易获取:MiMo-V2.5 的原生多模态能力,比自己拼接图像模型和语言模型要省事得多
- 国内 API 服务更稳定:如果你的用户主要在中国大陆,用国内模型的 API 延迟和稳定性会好很多
当然,也要注意一些潜在问题:
- 开源协议:小米没有公开 MiMo-V2.5-Pro 的开源协议细节,如果是商用需要确认授权条款
- 模型稳定性:36 天迭代一个版本,说明模型还在快速演进中,API 接口和行为可能会有变化
- 社区生态:相比 Llama 和 Qwen,MiMo 的社区生态还比较薄弱,遇到问题可能不太好找解决方案
国产大模型的新阶段
MiMo-V2.5-Pro 登顶全球开源榜首,标志着国产大模型进入了一个新阶段:不再是「追赶」,而是「并跑」甚至「领跑」。
回顾一下这两年的进展:
- 2024 年初,国产模型还在追 GPT-4 的尾巴
- 2024 年中,DeepSeek-V2 出来,证明国产模型在某些维度上能跟 GPT-4 打平
- 2024 年底,Qwen 2.5、DeepSeek-V3 发布,国产模型在开源领域已经是第一梯队
- 2025 年,Claude Opus 4.6、GPT-5 发布,把闭源模型的天花板又抬高了一截
- 2026 年 Q1,小米 MiMo-V2.5-Pro 登顶开源榜首,证明国产模型在 Agent 能力上已经能跟顶级闭源模型正面较量
这个进展速度是惊人的。两年前,大家还在讨论「中国大模型什么时候能追上 GPT-3.5」,现在已经在讨论「开源模型什么时候能全面超越闭源模型」了。
但也要看到,闭源模型的优势依然明显:
- 综合能力:GPT-5、Claude Opus 4.6 在各个维度上都很均衡,没有明显短板
- 稳定性:闭源模型的 API 服务更成熟,SLA 保障更好
- 安全性:在内容安全、对齐、防越狱等方面,闭源模型做得更细致
- 生态:OpenAI、Anthropic 的开发者生态更完善,工具链更丰富
开源模型要全面超越闭源模型,还有很长的路要走。但至少在某些细分领域(比如 Agent、长上下文、多模态),开源模型已经证明了自己的实力。
小米的 AI 野心
从财报数据看,小米对 AI 的投入是认真的:今年 160 亿元,未来三年超 600 亿元。这个投入规模在国内科技公司里算是第一梯队了(阿里、腾讯、字节的 AI 投入可能更大,但没有公开具体数字)。
小米做 AI 有几个天然优势:
- 硬件生态:小米有手机、IoT 设备、汽车等硬件产品线,AI 能力可以直接落地到产品上
- 用户规模:小米的全球用户超过 6 亿,这些用户产生的数据是训练模型的宝贵资源
- 场景丰富:从智能家居到智能驾驶,小米的业务场景覆盖了 AI 应用的大部分领域
- 工程能力:小米的软件工程团队一直很强,做 AI 需要的工程化能力(数据处理、模型训练、推理优化、服务部署)都不缺
但小米也有明显的短板:
- 算力:相比阿里、腾讯、字节,小米的自有算力规模较小,需要依赖云服务商
- AI 人才:虽然挖来了罗福莉这样的顶尖人才,但整体 AI 团队的规模和深度还不如 BAT
- 数据质量:小米的用户数据主要来自硬件设备,在互联网内容数据(文本、图片、视频)上不如内容平台
小米的策略是扬长避短:用开源模型快速占领开发者生态,用硬件产品落地 AI 能力,用价格优势抢市场份额。这个策略能不能成功,还要看后续的执行。
写在最后
MiMo-V2.5-Pro 登顶全球开源榜首,是国产大模型的一个里程碑,但不是终点。大模型的竞争才刚刚开始,技术迭代速度快到让人眼花缭乱。
对开发者来说,这是个好时代:有越来越多性能强、价格低、易获取的模型可以选择。但也是个焦虑的时代:模型更新太快,今天学会的技术明天可能就过时了。
小米这次的成绩值得肯定,但更值得关注的是它能不能持续迭代、持续领先。毕竟,大模型这个赛道上,没有人能躺在功劳簿上睡觉。36 天一个版本的迭代速度,既是优势,也是压力。
参考来源
- 小米集团:第一季度营收991.4亿元 - 36氪 - 小米 2026 Q1 财报官方数据
- 小米双模型正式开源!MiMo-V2.5-Pro无中断肝出"macOS" - 知乎 - MiMo-V2.5 系列技术细节和性能对比